手写mybatis解析流程
上一章我们分析了mybatis的架构和流程,并将整个流程分成了两部分
- 解析流程
- 执行流程
本章将在上一章的基础上,开始手写mybatis框架的解析流程。
流程分析
解析流程简单说就是将核心配置信息,以及映射配置信息,从xml形式或者注解等形式解析成java对象形式保存到内存中,为整个框架运行提供支撑,但是并不是简单的保存数据,因为有些数据还需要通过一些处理才能够使用,例如映射文件的sql信息,从xml中拿来的并不能直接被JDBC所执行,还需要一些处理,所以我所说的解析,除了保存数据之外,更重要的一步是提供数据的使用方式。
而解析流程最关键最难的地方在于sql的解析,如何将配置文件里面的sql语句最终解析成JDBC可以执行的语句,需要通过两个过程实现,一个是拼接过程,一个是解析过程,上一章已经分析过了,所以整个解析流程我们按照下面三部分依次讲解:
- 核心配置文件解析
- 映射配置文件解析
- sql解析(拼接过程和解析过程)
1. 核心配置文件解析
先把我们的核心配置文件mybatis-config-schema.xml展示出来:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration xmlns="http://www.aiduoduo.site/schema/mybatis" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.aiduoduo.site/schema/mybatis site/aiduoduo/mybatis/builder/xml/xsd/mybatis-config.xsd">
<properties resource="datasource.properties"/>
<enviroments default="dev">
<enviroment id="dev">
<datasource type="druid">
<property name="driverClassName" value="${db.driver}"/>
<property name="url" value="${db.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</datasource>
</enviroment>
</enviroments>
<mappers>
<mapper resource="mybatis-mapper.xml"/>
</mappers>
</configuration>
这个核心配置文件,我是用的schema约束,想要了解schema语法的,请走传送门,不会也不影响,和dtd一样,就是用来约束xml内容的。
通过这个配置文件,可以看到,我会实现以下几个小功能:
- 外部加载properties配置
- 使用连接池获取连接,我们只支持了一种druid的连接池
- 触发映射文件的解析
首先解析xml文件,最终解析出的信息需要有一个核心对象进行保存:
我们用Configuration对象存储核心配置文件里面的信息
/**
* @Author yangtianhao
* @Date 2020/2/5 5:28 下午
* @Version 1.0
*/
public class Configuration {
private Environment environment;
private Properties properties;
private Map<String, MappedStatment> mappedStatmentMap = new HashMap<>();
public Environment getEnvironment() {
return environment;
}
public void setEnvironment(Environment environment) {
this.environment = environment;
}
public void addMappedStatment(MappedStatment mappedStatment) {
mappedStatmentMap.put(mappedStatment.getId(), mappedStatment);
}
public Properties getProperties() {
return properties;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
public MappedStatment getMappedStatment(String id) {
return mappedStatmentMap.get(id);
}
}
它有三个成员变量:
Enviroment:保存环境相关信息,主要维护了连接池
properties:保存外部加载的properties文件内容
Map<String, MappedStatment>:保存映射文件信息解析后的statment信息
其中Enviroment对象,维护了连接池以及id属性。
package site.aiduoduo.mybatis.mapping;
import javax.sql.DataSource;
/**
* @Author yangtianhao
* @Date 2020/2/5 5:29 下午
* @Version 1.0
*/
public class Environment {
private String id;
private DataSource dataSource;
public Environment(String id, DataSource dataSource) {
this.id = id;
this.dataSource = dataSource;
}
public String getId() {
return id;
}
public DataSource getDataSource() {
return dataSource;
}
}
然后我们使用建造者设计模式,使用XmlConfigurationBuilder对象负责Configuration的构建,它会对xml进行解析,将Configuration的构建过程分成多个子步骤,依次执行完成后最终返回给我们Configuration对象
/**
* @Author yangtianhao
* @Date 2020/2/7 8:39 下午
* @Version 1.0
*/
public class XmlConfigurationBuilder {
private Configuration configuration;
private XpathParser xpathParser;
public XmlConfigurationBuilder(InputStream inputStream) {
xpathParser = new XpathParser(inputStream);
configuration = new Configuration();
}
public Configuration parse() throws Exception {
parseProperties(xpathParser.selectSingleElement("src:configuration/src:properties"));
parseEnviroments(xpathParser.selectSingleElement("src:configuration/src:enviroments"));
parseMappers(xpathParser.selectSingleElement("src:configuration/src:mappers"));
return configuration;
}
private void parseMappers(Element mappersElement) {
List<Element> mapperList = mappersElement.elements("mapper");
if(CollectionUtils.isNotEmpty(mapperList)){
for (Element element : mapperList) {
