文章目录
- Lambda基础
- 函数式编程
- Java8新增函数式接口
- 函数式接口的使用
- 1.什么是stream?
- 2.Stream对象的创建
- 1.创建空的Stream对象
- 2 通过数组或集合类中的`stream方法`或者`parallelStream方法`创建;
- 3 通过Stream中的`of方法`创建
- 4 通过Stream中的`iterate方法`创建
- 5 通过Stream中的generate方法创建
- 6.基本类型
- 7.其他方法
- 8.通过Stream中的concat方法连接两个Stream对象生成新的Stream对象
- 9. 通过构建器生成流
- 3.Stream对象的使用
Lambda基础
Lambda 的基本结构为(arguments) -> body,有如下几种情况:
- 参数类型
可推导时,不需要指定类型,如:(a) -> System.out.println(a) - 当
只有一个参数且类型可推导时,不强制写 (), 如:a -> System.out.println(a) 参数指定类型时,必须有括号,如:(int a) -> System.out.println(a)参数可以为空,如 :() -> System.out.println("hello")body需要用{}包含语句,当只有一条语句时 {} 可省略
//外部接口
interface ILike {
void lambda();
//void lambda2(); Lambad表达式会报错
}
// 外部类
class ILikeImpl implements ILike {
@Override
public void lambda() {
System.out.println("我爱你Lambda111!!");
}
}
public class LambdaDerivation {
/**
* 静态内部类
*/
static class ILikeImpl2 implements ILike {
@Override
public void lambda() {
System.out.println("我爱你Lambda222!!");
}
}
public static void main(String[] args) {
// 外部类
ILike iLike = new ILikeImpl();
iLike.lambda();
// 静态内部类
iLike = new ILikeImpl2();
iLike.lambda();
// 方法内部类
class ILikeImpl3 implements ILike {
@Override
public void lambda() {
System.out.println("我爱你Lambda333!!");
}
}
iLike = new ILikeImpl3();
iLike.lambda();
// 匿名内部类
iLike = new ILike() {
@Override
public void lambda() {
System.out.println("我爱你Lambda444!!");
}
};
iLike.lambda();
// Lambda方式推导(接口中有多个方法不能推导)
//Lambda推导必须要有类型
iLike = ()->{
System.out.println("我爱你Lambda555!!");
};
iLike.lambda();
}
}

1.为什么要使用Lambda表达式?
- λ字母表排序第十一位的字母,英语称为 Lambda
- 避免匿名内部类过多,其实质属于函数式编程概念
- 在jdk8中使用大量的匿名内部类
2.什么是Lambda表达式
在Java程序中,我们经常遇到一大堆单方法接口,即一个接口只定义了一个方法:
ComparatorRunnableCallable
以Comparator为例,我们想要调用Arrays.sort()时,可以传入一个Comparator实例,以匿名类方式编写如下:
public static void main(String[] args) {
String[] array = new String[] { "apple", "Orange", "banana", "Lemon" };
// 请使用忽略大小写排序,并改写为方法引用:
Arrays.sort(array, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
System.out.println(String.join(", ", array));
}
上述写法非常繁琐。从Java 8开始,我们可以用 Lambda表达式替换单方法接口。改写上述代码如下:
public static void main(String[] args) {
String[] array = new String[]{"apple", "Orange", "banana", "Lemon"};
// 请使用忽略大小写排序,并改写为方法引用:
Arrays.sort(array, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
/**
* 测试lambda的语法
* (params…) -> expression
* 如果只有一个参数(params…) 的()都可以省略,
* 方法体里面如果只有一行代码,不管有没有return, 都可以省略 {}
*
* 如果有多个参数或者多行代码, (),{}就不可以省略
* (params…) -> statement
* (params…) -> {statement}
*/
Arrays.sort(array, (o1, o2) -> {
return o1.compareTo(o2);
});
Arrays.sort(array, (String o1, String o2) -> {
return o1.compareTo(o2);
});
//方法只有一行
Arrays.sort(array, (String o1, String o2) -> o1.compareTo(o2));
Arrays.sort(array, (o1, o2) -> o1.compareTo(o2));
System.out.println(String.join(", ", array));
}
观察Lambda表达式的写法,它只需要写出方法定义:
(o1, o1) -> {
return o1.compareTo(o2);
}
其中,参数是(s1, s2),参数类型可以省略,因为编译器可以自动推断出String类型。 -> { ... } 表示 方法体,所有代码写在内部即可。 Lambda表达式没有class定义,因此写法非常简洁。
如果只有一行return xxx的代码,完全可以用更简单的写法:
Arrays.sort(array, (o1, o2) -> o1.compareTo(o2));
返回值类型也是由器自动推断的,这里推断出的返回值是int,因此,只要返回int,编译器就不会报错。
3.FunctionalInterface
我们把只定义了单方法的接口称之为FunctionalInterface,用注解@FunctionalInterface标记。例如,Callable接口:
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
再来看Comparator接口:
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
}
虽然Comparator接口有很多方法,但只有 一个抽象方法int compare(T o1, T o2),其他的方法都是default方法或static方法。另外注意到boolean equals(Object obj)是Object定义的方法,不算在接口方法内。因此,Comparator也是一个FunctionalInterface。
1.Lambda推导(带参数)
//外部接口
interface ILove {
void lambda(String name);
//void lambda2(); Lambad表达式会报错
}
// 外部类
class ILoveImpl implements ILove {
@Override
public void lambda(String name) {
System.out.println("我爱你"+name+"!!");
}
}
/**
* Lambda推导 + 带参数
*/
public class LambdaDerivation2 {
public static void main(String[] args) {
ILove love = new ILoveImpl();
love.lambda("小明");
// 简化1: (只需要把参数 放到()中 + -> + {})
love = (String name1) ->{
System.out.println("我爱你"+name1+"!!");
};
love.lambda("小张");
// 简化2:(只需要把参数 放到()中 + -> + {}, 数据类型可以不需要,自己会匹配对应类型)
love = (name2) ->{
System.out.println("我爱你"+name2+"!!");
};
love.lambda("小刘");
// 简化3: 只有一个参数的情况下,括号也可以省略 (参数 + -> + {})
love = name3 -> {
System.out.println("我爱你"+name3+"!!");
};
love.lambda("小王");
// 简化4: 如果只有一行代码,{}都可以不要 (参数 + -> + 表达式)
love = name4 -> System.out.println("我爱你"+name4+"!!");
love.lambda("小欧");
}
}

2.Lambda推导(带参数+带返回值)
//外部接口
interface IInterest {
boolean lambda(String name, int age, boolean isExist);
}
// 外部类
class IInterestImpl implements IInterest {
@Override
public boolean lambda(String name, int age, boolean isExist) {
System.out.println("我叫:" + name + "我的年龄是:" + age + "!!");
return isExist;
}
}
/**
* Lambda推导 + 带参数+带返回值
*/
public class LambdaDerivation3 {
public static void main(String[] args) {
IInterest interest = new IInterestImpl();
//写法1:
interest = (String name, int age, boolean isExist) -> {
System.out.println("我叫:" + name + "我的年龄是:" + age + "!!");
return isExist;
};
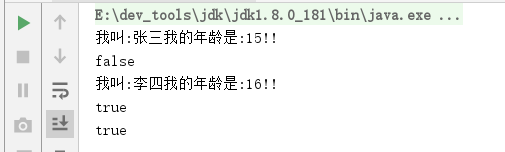
System.out.println(interest.lambda("张三", 15, false));
//写法2:不加类型
interest = (name, age, isExist) -> {
System.out.println("我叫:" + name + "我的年龄是:" + age + "!!");
return isExist;
};
System.out.println(interest.lambda("李四", 16, true));
//写法3: 两个或者两个以上参数不能省略括号,会报错
//........
//写法4:不加类型 两行或者两个以上代码不能省略 {} ,(((只有一行可以: 如返回值)))
interest = (name, age, isExist) -> isExist;
System.out.println(interest.lambda("李四", 16, true));
}
}
4.Lambda原理
import java.util.Arrays;
import java.util.List;
import java.util.function.Predicate;
public class FilterPrinciple {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1,2,3,4,18,19,20);
list.stream().filter((x) -> x >= 18).forEach(System.out::println);
}
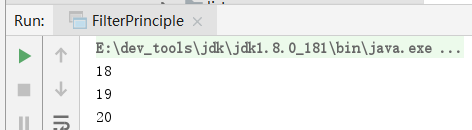
List里面保存了多个人的年龄,现在筛选出年龄大于等于18的人。
此时我们就可以用list.stream().filter((x) -> x >= 18)这就是一个典型的lambda表达式
(x) -> x >= 18 传给 Predicate 函数式接口。
原理其实是:
- JVM帮我们
动态生成了一个内部类,然后这个内部类实现了 Predicate这个函数式接口。 - 简单来说就是:
JVM动态生成一个内部类,并继承其中的抽象方法。
重写了里面的test方法。生成的类似如下:
static final class FilterPrinciple$$Lambda$1 implements Predicate<Integer> {
private FilterPrinciple$$Lambda$1() {
}
@Override
public boolean test(Integer x) {
return x >= 18;
}
}
}
5.方法引用
- 静态方法的引用
类名::方法名 - 实例方法的引用
对象实例::方法名 - 类名::方法名(使用此方法要把当前对象this作为参数进行调用)
tips:java在调用实例方法时,会默认把当前实例作为第一个参数命名为this传到非静态方法。 - 构造函数的引用
类名::new(若构造函数有参数,则把参数传进去即可)
tips:使用lambda表达式尽可能使用方法引用,不会多生成一个类似lambda$()这样的函数。
1.什么是Lambda表达式的方法引用?
使用Lambda表达式,我们就可以不必编写FunctionalInterface接口的实现类,从而简化代码:
Arrays.sort(array, (o1, o2) -> o1.compareTo(o2));
实际上,除了Lambda表达式,我们还可以直接传入方法引用,引用方法使用 :: 来调用。例如:
import java.util.Arrays;
public class TestLambdaMethodRef{
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, TestLambdaMethodRef::myCompare);
System.out.println(String.join(", ", array));
}
static int myCompare(String s1, String s2) {
return s1.compareTo(s2);
}
}
上述代码在Arrays.sort()中直接传入了静态方法myCompare的引用,用TestLambdaMethodRef::cmp表示。
- 因此,所谓方法引用,是指如果某个方法签名和接口恰好一致,就可以直接传入方法引用。
因为Comparator<String>接口定义的方法是int compare(String, String),和静态方法int myCompare(String, String)相比,除了 方法名外,方法参数一致,返回类型相同,因此,我们说两者的方法签名一致,可以直接把方法名作为Lambda表达式传入:
Arrays.sort(array, TestLambdaMethodRef::myCompare);
注意:在这里,方法签名只看参数类型和返回类型,不看方法名称,也不看类的继承关系。
2.如何引用实例方法?
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" };
Arrays.sort(array, String::compareTo);
System.out.println(String.join(", ", array));
}
}
不但可以编译通过,而且运行结果也是一样的,这说明 String.compareTo()方法也符合Lambda定义。
观察String.compareTo()的方法定义:
public final class String {
public int compareTo(String o) {
...
}
}
这个方法的签名只有一个参数,为什么和int Comparator<String>.compare(String, String)能匹配呢?
- 因为
实例方法有一个隐含的this参数,String类的compareTo()方法在实际调用的时候,第一个隐含参数总是传入this,相当于静态方法:public static int compareTo(this, String o);
所以,String.compareTo()方法也可作为方法引用传入。
3.构造方法引用?
除了可以引用静态方法和实例方法,我们还可以 引用构造方法。
我们来看一个例子:如果要把一个List<String>转换为List<Person>,应该怎么办?
-
传统的做法是先定义一个
ArrayList<Person>,然后用for循环填充这个List:List<String> names = List.of("Bob", "Alice", "Tim"); List<Person> persons = new ArrayList<>(); for (String name : names) { persons.add(new Person(name)); } -
要更简单地实现
String到Person的转换,我们可以引用Person的构造方法:
// 引用构造方法
import java.util.*;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
List<String> names = List.of("Bob", "Alice", "Tim");
List<Person> persons = names.stream().map(Person::new).collect(Collectors.toList());
System.out.println(persons);
}
}
class Person {
String name;
public Person(String name) {
this.name = name;
}
public String toString() {
return "Person:" + this.name;
}
}
后面讲到Stream的map()方法。现在我们看到,这里的map()需要传入的FunctionalInterface的定义是:
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
把泛型对应上就是方法签名Person apply(String),即传入参数String,返回类型Person。而Person类的构造方法恰好满足这个条件,因为构造方法的参数是String,而构造方法虽然没有return语句,但它会隐式地返回this实例,类型就是Person,因此,此处可以引用构造方法。
- 构造方法的引用写法是类名
::new,因此,此处传入Person::new。
4.方法引用小结
FunctionalInterface允许传入:
- 接口的实现类(传统写法,代码较繁琐);
Lambda表达式(只需列出参数名,由编译器推断类型);- 符合方法签名的
静态方法; - 符合方法签名的
实例方法(实例类型被看做第一个参数类型); - 符合方法签名的
构造方法(实例类型被看做返回类型)。 - FunctionalInterface
不强制继承关系,不需要方法名称相同,只要求方法参数(类型和数量)与方法返回类型相同,即认为方法签名相同。
6.小结
-
单方法接口被称为
FunctionalInterface。 -
接收FunctionalInterface作为参数的时候,可以把实例化的匿名类改写为Lambda表达式,能大大简化代码。 -
Lambda表达式的
参数和返回值均可由编译器自动推断。
函数式编程
1.什么是函数式编程
Java的方法分为实例方法,例如Integer定义的equals()方法:
public final class Integer {
boolean equals(Object o) {
//...
}
}
以及静态方法,例如Integer定义的parseInt()方法:
public final class Integer {
public static int parseInt(String s) {
...
}
}
无论是实例方法,还是静态方法,本质上都相当于过程式语言的函数。例如C函数:
char* strcpy(char* dest, char* src)
只不过Java的实例方法隐含地传入了一个this变量即实例方法总是有一个隐含参数this。
函数式编程(Functional Programming)是把方法作为基本运算单元,方法可以作为变量,可以接收方法,还可以返回方法·。历史上研究函数式编程的理论是Lambda演算,所以我们经常把支持函数式编程的编码风格称为Lambda表达式。
1.什么是函数式接口
它指的是有且只有一个未实现的方法的接口,一般通过FunctionalInterface注解来表明某个接口是一个函数式接口。函数式接口是Java支持函数式编程的基础。
下面jdk1.8里面对函数式编程的定义。只是一个 FunctionalInterface 接口。特别的简单。
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface FunctionalInterface {}
这个函数式接口有几点以下的限制:
唯一的抽象方法,有且仅有一个 (即所有的函数式接口,有且只能有一个抽象方法)- 加上该注解,则会触发
JavaCompiler的检查。对于符合函数接口的接口,加不加都无关紧要,但是加上则会提供一层编译检查的保障。如果不符合,则会报错。 - 不能被重写之后,再声明为抽象方法,则不算抽象方法。例如接口实现了Object中的方法。
- 可用于lambda类型的使用方式
2.函数式编程特点
- 函数可以作为变量、参数、返回值和数据类型。
- 基于表达式来替代方法的调用
- 函数无状态,可以并发和独立使用
- 函数无副作用,不会修改外部的变量
- 函数结果确定性;同样的输入,必然会有同样的结果。
2.Java8函数式编程语法入门
Java8中函数式编程语法能够精简代码。
- 使用
Consumer作为示例,它是一个函数式接口,包含一个抽象方法accept,这个方法只有输入而无输出。
现在我们要定义一个Consumer对象,传统的方式是这样定义的:
Consumer c = new Consumer() {
@Override
public void accept(Object o) {
System.out.println(o);
}
};
而在Java8中,针对函数式编程接口,可以这样定义:
Consumer c = (o) -> {
System.out.println(o);
};
- 上面已说明,函数式编程接口都只有一个抽象方法,因此在采用这种写法时,
编译器会将这段函数编译后当作该抽象方法的实现。 - 如果接口有
多个抽象方法,编译器就不知道这段函数应该是实现哪个方法的了。- 因此,
Consumer c = ...后面的函数体我们就可以看成是accept函数的实现。
- 因此,
- 输入:
->前面的部分,即被()包围的部分。此处只有一个输入参数,实际上输入是可以有多个的,如两个参数时写法:(a, b);当然也可以没有输入,此时直接就可以是()。- 函数体:
->后面的部分,即被{}包围的部分;可以是一段代码。- 输出:
函数式编程可以没有返回值,也可以有返回值。如果有返回值时,需要代码段的最后一句通过return返回对应的值。
当函数体中只有一个语句时,可以去掉{}进一步简化:
Consumer c = (o) -> System.out.println(o);
然而这还不是最简的,由于此处只是进行打印,调用了System.out中的println静态方法对输入参数直接进行打印,因此可以简化成以下写法:
Consumer c = System.out::println;
//它表示的意思就是针对输入的参数将其调用System.out中的静态方法println进行打印。
通过这段代码,可以简单的理解函数式编程
- Consumer接口直接就可以当成一个函数了,这个函数接收一个输入参数,然后针对这个输入进行处理
- 其
本质上仍然是一个对象,但我们已经省去了诸如老方式中的对象定义过程,直接使用一段代码来给函数式接口对象赋值。 - 最为关键的是,这个函数式对象因为本质上仍旧是一个对象,因此可以做为其它方法的参数或者返回值,可以与原有的代码实现无缝集成!
Java8新增函数式接口
Stream的操作是建立在函数式接口的组合之上的。Java8中新增的函数式接口都在java.util.function包下。这些函数式接口可以有多种分类方式。
1.Consumer
-
Consumer是从
T到void的一元函数,接受一个入参但不返回任何结果的操作。 -
Consumer的意思就是 “消费” ,即
针对某个东西我们来使用它,因此它包含有一个有输入而无输出的accept接口方法;以及一个默认的andThen方法;
Consumer最常用的是 default void forEach(Consumer<? super T> action) {}
- forEach并不返回任何值。只是循环。
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
andThen()方法就是指定在 调用当前Consumer后是否还要调用其它的Consumer;
测试案例
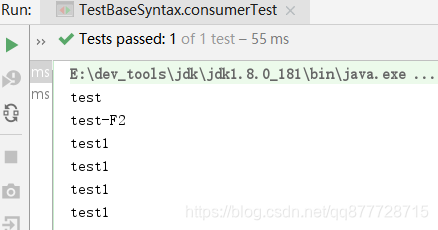
@Test
public void consumerTest() {
Consumer f = System.out::println;
Consumer f2 = n -> System.out.println(n + "-F2");
//执行完F后再执行F2的Accept方法
f.andThen(f2).accept("test");
//连续执行F的Accept方法
f.andThen(f).andThen(f).andThen(f).accept("test1");
}
2.Function
-
Function是从 T到R的一元映射函数。将参数T传递给一个函数,返回R。即R = Function(T)
-
Function的意思就是
“函数”,而函数通常是有输入输出的,因此它含有一个apply方法,包含一个输入与一个输出;除apply方法外,它还有compose与andThen及indentity三个方法- Function最常用的应该是
<R> Stream<R> map(Function<? super T, ? extends R> mapper); - 比如
List<Person>person里面有age,name… 我传入age,他就会返回age的集合给我。
- Function最常用的应该是
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
测试案例
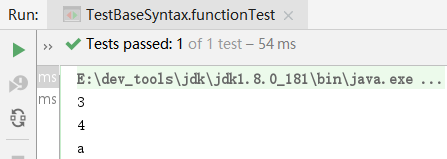
@Test
public void functionTest() {
Function<Integer, Integer> f = s -> s+1;
Function<Integer, Integer> g = s -> s * 2;
/**
* 下面表示在执行F时,先执行G,并且执行F时使用G的输出当作输入。
* 相当于以下代码:
* Integer a = g.apply(1);
* System.out.println(f.apply(a));
*/
System.out.println(f.compose(g).apply(1)); // 3
/**
* 表示执行F的Apply后使用其返回的值当作输入再执行G的Apply;
* 相当于以下代码
* Integer a = f.apply(1);
* System.out.println(g.apply(a));
*/
System.out.println(f.andThen(g).apply(1)); // 4
/**
* identity方法会返回一个不进行任何处理的Function,即输出与输入值相等;
*/
System.out.println(Function.identity().apply("a")); // a
}
3.Predicate
-
Predicate是一个
谓词函数,主要作为一个谓词演算推导真假值存在,返回布尔值的函数。Predicate等价于一个Function的boolean型返回值的子集。 -
Predicate的意思是**“断定”**,即
判断的意思,判断某个东西是否满足某种条件; 因此它包含test方法,根据输入值来做逻辑判断,其结果为True或者False。-
predicate最常用的莫过于
Stream<T> filter(Predicate<? super T> predicate); -
比如我要过滤年龄 > 18 的人,我传入age,判断是否为true。为true则保留,false丢弃。
-
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
default Predicate<T> negate() {
return (t) -> !test(t);
}
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
测试案例
@Test
public void predicateTest() {
Predicate<String> p = o -> o.equals("test");
Predicate<String> g = o -> o.startsWith("t");
/**
* negate: 用于对原来的Predicate做取反处理;
* 如:当调用p.test("test")为True时,调用p.negate().test("test")就会是False;
*/
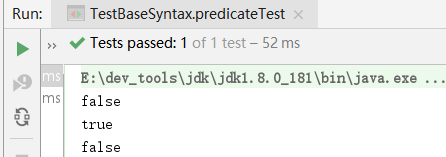
System.out.println(p.negate().test("test"));//false
/**
* and: 针对同一输入值,多个Predicate均返回True时返回True,否则返回False;
* 如: p.test("test") ==true && g.test("test") ==true
*/
System.out.println(p.and(g).test("test"));//true
/**
* or: 针对同一输入值,多个Predicate只要有一个返回True则返回True,否则返回False
* 如: p.test("test") ==true && g.test("test") ==true
*/
System.out.println(p.or(g).test("ta"));//false
}
Java 常用函数式接口 —— Predicate接口
Java 常用函数式接口 —— Supplier接口
函数式接口的使用
通过Stream以及Optional两个类,可以进一步利用函数式接口来简化代码。
1.什么是stream?
-
Stream操作简称
流操作,这里的流与IO流毫无关系,这里的流指的是流式操作,就是 流水线操作 -
Stream流操作主要包包括三大模块:
创建流操作、中间流操作、终结流操作。创建流主要是创建Stream对象。每个Stream对象只能使用一次终结操作。中间流操作指的是各种中间流操作方法,比如去重、过滤、排序等终结流操作指的结果操作,终结操作的目的是产生最终结果。
2.Stream对象的创建
1.创建空的Stream对象
Stream stream = Stream.empty();
2 通过数组或集合类中的stream方法或者parallelStream方法创建;
第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:
import java.util.*;
import java.util.stream.*;
public class CreateStreamByArrAndCollection{
public static void main(String[] args) {
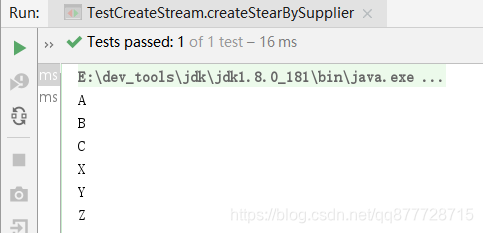
Stream<String> stream1 = Arrays.stream(new String[] { "A", "B", "C" });
Stream<String> stream2 = Arrays.asList("X", "Y", "Z").stream();
stream1.forEach(System.out::println);
stream2.forEach(System.out::println);
}
}
- 把数组变成Stream使用
Arrays.strem()方法。 - 对于
Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream。- 上述创建Stream的方法都是
把一个现有的序列变为Stream,它的元素是固定的。
- 上述创建Stream的方法都是
3 通过Stream中的of方法创建
创建Stream最简单的方式是直接用Stream.of()静态方法,传入可变参数,即创建了一个能输出确定元素的Stream:
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Stream<String> stream = Stream.of("A", "B", "C", "D");
// forEach()方法相当于内部循环调用,
// 可传入符合Consumer接口的void accept(T t)的方法引用:
stream.forEach(System.out::println);
}
}
使用Stream.of
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CreateStreamByOf {
/**
* 使用Stream创建List
*/
@Test
public void testOfCreateList() {
List<String> userList = Stream.of("张一","张二","张三").collect(Collectors.toList());
//使用符合方法签名的System.out.println方法
//userList.forEach(System.out :: println);
userList.forEach((str) -> {
System.out.println(str);
});
}
/**
* 使用Stream创建Set
*/
@Test
public void testOfCreateSet() {
Set<String> userSet = Stream.of("张一","张二","张三").collect(Collectors.toSet());
//使用符合方法签名的System.out.println方法
//userList.forEach(System.out :: println);
userSet.forEach((str) -> {
System.out.println(str);
});
}
/**
* 创建Stream最简单的方式是直接用`Stream.of()静态方法`,`传入可变参数`,即**创建了一个能输出确定元素的Stream
*/
@Test
public void testOfCreateMap() {
//将集合List<User>转换为 Map集合, key为user.uuid value为 user.userName
Map<String,String> userMap = Stream.of(new User("111","张一"),
new User("222","张二"),
new User("333","张三"))
.collect(Collectors.toMap(User::getUuid,User::getUserName));
//使用外部符合方法签名的静态方法
// userMap.forEach(CreateStreamByOf ::printMap);
//直接使用lambda表达式
/* userMap.forEach( (str1,str2) -> {
System.out.println(str1+"---------"+str2);
});*/
}
static void printMap (String str1,String str2) {
System.out.println(str1+"---------"+str2);
