ML及DL学习基础
1.AI、ML、DL关系

三者关系可以用上面这张图来完整概括。深度学习的范围最小,其次是机器学习,人工智能的范围最大。
2.主要学习内容

2.1一些基础知识
- 数学基础:微积分与概率论、数理统计、矩阵与线性代数、凸优化、数值计算。这里面我只接触了前三个,后面两个还没有接触,由于数学建模国赛,暑假会自学数值计算。
- 编程工具基础:数据结构与算法、Python、sklearn、Pytorch/Tensorflow。数据结构接触了很多,Python对数据的处理方面还不是很熟悉,sklearn也仅仅限于前面学习的那部分内容,深度学习框架打算专心用Pytorch。
2.2监督学习
所谓监督学习(Supervised learning),是指利用一组已知类别的样本调整分类 or 回归的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习可以理解为学生从老师那里获取知识、信息,老师提供对错指示、告知最终答案。 学生在学习过程中借助老师的提示获得经验、技能,最后对没有学习过的问题也可以做出正确解答。“老师提供对错指示”这句话很关键,它告诉我们:我们的训练样本,都是有“标准答案的”,比如分类,你在训练的时候就已经知道了它的正确类别,比如回归,你在训练的时候同样也提前知道了真实值。
监督学习要实现的目标是“对于输入数据X能预测变量Y”。这个预测可以是分类,也可以是具体的一个数值。
监督学习主要包括:
- 线性模型
- 贝叶斯(朴素贝叶斯和贝叶斯网络)
- SVM&SVR
- 决策树与随机森林、GBDT、XGboost、Adaboost
- 逻辑回归与最大熵模型
- K近邻与Manifold Learning(流形学习)
- 概率图模型、HMM、CRF
- EM
- 神经网络
前面已经大致学习了机器学习之linear_model(普通最小二乘法)、机器学习之linear_model(Ridge Regression)、概率生成模型(Probabilistic Generative Model)与朴素贝叶斯(Naive Bayes)、机器学习之逻辑回归(logistics regression)、机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析、决策树与随机森林(从入门到精通)、机器学习之Ensemble(一些推导与理解)、最简单的分类算法之一:KNN(原理解析+代码实现)
对于深度神经网络,可以分为:
- 前馈神经网络
- CNN(卷积神经网络)
- RNN(循环神经网络)
- 自编码器
- 深度信念网络
- 深度生成模型
- 当前的一些研究热点:GAN(生成对抗网络)深度强化学习(Deep Reinforcement Learning)、Attention(注意力机制)、迁移学习(Transfer Learning)…
DL也才刚刚入门,就看了一些比较基础的概念:反向传播算法(Backpropagation)----Gradient Descent的推导过程、Deep Learning中的一些Tips详解(RELU+Maxout+Adam+Dropout)。
2.3无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。(百度百科)
简而言之,无监督学习的样本是没有标记的,无监督学习的最典型代表就是聚类。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。
无监督学习(Unsupervised Learning) 分为以下几种:
- 聚类
- SVD(奇异值分解)
- PCA(主成分分析法)
- LSA(潜在语义分析)
- PLSA(概率潜在语义分析)
- 马尔科夫链蒙特卡罗方法
- LDA(隐含狄利克雷分布)
- Page Rank
无监督学习到目前为止只是接触了机器学习之K_means(附简单手写代码)以及一点点的PCA。
3.基本概念
- 样本Sample
- 数据集Data Set(训练集Training Set、测试集Test Set、验证集Validation Set)
- 特征Feature
- 特征向量Feature Vector
- 独立同分布Identically and Independently Distributed, IID
以上最基本的一些概念前期学习基本都接触过,就不再详述了。
机器学习的一些概念:
3.1模型

所谓的机器学习模型,本质上是一个函数,其作用是实现从一个样本
到样本的标记值
的映射,即
。
3.2学习准则

学习目标就是选择期望风险最小的模型。
3.3 损失函数
损失函数在SVM里面有细讲过,这里就再搬过来了:
在下面的问题中loss代表每一个样本的损失,Loss代表总的损失。
首先我们需要回顾一下前面所学的二分类问题:假设有一批样本,
,
,
,…,
,对应的label分别是:
,
,
,…,
,
(i=1,2,…,n)有两个取值,-1和1,则Binary Classfication:
if f(x)>0,output=1,属于一个class
if(f(x)<0),output=-1,属于另一个class
在二分类问题中loss function的定义有很多种,其中最理想的loss function定义为:

即若分类正确loss=0,否则loss等于1,那么在这里Loss可以理解分类器在训练集上犯错误的次数。but如果Loss这样定义,是不能求微分的,所以我们换了一种方式,即:

我们以 作为横轴,loss作为纵轴,从二分类的定义来看,当f(x)>0时,output=1,即 时,f(x)是越大越好的,同理,当 时,f(x)是越小越好。 因此,当 越大时,loss会越小。 这是我们判断一个loss function好坏的标准。
针对上面这个表达式,我们有以下几种情况可以讨论(加上ideal loss):
-
ideal loss
定义:
这个loss比较好理解,可以直接画出图像:
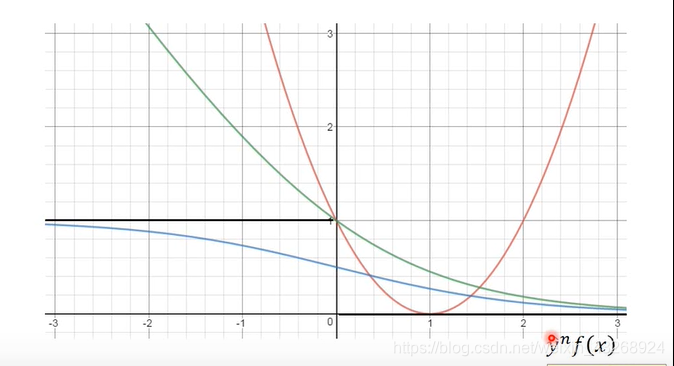
如图中黑线所示,当 >0时,表面分类正确,loss=0,否则等于1。从其图像我们也可以看出,loss是不能进行Gradient Descent的。 -
Square loss
Square loss是用使用MSE来衡量误差,若output=1时,f(x)应该尽量接近1而当output=-1时,f(x)又应该尽量接近于-1,只有这样Square loss才能最小。因此我们可以定义 :

可以看出,该表达式是满足MSE定义的,我们画出 的图像,如下所图红线示: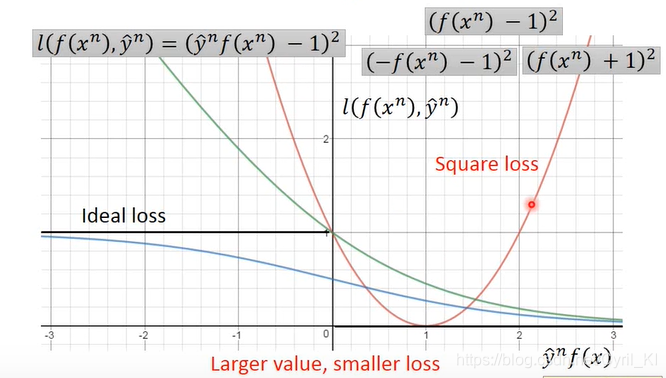
前面我们讨论过,当 越大时,loss应当会越小。 但是Square loss显然是不符合情况的,这里也可以进一步解释前面我们为什么说不能用Square loss来作为损失函数。 -
Sigmoid+Square loss
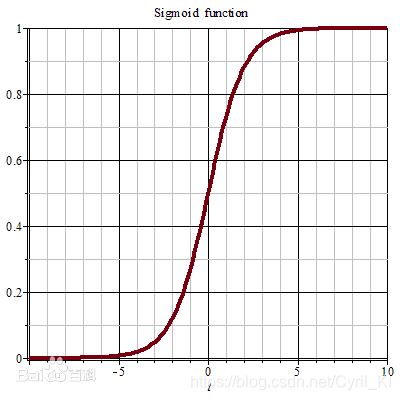
Sigmoid函数值域介于01之间,因此当output=1时, 应该尽量接近1,而当output=-1时, 又应该接近于0,因为其本质还是Square loss,只不过把输出映射到了01之间,因此,我们可以定义