String resource = element.attributeValue("resource");
InputStream resourceAsStream = this.getClass().getClassLoader().getResourceAsStream(resource);
XmlMapperBuilder xmlMapperBuilder = new XmlMapperBuilder(configuration, resourceAsStream);
xmlMapperBuilder.parse();
}
}
}
private void parseEnviroments(Element enviromentsElement) throws Exception {
String defaultEnviromentId = enviromentsElement.attributeValue("default");
List<Element> enviromentList = enviromentsElement.elements("enviroment");
for (Element element : enviromentList) {
String id = element.attributeValue("id");
if (StringUtils.equals(defaultEnviromentId, id)) {
Element datasource = element.element("datasource");
String type = datasource.attributeValue("type");
if ("druid".equals(type)) {
GenericTokenParser genericTokenParser = new GenericTokenParser("${", "}", new PropertyHandler());
Map<String, String> dataSourceProperty = new HashMap();
List<Element> propertyList = datasource.elements("property");
for (Element property : propertyList) {
String name = property.attributeValue("name");
String value = property.attributeValue("value");
String parse = genericTokenParser.parse(value);
dataSourceProperty.put(name, configuration.getProperties().getProperty(parse));
}
DataSource dataSource = DruidDataSourceFactory.createDataSource(dataSourceProperty);
configuration.setEnvironment(new Environment(defaultEnviromentId, dataSource));
}
break;
}
}
}
private void parseProperties(Element propertiesElement) {
String resource = propertiesElement.attributeValue("resource");
if (StringUtils.isNotBlank(resource)) {
InputStream resourceAsStream = this.getClass().getClassLoader().getResourceAsStream(resource);
Properties properties = new Properties();
try {
properties.load(resourceAsStream);
} catch (IOException e) {
e.printStackTrace();
}
configuration.setProperties(properties);
}
}
}
需要关注的点:
-
成员属性:XpathParser对象
可以看到该对象是在XmlConfigurationBuilder构造函数中创建的,并且它的构造接收的是InputStream对象,该对象就是对应的xml配置文件的输入流,其实XpathParser类的职责就是专门用来解析xml文件,获取xml元素的,它的底层封装的是dom4j,维护了一个Document对象,创建该类意义在于:我们将所有的对xml的操作都委托给该类,具有很好的复用性,和隔离性。
需要注意的是,上面例子中在使用selectSingleElement方法的时候,底层用的是xpath获取元素,但是使用xpath语法的时候,我是这种格式src:configuration/src:properties,有src这个前缀,这是因为我们用的是schema约束,它的xml中有名称空间导致的。 -
XmlConfigurationBuilder构造函数
(1)构造中传InputStream,该流就是需要加载的核心配置文件的输入流,解析肯定要需要先知道解析哪个文件,然后委托给XpathParser进行解析。
(2)实例化一个Configuration对象,该对象内部属性都是空的,等解析的时候会对该对象进行初始化,一步步的封装数据,等解析完成,最终会将该对象返回。 -
parse()方法
(1)真正的解析方法,当调用该方法开始解析,将整个Configuration对象的构建分成了多个步骤,等解析完所有步骤后,最终会将Configuration对象返回
(2)解析分三个步骤(当然真正的mybatis远不只三个步骤。。),解析外部properties,解析enviroment环境,解析mapper映射信息
3.1 parseProperties()方法
比较简单,获取properties标签的resource属性,加载properties文件并保存到Configuration对象中
3.2 parseEnviroments()方法
加载enviroments标签,根据default值获取默认指定的环境配置信息,通过解析property标签的value属性,拿到key ,再从properties中获取真正的值,进行连接池的构建,并保存到Configuration对象中。
其中涉及到GenericTokenParser和PropertyHandler两个类,作用就是将例如"{db.url}" 的字符串,解析成"url",GenericTokenParser这个类后面解析sql的时候也会用,它的构造函数有三个参数public GenericTokenParser(String openToken, String closeToken, TokenHandler handler) {...},主要功能就是用来解析字符串,将字符串中被openToken开头,closeToken结尾包含的字符串替换成其他字符串,替换成什么样子就是通过传自己实现的TokenHandler决定的。
3.3 parseMappers()方法
解析mappers标签,获取所有子mapper标签的resource属性,通过属性获取对应的文件流,再委托给XmlMapperBuilder进行解析,可以看到XmlMapperBuilder进行解析,需要知道核心对象configuration才能对其进行mapper的初始化。XmlMapperBuilder这个类的职责就是专门负责解析映射配置文件的。
3.2中提到的GenericTokenParser和PropertyHandler附上源码,看一下,后面再用到的时候就不说了:
/*
* 这个类我是直接从源码拷贝的,本身没什么复杂的就是专门解析字符串替换字符串中被开始记号和结束记号包含的内容
*/
public class GenericTokenParser {
//有一个开始和结束记号
private final String openToken;
private final String closeToken;
//记号处理器,需要我们自己实现一个处理方式
private final TokenHandler handler;
//构造中需要传入开始标记、结束标记,以及记号处理器
public GenericTokenParser(String openToken, String closeToken, TokenHandler handler) {
this.openToken = openToken;
this.closeToken = closeToken;
this.handler = handler;
}
//真正解析的操作,会对传入的字符串进行解析
public String parse(String text) {
StringBuilder builder = new StringBuilder();
if (text != null && text.length() > 0) {
char[] src = text.toCharArray();
//当前处理索引,一开始是0
int offset = 0;
//寻找开始标记的索引
int start = text.indexOf(openToken, offset);
//如果找到的话,开始进行解析
while (start > -1) {
//判断一下 开始记号 前面是否是反斜杠,如果是,认为是转义,不会处理这个开始标记
if (start > 0 && src[start - 1] == '\\') {
//新版mybatis已经没有调用substring了,改为调用如下的offset方式,提高了效率
builder.append(src, offset, start - offset - 1).append(openToken);
offset = start + openToken.length();
} else {
//找到结束记号
int end = text.indexOf(closeToken, start);
if (end == -1) {
builder.append(src, offset, src.length - offset);
offset = src.length;
} else {
//这边拼接完以后,builder相当于是开始标记前的内容
builder.append(src, offset, start - offset);
//下面两步,相当于获取开始标记和结束标间包含的内容(不包括开始标记和结束标间本身)
offset = start + openToken.length();
String content = new String(src, offset, end - offset);
//得到开始标记和结束标记包含的字符串后,调用handler.handleToken,对包含的内容进行处理,然后拼接回builder
builder.append(handler.handleToken(content));
//将当前处理索引置为结束标记后面第一个字符的位置
offset = end + closeToken.length();
}
}
//从当前处理索引后重新寻找开始标记,找到话会重复上面步骤
start = text.indexOf(openToken, offset);
}
if (offset < src.length) {
builder.append(src, offset, src.length - offset);
}
}
//经过一次次循环处理,会将字符串中所有被开始标记和结束标记包含的内容都处理掉,最终返回处理完的结果
return builder.toString();
}
}
/**
* @Author yangtianhao
* @Date 2020/2/8 5:03 下午
* @Version 1.0
*/
public class PropertyHandler implements TokenHandler {
//就是为了将<property name="driverClassName" value="${db.driver}"/>
//中的${db.driver}解析成db.driver,所以直接返回即可。
public String handleToken(String content) {
return content;
}
}
2. 映射配置文件解析
我们接着看XmlMapperBuilder,上面说过该类的职责就是专门负责解析映射配置文件的。
/**
* @Author yangtianhao
* @Date 2020/2/13 2:47 下午
* @Version 1.0 解析Mapper映射文件
*/
public class XmlMapperBuilder {
private Configuration configuration;
private XpathParser xpathParser;
private String namespace;
public XmlMapperBuilder(Configuration configuration, InputStream inputStream) {
this.configuration = configuration;
xpathParser = new XpathParser(inputStream);
}
public void parse() {
parseNamespace(xpathParser.selectSingleElement("src:mapper"));
parseMappedStatment(xpathParser.selectElements("src:mapper/src:select|src:mapper/src:insert"));
}
private void parseMappedStatment(List<Element> mappedStatmentElementList) {
if (CollectionUtils.isNotEmpty(mappedStatmentElementList)) {
for (Element element : mappedStatmentElementList) {
XMLStatementBuilder XMLStatementBuilder = new XMLStatementBuilder(element,namespace);
configuration.addMappedStatment(XMLStatementBuilder.parseStatementNode());
}
}
}
private void parseNamespace(Element mapperElement) {
namespace = mapperElement.attributeValue("namespace");
}
}
看到parse()解析方法做了两件事,一个是解析获取Namespace,即该mapper映射文件对应的名称空间,另一件事就是解析映射文件中的select/insert标签(此次手写我们只实现了select/insert标签,真正的mybatis更加复杂,除了处理select/insert/update/delete标签外, 还有缓存啊,resultMap啊,Sql片段啊等等,并且源码中是依赖MapperBuilderAssistant这个类,叫映射器构建助手进行构建的。。我们这边简单处理了)
对应解析的映射文件长这个样子:
<?xml version="1.0" encoding="UTF-8" ?>
<mapper xmlns="http://www.aiduoduo.site/schema/mybatis-mapper" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.aiduoduo.site/schema/mybatis-mapper site/aiduoduo/mybatis/builder/xml/xsd/mybatis-mapper.xsd"
namespace="site.aiduoduo.user">
<select id="selectAll" resultType="site.aiduoduo.mybatis.pojo.User" parameterType="site.aiduoduo.mybatis.pojo.User"
statmentType="prepared">
select * from user
</select>
<select id="selectByPhone" resultType="site.aiduoduo.mybatis.pojo.User"
parameterType="site.aiduoduo.mybatis.pojo.User" statmentType="prepared">
select * from user
<where>
<if test="phone != null">
and phone = #{phone}
</if>
</where>
</select>
<insert id="insert" parameterType="site.aiduoduo.mybatis.pojo.User" statmentType="prepared">
<if test="">
insert into user(name,gender,phone,address) values(#{name},#{gender},#{phone},#{address});
</if>
</insert>
</mapper>
此次手写mybatis,我们只支持insert和select标签,另外动态标签里面只支持if和where标签。
继续往下看,XmlMapperBuilder.parseMappedStatment()方法,当我们处理select/insert标签的时候,又是委托给了XMLStatementBuilder:
/**
* @Author yangtianhao
* @Date 2020/2/13 3:09 下午
* @Version 1.0
*/
public class XMLStatementBuilder {
private Element statmentELement;
private String namespace;
public XMLStatementBuilder(Element statmentElement, String namespace) {
this.statmentELement = statmentElement;
this.namespace = namespace;
}
public MappedStatment parseStatementNode() {
String id = namespace+"."+statmentELement.attributeValue("id");
String parameterType = statmentELement.attributeValue("parameterType");
String resultType = statmentELement.attributeValue("resultType");
String statmentType = statmentELement.attributeValue("statmentType");
XMLScriptBuilder xmlScriptBuilder = new XMLScriptBuilder(statmentELement);
SqlSource sqlSource = xmlScriptBuilder.parseScriptNode();
return new MappedStatment(id, parameterType, resultType, sqlSource, statmentType);
}
}
XmlMappedStatmentBuilder的职责就是解析映射文件中的select/insert/update/delete标签,并最终会封装成一个MappedStatment对象返回,所以映射文件中每一个select/insert/update/delete标签都对应一个MappedStatment对象。
我们继续看parseStatementNode()方法,里面主要解析了该MappedStatment的id,parameterType,statmentType等属性,其中标签内的复杂的sql,是通过SqlSource对象存储的,而SqlSource的构建又是委托给了XMLScriptBuilder,由它负责解析标签内的sql,并返回一个SqlSource对象。(当然这只是我们简单的实现,相比源码省去了很多复杂细节,考虑的情况也远没有源码那么全面)
3. sql解析
讲到这里,在讲sql解析前,我们需要知道sql信息,到底是按照什么样的数据结构存储的,我们先把上一章sql的解析先复习一遍,还是这张图:
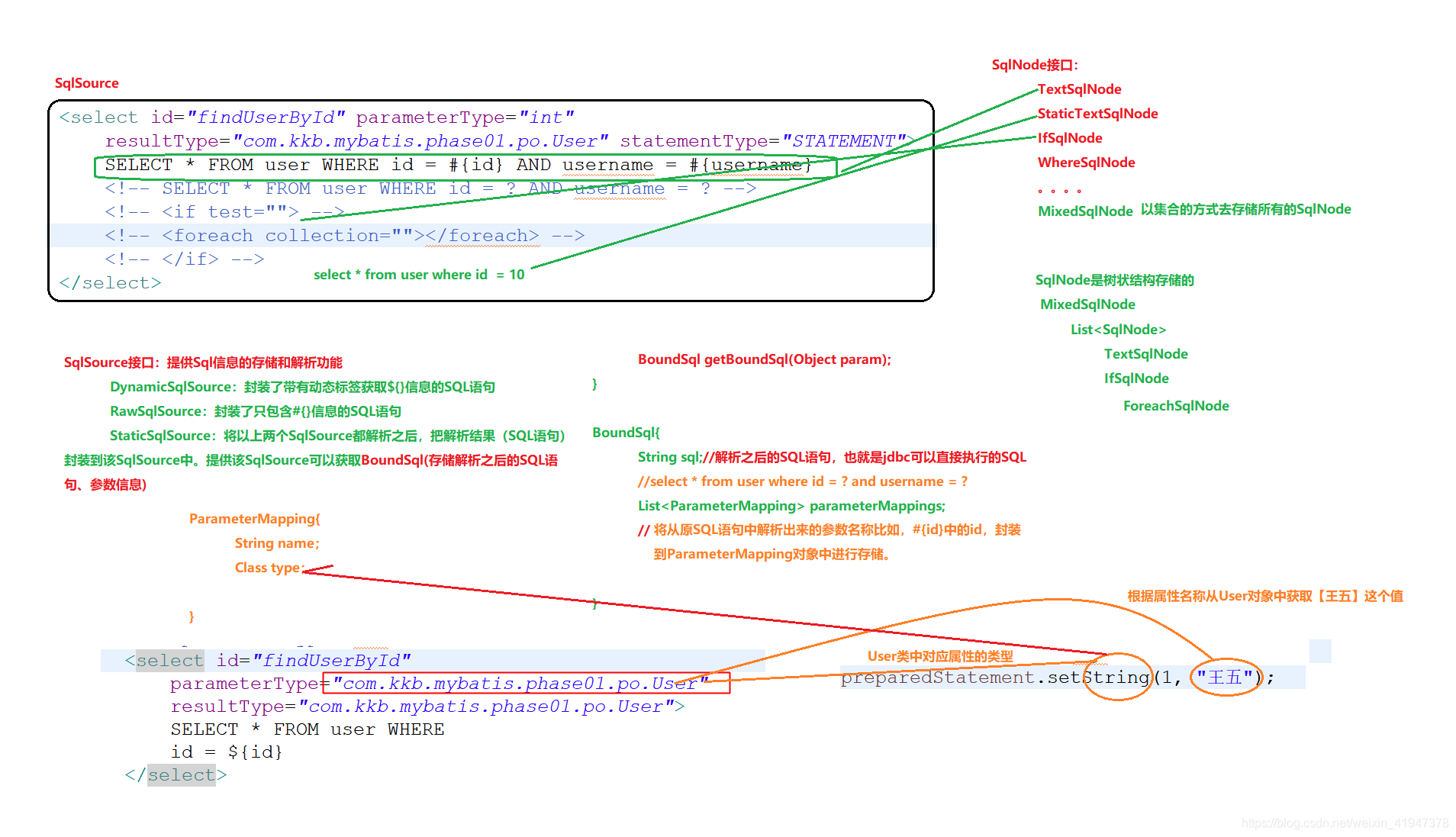
上一章我们知道,映射文件中每一个insert/update/delete/select标签都对应一个MappedStatement对象:
/**
* @Author yangtianhao
* @Date 2020/2/7 8:16 下午
* @Version 1.0
*/
public class MappedStatement {
private final String id;
private final String parameterType;
private final String resultType;
private final String statementType;
private final SqlSource sqlSource;
public MappedStatement(String id, String parameterType, String resultType, SqlSource sqlSource, String statementType) {
this.id = id;
this.parameterType = parameterType;
this.resultType = resultType;
this.sqlSource = sqlSource;
this.statementType = statementType;
}
//get\set略...
}
看到该对象分别存储了statment对应的id,入参类型,结果集类型,statement类型,以及sqlSource。
我们也知道,标签内的sql信息,都是封装在SqlSource的实现类里面的,并且是以SqlNode集合方式存储的。SqlSource还提供了一个方法,BoundSql getBoundSql(Object param)方法,会直接返回一个BoundSql对象,该对象保存了可以被JDBC直接执行的sql以及该sql对应的参数信息:
/**
* @Author yangtianhao
* @Date 2020/2/13 3:16 下午
* @Version 1.0
*/
public interface SqlSource {
BoundSql getBoundSql(Object param);
}
/**
* @Author yangtianhao
* @Date 2020/2/13 4:37 下午
* @Version 1.0
*/
public class BoundSql {
private String sql;
private List<ParameterMapping> parameterMappings;
public BoundSql(String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
}
public String getSql() {
return sql;
}
public List<ParameterMapping> getParameterMappings() {
return parameterMappings;
}
}
/**
* @Author yangtianhao
* @Date 2020/2/14 2:14 下午
* @Version 1.0
*/
public class ParameterMapping {
private String name;
private Class type;
public ParameterMapping(String name, Class type) {
this.name = name;
this.type = type;
}
//....
}
根据SqlSource实现类中包含的SqlNode类型不同,我们有三个实现类:
- DynamicSqlSource
- RawSqlSource
- StaticSqlSource
DynamicSqlSource:SqlNode集合中包含了带有${}或者动态SQL标签的SqlNode
/**
* @Author yangtianhao
* @Date 2020/2/13 4:31 下午
* @Version 1.0
*/
public class DynamicSqlSource implements SqlSource {
private SqlNode contents;
public DynamicSqlSource(SqlNode contents) {
this.contents = contents;
}
@Override
public BoundSql getBoundSql(Object param) {
DynamicContext dynamicContext = new DynamicContext(param);
contents.apply(dynamicContext);
String sql = dynamicContext.getSql().toString();
SqlSourceParser sqlSourceParser = new SqlSourceParser();
SqlSource parse = sqlSourceParser.parse(sql);
return parse.getBoundSql(param);
}
}
可以看到,DynamicSqlSource中contents存储的就是SqlNode集合(具体存储的对象是MixedSqlNode,是SqlNode的一种实现,是一个组合对象,底层存储的就是SqlNode的集合,代表一组SqlNode),DynamicSqlSource有一个特性,因为SqlNode集合中包含了${}或者动态标签的SqlNode,所以每一次用户传进来的param参数不同,最终解析出来的sql都有可能不一样,所以DynamicSqlSource的解析工作是发生在每一次调用getBoundSql方法的时候 。
我们再看RawSqlSource:封装的SqlNode集合中只含有"只带有#{}的SqlNode"
/**
* @Author yangtianhao
* @Date 2020/2/13 4:30 下午
* @Version 1.0
*/
public class RawSqlSource implements SqlSource {
private SqlNode contents;
private SqlSource delegate;
public RawSqlSource(SqlNode contents) {
this.contents = contents;
DynamicContext dynamicContext = new DynamicContext(null);
contents.apply(dynamicContext);
String sql = dynamicContext.getSql().toString();
SqlSourceParser sqlSourceParser = new SqlSourceParser();
SqlSource parse = sqlSourceParser.parse(sql);
delegate = parse;
}
@Override
public BoundSql getBoundSql(Object param) {
return delegate.getBoundSql(param);
}
}
其中contents和DynamicSqlSource一样,存储的都是MixedSqlNode,即SqlNode集合,只不过该集合中只含有"只带有#{}的SqlNode",只带有#{}的sql语句是不需要根据用户传进来的参数,动态拼接的,只需要将#{}替换成?占位符,并存储?占位符对应的参数信息,所以它的解析工作只需要发生在第一次构造RawSqlSource的时候,并且只需要被解析一次。
另外我们看到它还有一个成员属性SqlSource delegate,因为只需要解析一次,所以我们把解析之后的结果存在这个成员属性中,当调用RawSqlSource.getBoundSql的时候,直接委托给在构造的时候就解析完成并存储在delegate的对象即可。另外sqlSourceParser解析出来的结果封装在了正是SqlSource第三个实现类StaticSqlSource中。
StaticSqlSource:当上面两个SqlSource解析后,都会把解析结果封装到该对象中,通过该SqlSource获取到BoundSql
/**
* @Author yangtianhao
* @Date 2020/2/14 2:19 下午
* @Version 1.0
*/
public class StaticSqlSource implements SqlSource {
private String sql;
private List<ParameterMapping> parameterMappings;
public StaticSqlSource(String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
}
@Override
public BoundSql getBoundSql(Object param) {
return new BoundSql(sql, parameterMappings);
}
}
看到存的就是可执行sql以及占位符?对应的参数信息。
在RawSqlSource和DynamicSqlSource中我们看到都有下面一段重复代码:
//如果是DynamicSqlSource,new DynamicContext会传进去参数
DynamicContext dynamicContext = new DynamicContext(null);
contents.apply(dynamicContext);
String sql = dynamicContext.getSql().toString();
//-------------------------------
SqlSourceParser sqlSourceParser = new SqlSourceParser();
SqlSource parse = sqlSourceParser.parse(sql);
其中分割线上面代码的就是sql拼接的过程,下面就是sql的解析过程:
- 拼接阶段:拼接sql节点,只处理动态标签和${},最终返回只包含#{}的sql语句
- 解析阶段:处理#{},解析成占位符,最终返回可执行的sql和参数映射信息
拼接阶段
之前说过,每个select/update标签下的sql信息都是一个个sqlNode组成的,按照节点包含的内容不同,实现类也分很多种,但是每个SqlNode实现类只存储该节点信息还不够,还需要根据用户传的参数进行逻辑判断,根据每个节点的逻辑对信息进行处理和拼接的功能,所以SqlNode接口定义了一个方法apply(DynamicContext context),其中DynamicContext里面维护了用户传递的入参,和一个StringBuilder变量,用来存储拼接的sql语句,该方法会根据当前节点的逻辑对节点中的信息进行处理,然后拼接到StringBuilder中,注意此时的处理,只是根据动态标签的逻辑,完成了字符串的拼接,或者替换了字符串中的${},并不会处理#{}。当调用顶层节点的apply方法的时候,会依次遍历树中每个节点,所以每个节点都有机会并且按照顺序依次执行自己的apply方法对StringBuilder进行拼接,最终从StringBuilder中方可以得到一个完整的sql语句,当然得到的是一个最多只包含#{}的sql语句。
我们看下DynamicContext :
/**
* @Author yangtianhao
* @Date 2020/2/13 9:04 下午
* @Version 1.0
*/
public class DynamicContext {
private StringBuilder sql = new StringBuilder();
private Map<String, Object> params = new HashMap<>();
public DynamicContext(Object param) {
params.put("_parameter", param);
}
public StringBuilder getSql() {
return sql;
}
public void setSql(StringBuilder sql) {
this.sql = sql;
}
public Map<String, Object> getParams() {
return params;
}
public void setParams(Map<String, Object> params) {
this.params = params;
}
}
再看下最关键的接口SqlNode,提供了拼接方法apply:
/**
* @Author yangtianhao
* @Date 2020/2/13 3:24 下午
* @Version 1.0
*/
public interface SqlNode {
void apply(DynamicContext context);
}
这次手写,我们只支持fi和where动态标签,所以我们一共有5个实现类:
- MixedSqlNode
- StaticTextSqlNode
- TextSqlNode
- IfSqlNode
- WhereSqlNode
MixedSqlNode:混合节点,代表一组节点。使用组合设计模式,以集合方式存储子节点,使得用户可以使用一致的方法操作单个对象和组合对象。
/**
* @Author yangtianhao
* @Date 2020/2/13 4:09 下午
* @Version 1.0
*/
public class MixedSqlNode implements SqlNode {
List<SqlNode> sqlNodeList;
public MixedSqlNode(List<SqlNode> sqlNodeList) {
this.sqlNodeList = sqlNodeList;
}
@Override
public void apply(DynamicContext context) {
for (SqlNode sqlNode : sqlNodeList) {
// 处理很简单,依次遍历自己的子节点处理即可
sqlNode.apply(context);
}
}
}
StaticTextSqlNode:封装的是仅带有#{}的文本节点
/**
* @Author yangtianhao
* @Date 2020/2/13 3:41 下午
* @Version 1.0 静态sql片段
*/
public class StaticTextSqlNode implements SqlNode {
private String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public void apply(DynamicContext context) {
//只包含#{}的sql片段不需要任何处理,直接拼接即可
context.getSql().append(text);
}
}
TextSqlNode:封装的是带有${}的文本节点
/**
* @Author yangtianhao
* @Date 2020/2/13 3:42 下午
* @Version 1.0 包含${}的Sql片段
*/
public class TextSqlNode implements SqlNode {
private String text;
public TextSqlNode(String text) {
this.text = text;
}
//判断是否是动态,这边只做了个简单判断,该方法在构建的时候使用
public boolean isDynamic() {
//如果包含${,就认为是动态的(这边简单处理了,这个方式验证当时是不靠谱的)
if (text.indexOf("${") > 0) {
return true;
}
return false;
}
@Override
public void apply(DynamicContext context) {
BindingTokenHandler bindingTokenHandler = new BindingTokenHandler(context);
//上面我们说过了genericTokenParser专门解析并替换字符串指定内容的,替换方案具体实现就在bindingTokenHandler中
GenericTokenParser genericTokenParser = new GenericTokenParser("${", "}", bindingTokenHandler);
//此次替换,会将该sql片段中所有${xx},根据xx从用户传入的参数找到对应值替换掉
String parse = genericTokenParser.parse(text);
context.getSql().append(parse);
}
private static class BindingTokenHandler implements TokenHandler {
private DynamicContext context;
public BindingTokenHandler(DynamicContext context) {
this.context = context;
}
@Override
public String handleToken(String content) {
//context中维护了拼接的sql和用户传入的参数
Object parameter = context.getParams().get("_parameter");
if (parameter != null) {
//判断用户传入的参数是否是简单数据类型(8种基本数据类型和String)
if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getParams().put("value", String.valueOf(parameter));
}
} else {
context.getParams().put("value", "");
}
//根据Ognl表达式进行取值
Object value = OgnlUtils.getValue(content, context.getParams());
return value == null ? "" : String.valueOf(value);
}
}
}
注意:可以看到handleToken中,判断用户如果传入的数据是简单数据类型,会把数据的key当做“value”存储到map中 ,这就是为什么:
- ${} : 如果进行简单类型(String、Date、8种基本类型的包装类)的输入映射时,${}中参数名称必须是value
IfSqlNode:封装的是if动态标签的混合节点
/**
* @Author yangtianhao
* @Date 2020/2/13 4:09 下午
* @Version 1.0
*/
public class IfSqlNode implements SqlNode {
// 存储的是该If标签下的所有子节点(就是MixedSqlNode)
private SqlNode sqlNode;
// 该If标签的判断条件
private String text;
public IfSqlNode(SqlNode sqlNode, String text) {
this.sqlNode = sqlNode;
this.text = text;
}
@Override
public void apply(DynamicContext context) {
//ognl 表达式进行判断,如果true,所有子节点继续处理
if (OgnlUtils.evaluateBoolean(text, context.getParams().get("_parameter"))) {
sqlNode.apply(context);
}
}
}
WhereSqlNode:封装的是Where动态标签的混合节点
/**
* @Author yangtianhao
* @Date 2020/2/13 4:09 下午
* @Version 1.0
*/
public class WhereSqlNode implements SqlNode {
// 存储的是该Where标签下的所有子节点(就是MixedSqlNode)
private SqlNode contents;
public WhereSqlNode(SqlNode contents) {
this.contents = contents;
}
@Override
public void apply(DynamicContext context) {
DynamicContext dynamicContext = new DynamicContext(context.getParams().get("_parameter"));
contents.apply(dynamicContext);
String sql = dynamicContext.getSql().toString();
//如果where下子节点拼接完不为空,会自动拼接“where”,并且把第一个and去掉
if (sql.length() > 0) {
if (sql.startsWith("and") || sql.startsWith("AND")) {
sql = sql.substring(3);
}
context.getSql().append(" where").append(" " + sql);
}
}
}
解析阶段
解析工作我们是委托给SqlSourceParser的,它会将DynamicContext中拼接好的sql拿出来进行解析,把#{}替换为?占位符,同时将#{}中的参数信息封装成了ParameterMapping对象,最终返回一个静态的SqlSource,StaticSqlSource:
/**
* @Author yangtianhao
* @Date 2020/2/14 4:26 下午
* @Version 1.0
*/
public class SqlSourceParser {
public SqlSource parse(String sql) {
ParameterMappingTokenHandler parameterMappingTokenHandler = new ParameterMappingTokenHandler();
GenericTokenParser genericTokenParser = new GenericTokenParser("#{", "}", parameterMappingTokenHandler);
String parseSql = genericTokenParser.parse(sql);
List<ParameterMapping> parameterMappingList = parameterMappingTokenHandler.getParameterMappingList();
return new StaticSqlSource(parseSql, parameterMappingList);
}
public class ParameterMappingTokenHandler implements TokenHandler {
List<ParameterMapping> parameterMappingList = new ArrayList<>();
@Override
public String handleToken(String content) {
String name = content;
Class type = null;
parameterMappingList.add(new ParameterMapping(name, type));
return "?";
}
public List<ParameterMapping> getParameterMappingList() {
return parameterMappingList;
}
}
}
所有解析的逻辑已经讲完了,我们继续接着 2. 映射配置文件解析往下讲,看下SqlSource的具体构建过程。
构建过程:
上面说过SqlSource的构建又是委托给了XMLScriptBuilder,由它负责解析标签内的sql,并返回一个SqlSource对象。
/**
* @Author yangtianhao
* @Date 2020/2/13 3:17 下午
* @Version 1.0 解析select/insert/update/delete标签
*/
public class XMLScriptBuilder {
private Element statmentELement;
/**
* 如果包含${}或者有动态标签,就是动态的SqlSource
*/
private boolean isDynamic;
public XMLScriptBuilder(Element statmentELement) {
this.statmentELement = statmentELement;
}
//入口方法
public SqlSource parseScriptNode() {
//先解析当前标签下所有子节点
List<SqlNode> sqlNodes = parseSqlNodes(statmentELement);
SqlSource sqlSource = null;
//判断是否是动态的,决定生成哪种SqlSource
if (isDynamic) {
sqlSource = new DynamicSqlSource(new MixedSqlNode(sqlNodes));
} else {
sqlSource = new RawSqlSource(new MixedSqlNode(sqlNodes));
}
return sqlSource;
}
private List<SqlNode> parseSqlNodes(Node rootNode) {
List<Node> list = rootNode.selectNodes("node()");
List<SqlNode> sqlNodeList = new ArrayList<SqlNode>();
if (CollectionUtils.isNotEmpty(list)) {
for (Node node : list) {
//判断是否是纯文本节点
if (node.getNodeType() == Node.TEXT_NODE) {
String data = node.getText();
data = parseText(data);
if (StringUtils.isBlank(data)) {
continue;
}
TextSqlNode textSqlNode = new TextSqlNode(data);
//如果是纯文本节点,判断是否含${},包含就是动态的
if (textSqlNode.isDynamic()) {
isDynamic = true;
sqlNodeList.add(textSqlNode);
} else {
//不包含就构建静态SqlNode
sqlNodeList.add(new StaticTextSqlNode(data));
}
} else if (node.getNodeType() == Node.ELEMENT_NODE) {
isDynamic = true;
Element element = (Element)node;
String name = node.getName();
//如果是元素节点,根据标签名获取对应的节点处理器对节点进行处理
NodeHandle handle = getHandle(name);
handle.handle(element, sqlNodeList);
}
}
}
return sqlNodeList;
}
//对字符串进行了简单处理,为了去掉多余的\n换行符和空格
private String parseText(String data) {
return data.replaceAll("\n", "").trim();
}
//根据标签名称获取对应的节点处理器
private NodeHandle getHandle(String name) {
switch (name) {
case "where":
return new WhereNodeHandle();
case "if":
return new IfNodeHandle();
default:
return new NullNodeHandle();
}
}
//节点处理器接口,内部接口
private interface NodeHandle {
void handle(Element node, List<SqlNode> list);
}
//where标签节点处理器
private class WhereNodeHandle implements NodeHandle {
public void handle(Element node, List<SqlNode> list) {
//whereSqlNode只需要知道节点下所有子节点
List<SqlNode> sqlNodeList = parseSqlNodes(node);
list.add(new WhereSqlNode(new MixedSqlNode(sqlNodeList)));
}
}
//if标签节点处理器
private class IfNodeHandle implements NodeHandle {
public void handle(Element node, List<SqlNode> list) {
//if节点需要知道test判断条件,以及节点下所有子节点
String test = node.attributeValue("test");
List<SqlNode> sqlNodeList = parseSqlNodes(node);
list.add(new IfSqlNode(new MixedSqlNode(sqlNodeList), test));
}
}
private class NullNodeHandle implements NodeHandle {
public void handle(Element node, List<SqlNode> list) {
}
}
}
入口方法parseScriptNode中我们看到,分成了两步,先解析该标签下所有子SqlNode,即parseSqlNodes()方法,得到一个SqlNode集合,再根据集合中是否有动态元素,决定返回DynamicSqlSource还是RawSqlSource。
parseSqlNodes() 方法中,先判断获取的节点是否是纯文本节点:
- 如果是纯文本节点
- 在判断是否包含${},包含就构建TextSqlNode,
- 不包含就构建StaticTextSqlNode。
- 如果是元素节点,根据我们定义的节点处理器,找到对应的处理器进行处理
- where元素就构建WhereSqlNode
- if元素就构建IfNodeHandle
致此,解析流程的代码编写完成,接下来我们测试一下:
package site.aiduoduo.mybatis.test;
import org.apache.commons.collections4.CollectionUtils;
import org.junit.Test;
import site.aiduoduo.mybatis.builder.XmlConfigurationBuilder;
import site.aiduoduo.mybatis.mapping.BoundSql;
import site.aiduoduo.mybatis.mapping.Configuration;
import site.aiduoduo.mybatis.mapping.MappedStatement;
import site.aiduoduo.mybatis.mapping.ParameterMapping;
import site.aiduoduo.mybatis.pojo.User;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* @Author yangtianhao
* @Date 2020/1/29 4:28 下午
* @Version 1.0
*/
public class FrameworkTest {
@Test
public void test() throws Exception {
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
// 注意:使用JDBC规范,采用都是 java.sql包下的内容
try {
Configuration configuration = new XmlConfigurationBuilder(
this.getClass().getClassLoader().getResourceAsStream("mybatis-config-schema.xml")).parse();
