董长春
1097895173
15011003101
11天=7+4
什么是大数据?
海量数据及其处理方式
大数据(big data),IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》 [1] 中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
价值密度:单条数据实际的价值,所以在大数据环境中一般不重视事务的控制
10:15
开发工具:eclipse,IDEA,pycharm
10:18
大数据关键技术
1.数据获取民用
1.爬虫,java,python
2.历史数据,970PB,mysql,oracle,数据仓库(Hive)
3.用户日志收集,flume(分布式的日志收集工具),js埋点
2.数据清洗:将所有数据进行过滤,清除不需要的脏数据,留下需要的数据
1.逻辑清洗: if(user!=null){…}
2.sql清洗: select user_name from user where age>18;
3.数据存储
HDFS(Hive.Hbase.Spark…pig)
4.数据计算
离线计算,保存下来的数据就是离线数据:Mapreduce,Hive
在线计算,不断产生的数据就是在线数据(流式数据处理,实时处理):kafka(MQ),Flink(spark,storm)
京淘电商平台用户日志流量分析系统
公司电脑----扫地机器人
公司电脑—鼠标—登录—dongcc
dongcc 手机cookie 公司电脑 家用电脑
eclipse JDK maven encoding font 包视图
16:15上课
内存8以下 克隆一台虚拟机,1G
8克隆三台虚拟机,1G+512M+512M
12以上克隆三台虚拟机,2G+512M+512M
撰写栏
1.ssh-keygen + 三次回车
2.ssh-copy-id root@hadoop01 + yes + root
3.ssh-copy-id root@hadoop02 + yes + root
4.ssh-copy-id root@hadoop03 + yes + root
Hadoop:分布式的海量数据存储和离线处理平台
历史:
Google:搜索引擎-爬虫\全文检索\海量数据存储\处理
2004年(GFS) (海量数据计算模型) 2006年
doug cutting(狗哥): Nutch(爬虫),lucene,HDFS,Mapreduce.
apache
大数据技术最早的发源地:搜索引擎
Apache Hadoop软件库是一个框架
该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。
让程序员在分布式开发中只专注于业务的开发,不需要考虑分布式的集群调度.
它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。
在分布式环境中,每个机器节点贡献自己的存储单元和算力给Hadoop.Hadoop来统一调度.
Hadoop本身不用于依靠硬件来提供高可用性,而是设计用于检测和处理应用程序层的故障,即使集群中的每台机器都很容易出现故障,Hadoop也能够提供稳定的服务,也就是说Hadoop可以构建在廉价集群上
Hadoop包含五个模块,其中三个是重点:HDFS(存储)Mapreduce(计算)Yarn(资源管理)
同时,Hadoop也是一个生态圈,包括Hive Hbase ZK …
hadoop的版本:
1.x:1.0.0是apache开源的第一个版本:HDFS(存储)、Mapreduce(计算)
2.x:2.0.0是Hadoop目前为止最重要的一次升级。:HDFS、Mapreduce、Yarn(资源管理):
3.x:3.0.0,2017-12下旬发布,但是由于技术定位,更新内容目前为止没有收到市场的重视:HDFS、Mapreduce、Yarn(资源管理)
HDFS:海量数据的存储
纵向拓展
1.不能无限拓展
2.读写性能较差
3.安全性很差
4.成本增长不友好
横向拓展
1.理论上支持无限拓展
2.读写性能较高
3.安全性提升
4.成本增长呈线性
1.1 Hadoop的安装
- 单机模式:下载安装包,上传解压,即可.需要有JDK环境.不支持Yarn,HDFS,只支持Mapreduce的单元测试
- 伪分布式模式:使用一台机器的多进程来模拟集群环境,可以提供完整Hadoop的所有功能,缺点是性能比较差,适合学习阶段或者测试阶段.
- 完全分布式模式:生产级别环境.支持全节点的高可用.
//TODO
2 Flume
分布式的日志收集工具
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。
它具有简单的流式数据处理模型的特点。
它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。
它使用一个简单的可扩展数据模型,允许在线分析应用程序。
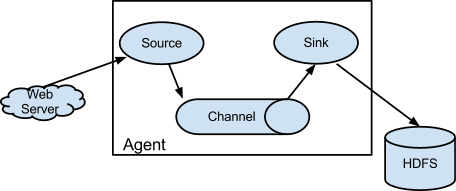
2.1 重要概念
- event:事件,flume在接受到日志数据之后.会先将其封装起来,封装的形式,叫做event.event实际上就是一个json串
{“headers”:info,“body”:日志本身} - agent:代理,在flume集群中,每个节点都叫做一个agent,agent代表了单个flume节点,接收,封装,承载,传输日志数据的整个过程.(包含三个模块,source,channel,sink)
- source:数据源,被动接收上游传来的数据,并进行封装,封装好的event输出到channel中进行缓存
- channel:缓存,被动接受source传来的数据,进行缓存,等待sink的消费.一般为了高效,使用内存资源来作为缓存,但是由于缓存接收和输出数据都是被动的所以,当sink失效时,内存占用空间会越来越大,出现侵占其他进程资源的情况甚至导致因资源匮乏而宕机.
- sink:指定数据的输出位置,并消费channel中缓存的数据,输出到指定位置,在flume中sink和channel应该意义对应.方式消费到的数据不是全量数据.
2.2 Flume的多级流动和扇入扇出
2.3 知识回顾
在flume的集群中,每一个节点叫做agent
每个agent中包含了flume工作的基本流程:source,channel,sink
Flume特点:灵活
1.source\channel\sink可以使用各种类型,能够接受各种类型的数据,也可以将数据输出到多种渠道,其中的缓存也支持不同资源来作为缓存空间.
2.结构包含多级流动扇入扇出这三种基本组合方式,并可以灵活应用,没有限制.模块化的模型非常灵活,这就像搭积木一样.
环境准备
- 确认Hadoop启动
jps查看进程

start-all.sh
如果没有成功(进程数不够)
1.stop-all.sh 停掉hadoop所有进程
2.删掉hadoop2.7.1下的tmp文件并重新创建tmp
3.hdfs namenode -format 重新初始化(出现successfully证明成功),如果配置文件报错,安装报错信息修改相应位置后重新执行第二步。
4.start-all.sh 启动hadoop
3 Hive
Hive是一个基于Hadoop的数据仓库工具,他的出现让海量数据离线处理变得简单,只需要通过我们熟悉的sql语法就能轻松实现大数据处理(清洗).内部提供了非常丰富的函数库,供程序员使用,当然也不可避免的会遇到内置函数不够用的情况.如果内置函数不能满足开发需求,hive还支持UDF(自定函数).非常灵活,学习成本低.收到广泛支持.
官方:Apache Hive™数据仓库软件有助于使用SQL读取,写入和管理驻留在HDFS中的大型数据集。可以将表结构投影到已经存储的数据上。提供了命令行工具和JDBC驱动程序以将用户连接到Hive。
3.1数据仓库
数据仓库:体积大,有用,但不常用的数据
数据仓库是一个面向主题的.稳定的.集成的.反应历史数据的数据存储系统,一般为管理者提供决策分析的数据支持.
3.2 hive和HDFS的存储关系
- Hive中的数据库在HDFS中以文件夹的形式保存在/user/hive/warehouse目录下.命名:数据库名.db
- Hive中的表在HDFS中以文件夹的方式保存在对应数据库目录下.
- Hive中的数据以文件的形式保存在HDFS中对应表目录下.
- Hive使用mysql(derby)来保存描述Hive数据库结构和HDFS文件目录之间关系的元数据,此时mysql被称为Hive的元数据库.
3.3 表的分类
3.3.1 内部表(托管表)和外部表
内部表(managedtable): 先有表后有数据,默认情况下,所有的内部表数据都会存放在HDFS/user/hive/warehouse目录下
create table tb_name (com1 int,com2 string) row format delimited fields terminated by '分隔符';
外部表(externaltable):先有数据后有表,数据是先与表出现,存储在HDFS中,使用hive创建外部表的时候,将表结构指向数据存放(location)
create external table tb_name (com1 int,com2 string) row format delimited fields terminated by '分隔符' location '数据存放目录';
通过后期上传文件到表目录中重新查询,可以看到新上传的数据.我们得知:hive在数据管理中,只会维护表的目录.至于表中有哪些文件.hive不会做具体的记录.
hive数据维护
1.进入hive命令行客户端
2.创建数据库:create database jtlogdb;
3.进入数据库:use jtlogdb;
4.创建flux表:create external table flux (url string,urlname string,title string,chset string,src string,col string,lg string, je string,ec string,fv string,cn string,ref string,uagent string,stat_uv string,stat_ss string,cip string) partitioned by (reportTime string) row format delimited fields terminated by ‘|’ location ‘/flux’;
5.添加分区:alter table flux add partition (reportTime=‘2020-07-11’) location ‘/flux/reportTime=2020-07-11’;
4 流式数据处理-kafka&Flink
4.1 kafka
kafka是一个MQ(消息队列)
ActiveMQ(6k)\RabbitMQ(1.2w)\RocketMQ(5w):适用于业务场景,能够保障数据安全
Kafka(25-50w)\ZeroMQ(25-50w):可能出现数据丢失,适合大数据业务,亿分之几
只有一种模式:发布/订阅
目前是大数据生产中最常用的MQ,也是社区最活跃的MQ
http://kafka.apache.org/documentation/#producerapi
4.2 流式数据处理框架比较
大数据计算框架的发展历程:
第一代: Mapreduce, 只能计算离线数据
第二代: Storm ,流式数据计算,特点:速度快 毫秒级
第三代: Spark, 支持离线数据计算(sqarksql),在线(sparkstreaming.,吞吐量高,但是时效性差,微批方式处理,不是真正意义上的流式处理,秒级)图计算(Mlib)
第四代: Flink,是真正意义上的流式数据处理框架,(结合了storm和spark两家的有点,时效性强的同时,吞吐量也可以很高)同时支持离线处理,
package cn.tedu;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
public class test {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Integer> source = env.fromElements(1, 2, 3, 4, 5);
source.map(new MapFunction<Integer, Integer>() {
public Integer map(Integer value) throws Exception {
return value*10;
}
}).print();
}
}
5 python
在python中函数和方法是有区别的
函数是独立存在的,只依附于模块,是一个有具体逻辑功能的代码块.
使用方式:函数名() eg: len(“12345”)
方法是依附于类或对象的.有类方法和实例方法.
使用方式: 对象名(类名).方法名()
python数据类型:
Number:直接赋值
String:""
list:[,]
tuple:(,)
dictionary:{k:v,k:v}
set:{,}