B站的一些东西的爬取
吼吼吼,在B站科技区(舞蹈区)学习的时候,突然发现可不可以爬取B站的一些东西呢?
just do it
1、分析网站,详情页网址构造
爬取的网址(搜索词:抖音)

可以看到,这是一页一页的翻页的,而且告诉了最后一页,这不可谓不良心网站了。而我要做的是点进去每一个视频去得到里面的内容。
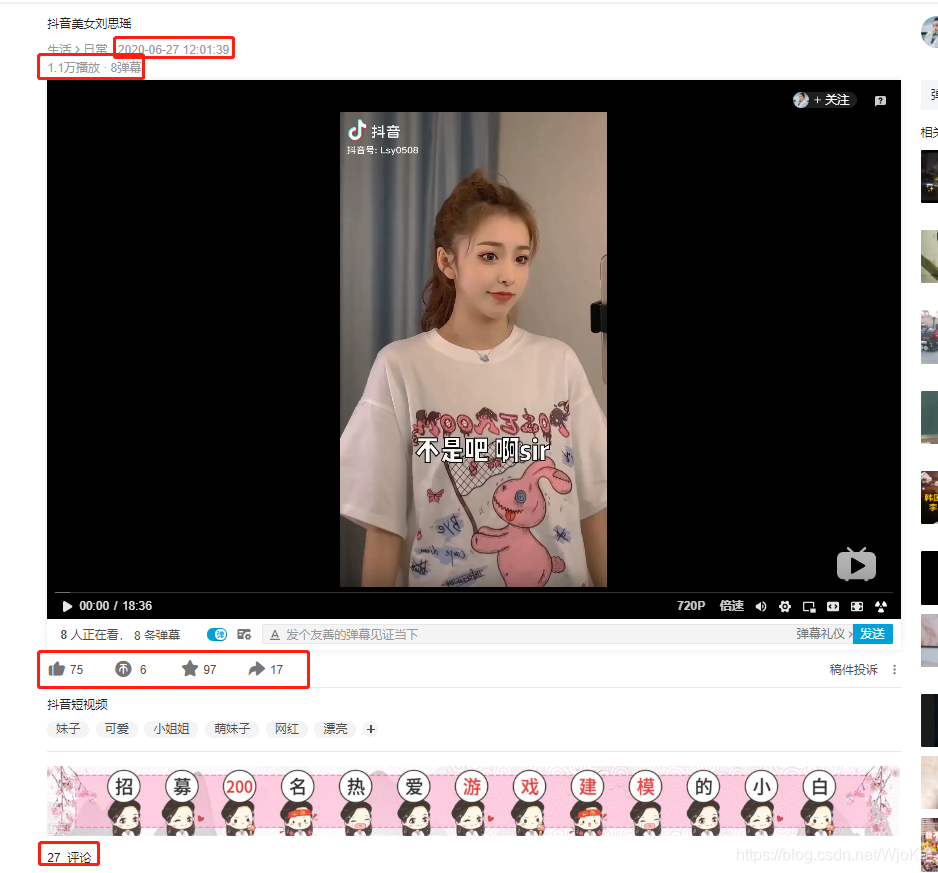
也就是上面圈出来的内容了,不是吧,阿sir这随手一点就是plmm。hhh
好!观察(看)完后,进入网页检查部分,要得到每个视频的详情网址。
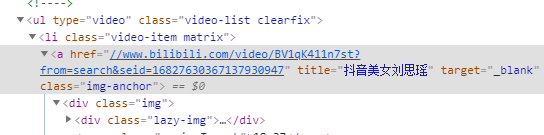
可以看到,这里可以得到详情页的网址,那么这里后续将会采取Xpath进行提取,但是得到的网址还不完善,所以还要构建一手网址。
具体代码如下:
a=[]###获取每一个视频的详细网址
for m in range(1,51):###要得到50页的所有的视频链接
res=requests.get('https://search.bilibili.com/all?keyword=%E6%8A%96%E9%9F%B3&from_source=nav_search_new&page='+str(m),headers=headers)
s=BeautifulSoup(res.text,'lxml')
a=a+['https:'+j for j in[i['href'] for i in s.find_all(name='a',class_='title')]]
2、详情页的数据得到
当我进入到详情页的时候,自以为就是很简单的静态网站,正准备开启音乐开始创作之时,发现只能得到发布时间这个字段,果然,事情并不是想象的那么简单。那么既然在前端找不到的东西,又能在网页上出现,它就大概率在后端。也就是动态网站,这样看来这就是个动静结合的网站了。好!打开检查网页,选取XHR文件:
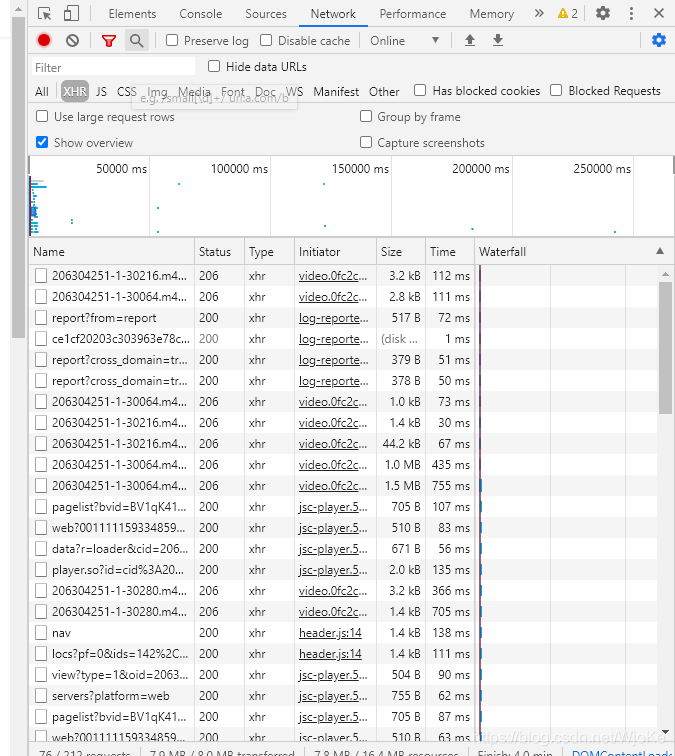
我人傻了。。。不可能一个一个去点吧。这个时候按住Ctrl+F出来搜索框:
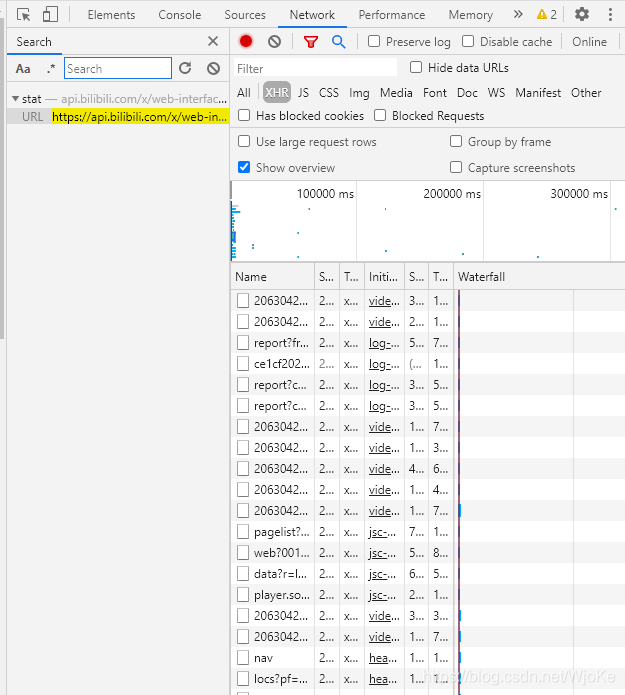
那么搜索什么呢?按理说是要得到什么就搜索什么,于是我就尝试着搜索了播放量,然后得到了一堆文件,随便检查几个文也就找到了一个json网页

这个网址中就有我们想要的东西,观察得到,只有最后的aid=后面的东西会变化,那么如何得到这个东西呢?直觉告诉我,在网页响应体中可以得到!抱着试一试的心态,我去找了,结果:
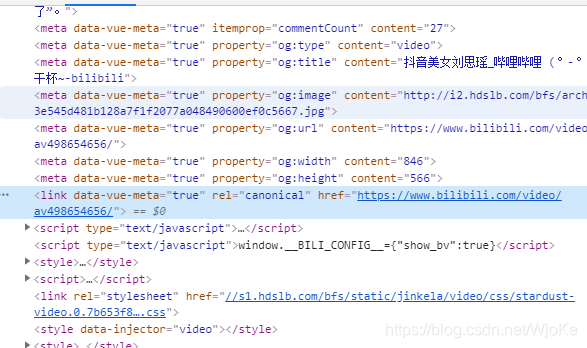
是真的牛比,我只需要用正则得到那个数字就好了。在得到这些后,利用代码得到数据:
times=[]
view=[]
danmaku=[]
like=[]
coin=[]
favorite=[]
share=[]
reply=[]
for n in range(len(a)):
ress=requests.get(a[n],headers=headers)
times=times+ht.xpath('//*[@id="viewbox_report"]/div[1]/span[2]/text()')
zz=re.search('<meta.*?"https://www.bilibili.com/video/av(\d+)/">',ress.text).group(1)###得到最终url的变化部分的数字
ree=requests.get('https://api.bilibili.com/x/web-interface/archive/stat?aid='+zz,headers=headers)###构建json网址
js=ree.json()['data']
view.append(js['view'])###播放量
danmaku.append(js['danmaku'])###弹幕
like.append(js['like'])###点赞
coin.append(js['coin'])###硬币
favorite.append(js['favorite'])###收藏
share.append(js['share'])###分享
reply.append(js['reply'])###评论
print(n)
time.sleep(5)
我设置了个停5s,毕竟还是要给B站个面子(其实是太快了会报错)
3、总结
化动为静,注意观察,保持耐心