文章目录
一、事前准备
首先了解一下什么是HBase,
Hbase的名字的来源是Hadoop database,即hadoop数据库。
适合于存储大表数据(表的规模可以达到数十亿行以及数百万列),并且对大表数据的读、写访问可以达到实时级别;
利用Hadoop HDFS(Hadoop Distributed File System)作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用ZooKeeper作为协同服务。
从基本介绍可以看出,在搭建HBase环境之前我们需要做如下准备:
1、虚拟机上安装有Hadoop
可以参考:CentOS7下安装和配置hadoop以及hadoop集群
2、虚拟机上安装有Zookeeper
可以参考:CentOS7下安装配置Zookeeper集群、使用VMware虚拟机解决时间同步问题
3、HBase安装包
准备三台虚拟机 主机名分别修改为hadoop1,hadoop2,hadoop3以下操作在hadoop1上进行
可以参考:CentOS7下安装和配置Hadoop以及Hadoop集群
二、安装HBase
将下载好的安装包拖入software目录下
使用命令解压至opt目录
tar -zxvf hbase-1.2.0-cdh5.14.2.tar.gz -C /opt/
进入opt目录对其改名
cd /opt
mv hbase-1.2.0-cdh5.14.2/ hbase
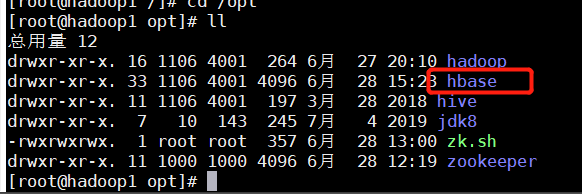
完成后修改环境变量
vi /etc/profile
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
三、HBase的三种运行模式
1、本地模式
当不使用HDFS时,直接存储在Linux
修改conf目录下的hbase-site.xml配置文件
vi /opt/hbase/conf/hbase-site.xml
<configuration>
<!--hbase文件存储目录 本地模式不需要hdfs直接存储在linux下-->
<property>
<name>hbase.rootdir</name>
<value>file:///opt/hbase/tmp</value>
</property>
</configuration>
修改完成之后就可以启动,之后使用jps查看进程
start-hbase.sh 启动
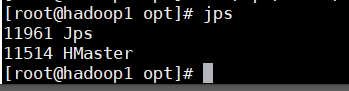
stop-hbase.sh 停止
2、伪分布模式
伪分布式与本地模式的区别是HBase的存储是用到了HDFS,所以在运行HBase之前需要先启动HDFS。
修改conf目录下的hbase-site.xml配置文件
vi /opt/hbase/conf/hbase-site.xml
<configuration>
<!--hbase文件存储目录,伪分布式-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<!--分布式开关为true-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
vi /opt/hbase/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk8
启动
start-dfs.sh
start-hbase.sh
使用jps查看进程
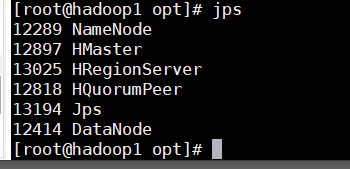
证明开启成功
关闭(要先关闭hbase)
stop-hbase.sh
stop-dfs.sh
3、全分布式
修改conf目录下的hbase-site.xml配置文件
vi /opt/hbase/conf/hbase-site.xml
<configuration>
<!--hbase文件存储目录,伪分布式-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<!--设置分布式为true-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--配置Hmaster的地址,选择主机-->
<property>
<name>hbase.master</name>
<value>hadoop1:6000</value>
</property>
<!--配置zookeeper集群-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
</configuration>
vi /opt/hbase/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk8
export HBASE_HOME=/opt/hbase
export HADOOP_HOME=/opt/hadoop
export HBASE_MANAGES_ZK=false
vi /opt/hbase/conf/regionservers
添加副机器主机名
副机器上要进行同样的修改,使用命令直接将修改好的文件传过去
三个配置文件,一个环境变量
scp -r /opt/hbase/conf/hbase-site.xml root@hadoop2:/opt/hbase/conf/hbase-site.xml
scp -r /opt/hbase/conf/hbase-env.sh root@hadoop2:/opt/hbase/conf/hbase-env.sh
scp -r /opt/hbase/conf/regionservers root@hadoop2:/opt/hbase/conf/regionservers
scp /etc/profile root@hadoop2:/etc/profile
hadoop2传完之后给hadoop3也传一份
完成之后启动–要注意启动顺序
1、hadoop主机器启动hdfs
start-dfs.sh
2、所有机器启动zookeeper
zkServer.sh start
可以参考
zookeeper一键启动小脚本
3、主机器启动hbase
start-hbase.sh
启动完成之后使用hbase shell命令进入hbase,命令list查看所有表,命令exit退出
全部机器都试一遍能否进入hbase
没有问题之后依次关闭
hbase环境搭建完成