conn = configuration.getEnvironment().getDataSource().getConnection();
// 3 获取sql语句
MappedStatement mappedStatement = configuration.getMappedStatment("site.aiduoduo.user.selectByPhone");
User user = new User();
user.setPhone("18115610044");
BoundSql boundSql = mappedStatement.getSqlSource().getBoundSql(user);
String sql = boundSql.getSql();
// 4 获取预处理 statement
if ("prepared".equals(mappedStatement.getStatementType())) {
stmt = conn.prepareStatement(sql);
}
// 5 设置参数,序号从1开始
if (CollectionUtils.isNotEmpty(boundSql.getParameterMappings())) {
for (int i = 0; i < boundSql.getParameterMappings().size(); i++) {
ParameterMapping parameterMapping = boundSql.getParameterMappings().get(i);
String name = parameterMapping.getName();
Field field = user.getClass().getDeclaredField(name);
field.setAccessible(true);
Object o = field.get(user);
stmt.setObject(i + 1, o);
}
}
// 6 执行SQL语句
rs = stmt.executeQuery();
// 7 处理结果集
while (rs.next()) {
// 获得一行数据
System.out.println(rs.getString("name") + ", " + rs.getString("gender") + "," + rs.getString("phone")
+ "," + rs.getString("address"));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 8释放资源
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
我们测试是成功的。结果就不打了。注意,因为是解析流程,所以只是构建了Configuration对象,通过该对象获取连接,和sql语句,然后通过JDBC基本执行流程执行的,我们将在下一章对执行流程编写,到时候,会看到执行的代码更加简洁。
另外本章有一些工具类代码没有展示:
OGNL工具类:
/**
* @Author yangtianhao
* @Date 2020/2/14 12:06 下午
* @Version 1.0
*/
public class OgnlUtils {
public static Object getValue(String expression, Object paramObject) {
OgnlContext ognlContext = new OgnlContext();
ognlContext.setRoot(paramObject);
try {
Object parseExpression = Ognl.parseExpression(expression);
Object value = Ognl.getValue(parseExpression, ognlContext, ognlContext.getRoot());
return value;
} catch (OgnlException e) {
e.printStackTrace();
}
return null;
}
public static boolean evaluateBoolean(String expression, Object paramObject) {
Object value = getValue(expression, paramObject);
if (value instanceof Boolean) {
return (Boolean)value;
}
return value != null;
}
}
解析xml的解析器:
/**
* @Author yangtianhao
* @Date 2020/2/8 3:27 下午
* @Version 1.0
* 简单解析,不弄那么复杂了
*/
public class XpathParser {
private Document document;
public XpathParser(InputStream inputStream) {
SAXReader saxReader = new SAXReader();
try {
document = saxReader.read(inputStream);
//因为我用的是XML Schemal,所以需要处理名称空间
Map<String, String> namespaceMap = new HashMap();
for (Object o : document.getRootElement().content()) {
if (o instanceof Namespace) {
Namespace ns = (Namespace)o;
String namespacePrefix = StringUtils.isBlank(ns.getPrefix())?"src":ns.getPrefix();
String namespaceURI = ns.getURI();
namespaceMap.put(namespacePrefix, namespaceURI);
}
}
saxReader.getDocumentFactory().setXPathNamespaceURIs(namespaceMap);
} catch (DocumentException e) {
e.printStackTrace();
}
}
public List<Node> selectNodes(String s) {
return document.selectNodes(s);
}
public Node selectSingleNode(String s) {
return document.selectSingleNode(s);
}
public Element selectSingleElement(String s) {
List<Element> elements = selectElements(s);
if(CollectionUtils.isNotEmpty(elements)){
return elements.get(0);
}
return null;
}
public List<Element> selectElements(String s) {
List list = document.selectNodes(s);
Iterator iterator = list.iterator();
while(iterator.hasNext()){
Node node = (Node) iterator.next();
if(node.getNodeType() != Node.ELEMENT_NODE){
iterator.remove();
}
}
return list;
}
}
判断是否是简单数据类型的工具类:
/**
* @author Clinton Begin
*/
public class SimpleTypeRegistry {
private static final Set<Class<?>> SIMPLE_TYPE_SET = new HashSet<Class<?>>();
static {
SIMPLE_TYPE_SET.add(String.class);
SIMPLE_TYPE_SET.add(Byte.class);
SIMPLE_TYPE_SET.add(Short.class);
SIMPLE_TYPE_SET.add(Character.class);
SIMPLE_TYPE_SET.add(Integer.class);
SIMPLE_TYPE_SET.add(Long.class);
SIMPLE_TYPE_SET.add(Float.class);
SIMPLE_TYPE_SET.add(Double.class);
SIMPLE_TYPE_SET.add(Boolean.class);
SIMPLE_TYPE_SET.add(Date.class);
SIMPLE_TYPE_SET.add(Class.class);
SIMPLE_TYPE_SET.add(BigInteger.class);
SIMPLE_TYPE_SET.add(BigDecimal.class);
}
private SimpleTypeRegistry() {
// Prevent Instantiation
}
/*
* Tells us if the class passed in is a known common type
*
* @param clazz The class to check
* @return True if the class is known
*/
public static boolean isSimpleType(Class<?> clazz) {
return SIMPLE_TYPE_SET.contains(clazz);
}
}