同样画出图像: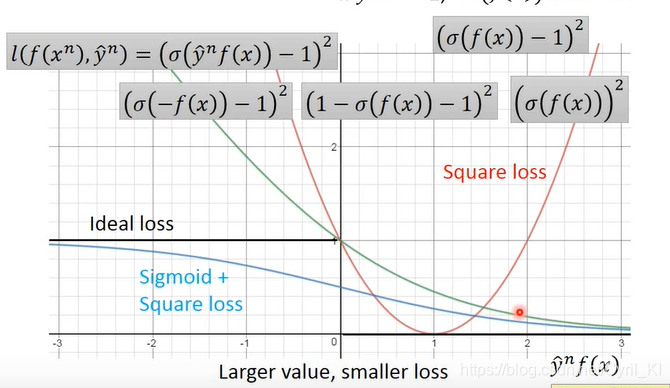
从目前来看,该损失函数好像挺合理的,但仔细一想又是不对的。该函数的渐近线是y=1,越往左loss是越大的,但是其斜率是越来越小的。在Gradient Descent中,如果一个位置的loss太大那么它应该更加快速的下降以找到最优解,但是上述函数不符合要求,loss越大下降反而越慢,属于典型的“没有回报,不想努力。” -
Sigmoid+Cross entropy
在逻辑回归中我们最终选择了交叉熵的形式,这里定义

画出图像: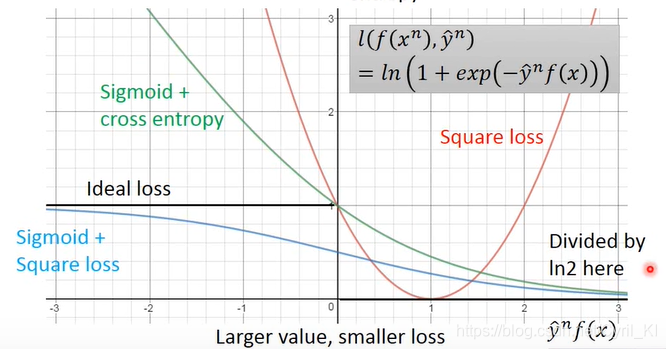
可以看出,从左到右符合下降的趋势,并且相较与Sigmoid+Square loss,Sigmoid+Cross entropy的loss越大,其梯度越大,情况符合“有回报有努力。” -
Hinge loss
定义为:

从表达式可以看出,当 时, 则loss=0;当 时, 则loss=0。
同样画出图像:
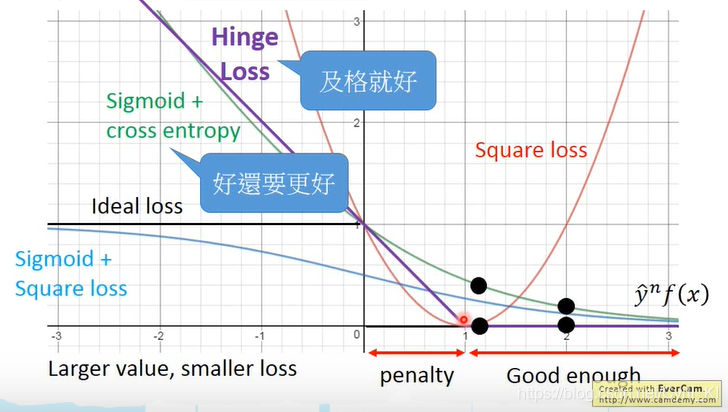
比较Hinge loss和Sigmoid+Cross entropy,比如说我们把黑点从1移动到2,可以发现Sigmoid+Cross entropy其实是可以做得更好的,而Hinge loss只要是 大于它的阈值,无论怎么调整loss都不会变。但是当我们有outlier也就是异常值的时候,Hinge loss会给出比Cross entropy更好的结果。
3.4 欠拟合与过拟合
- 所谓过拟合,是指模型学习能力过于强大,把训练样本中某些不太具有一般性的特征都学到了。例如判断一个人是否是好人,训练样本中所有好人都或多或少做过一些坏事,模型学到了这一特征,把这一模型运用到了实际预测中去,这明显是有失偏颇的,因为一个人是否是好人理论上跟一个人是否做过坏事是不相关的。
- 所谓欠拟合,是指模型学习能力低下,连训练集中的数据都不能很好的拟合,比如说我要预测一个人是否是坏人,模型只考虑到了他是否做过坏事,这明显是考虑不全的,做过坏事不一定就是坏人,那么显然这种情况就是欠拟合。
3.5评价指标–分类问题

准确率很好理解,你有10个样本,分类正确五个那么正确率就是1/2,同样错误率也是1/2。

上面引入了真正例(TP)、假负例(FN)、假正例(FP)、真负(TN)例四个定义。
- True Positive :预测为正,实际也为正
- False Positive :预测为正,实际为负
- False Negative :预测与负、实际为正
- True Negative 预测为负、实际也为负
- 上面图片中的类别C表示正
由此引出查准率和查全率两个概念:

4.深入阅读
顶会:

顶刊:
