论文简介
论文名称:Classification of Android apps and malware using deep neural networks
作者:Robin Nix ; Jian Zhang
文章链接
发表期刊:2017 International Joint Conference on Neural Networks (IJCNN)
文章主要针对安卓移动平台的恶意软件检测。因此使用的方法主要是对系统API调用序列对Android应用程序进行分类,并为此目的研究深度神经网络(DNN)的有效性作者设计了卷积神经网络(CNN)进行序列分类,并进行了一系列恶意软件检测和软件归类为功能组的实验,以测试和比较CNN与基于递归神经网络(LSTM)和其他基于n-gram的方法的分类 。 CNN和LSTM均明显优于基于n-gram的方法。 文章发现,使用CNN的性能比LSTM效果好很多。
基础知识
- n-gram测试
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。文章在传统的序列分类上基于改进,设计了设计了模型包括:RNN和LSTM并与他们基于词袋进行比较。
-
Bag-of-words(BoW)模型
词袋模型BoW起始可以理解为一种直方图统计,开始是用于自然语言处理和信息检索中的一种简单的文档表示方法。 和histogram 类似,BoW也只是统计频率信息,并没有序列信息。而和histogram不同的是,histogram一般统计的某个区间的频数,BoW是选择words字典,然后统计字典中每个单词出现的次数。文章中分别使用了BoW模型以及n-gram测试进行API调用分类,并对RNN和LSTM并与他们基于词袋进行比较。DNN都大大优于BoW和基于n-gram的方法。尽管事实上LSTM是连续数据的自然选择,但最后发现CNN的性能明显更好,并且在所有测试方法中性能最佳。
-
API-call 分析
安卓apk文件包括:res文件夹,assets文件夹,classes.dex文件,AndroidManifest.xml文件,lib文件夹和META-INF文件夹。我们需要分析classes.dex和Androidmanifest.xml。
追踪器在跟踪apk的程序流的时候面对分支指令随机选择一条,面对dex调用指令直接追踪,基本上能覆盖apk中的大部分代码。
其中classes.dex是安卓apk文件的二进制文件,dex文件可以直接运行在dalvik虚拟机上进行编译。androidmanifest.xml是整个文件的根目录,往里面配置文件所需的权限,组件等内容。
- CNN构造和分类器模型
这里算法思路主要是利用了逻辑回归模型,使用relu进行优化,使用分类交叉熵之和作为损失来训练CNN。
最小化使用自适应梯度下降(ADAGard),其可以通过动态调整学习率α防止过拟合。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
- 预处理和插入CNN
首先限制api调用次数,增大精度
在设计CNN的时候,因为CNN要求输入的大小相同。将长度n分为分为若干序列S^(i)。n要求最佳长度为100~200个API调用。
在每个API调用的向量设计为独热编码,将其转换为n* m的矩阵作为API输入。n=独热编码数,m是API调用数。
- LSTM分类
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
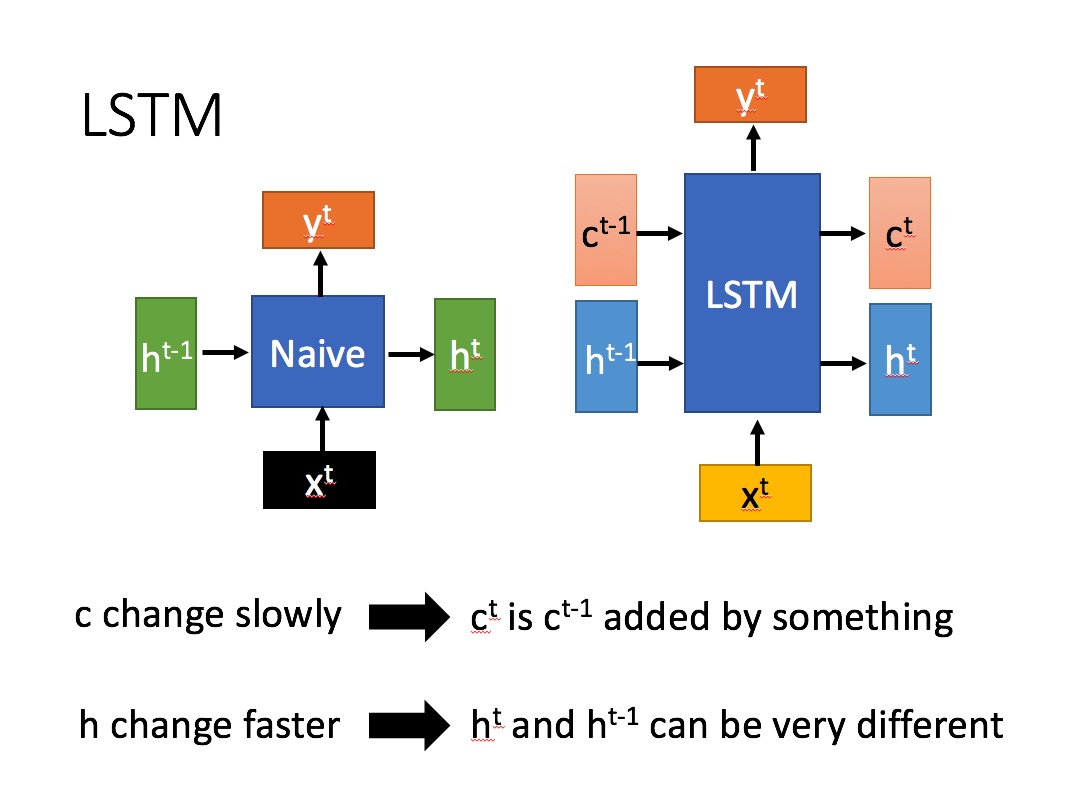
相比RNN只有一个传递状态 ,LSTM有两个传输状态,一个
(cell state),和一个
(hidden state)。(Tips:RNN中的
对于LSTM中的
)
其中对于传递下去的 改变得很慢,通常输出的
是上一个状态传过来的
加上一些数值。
而 则在不同节点下往往会有很大的区别。
LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 (f表示forget)来作为忘记门控,来控制上一个状态的
哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入
进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的
表示。而选择的门控信号则是由
(i代表information)来进行控制。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过
来进行控制的。并且还对上一阶段得到的
进行了放缩(通过一个tanh激活函数进行变化)。
与普通RNN类似,输出 往往最终也是通过
变化得到。