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class User {
private String uuid;
private String userName;
}
虽然这种方式基本上没啥实质性用途,但测试的时候很方便。
4 通过Stream中的iterate方法创建
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f);
public static<T> Stream<T> iterate(T seed, Predicate<? super T> hasNext, UnaryOperator<T> next)
- 第一个方法: 将会返回一个无限有序值的Stream对象:
- 它的第一个参数是seed,第二个参数是
f.apply(seed);第N个元素是f.apply(n-1个元素的值);生 成无限值的方法实际上与Stream的中间方法类似,在遇到中止方法前一般是不真正的执行的。因此无限值的这个方法一般与limit方法一起使用,来获取前多少个元素。 - 当然
获取前多少个元素也可以使用第二个方法。
- 它的第一个参数是seed,第二个参数是
第一种方法使用示例
/* Stream.iterate(1, new UnaryOperator<Integer>() {
@Override
public Integer apply(Integer integer) {
return integer+1;
}
}).forEach(System.out::println);*/
Stream.iterate(1, n -> n + 1).forEach(System.out::println);
- 第二个方法: 与第一个方法生成元素的方式类似,不同的是
它返回的是一个有限值的Stream;中止条件是由hasNext来断定的。
第二种方法的使用实例:
/**
* 本示例表示从1开始组装一个序列,第一个是1,第二个是1+1即2,第三个是2+1即3..,直接10时中止
*/
/*Stream.iterate(1,
new Predicate<Integer>() {
@Override
public boolean test(Integer integer) {
return integer <= 10;
}
},
new UnaryOperator<Integer>() {
@Override
public Integer apply(Integer integer) {
return integer+1;
}
}).forEach(System.out::println);
*/
//Stream.iterate(1, n -> n <= 10, n -> n+1).forEach(System.out::println);
5 通过Stream中的generate方法创建
创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:
Stream<String> s = Stream.generate(Supplier<String> sp);
- 基于
Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。
我们编写一个能不断生成自然数的Supplier,它的代码非常简单,每次调用get()方法,就生成下一个自然数:
import java.util.function.*;
import java.util.stream.*;
public class CreateStreamBySupplier{
public static void main(String[] args) {
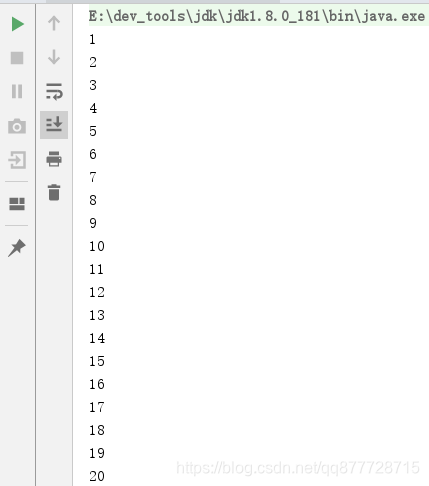
Stream<Integer> natual = Stream.generate(new NatualSupplier());
// 注意:无限序列必须先变成有限序列再打印:
natual.limit(20).forEach(System.out::println);
}
}
class NatualSupplier implements Supplier<Integer> {
int n = 0;
@Override
public Integer get() {
n++;
return n;
}
}
上述代码我们用一个Supplier<Integer>模拟了一个无限序列(当然受int范围限制不是真的无限大)。如果用List表示,即便在int范围内,也会占用巨大的内存,而Stream几乎不占用空间,因为每个元素都是实时计算出来的,用的时候再算。
- 对于
无限序列,如果直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题。
6.基本类型
因为Java的范型不支持基本类型,所以我们无法用Stream<int>这样的类型,会发生编译错误。为了保存int,只能使用String<Integer>,但这样会产生频繁的装箱、拆箱操作。
- 为了提高效率,Java标准库提供了
IntStream、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和泛型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:
import org.junit.Test;
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.LongStream;
public class CreateStreamByBaseDataType {
@Test
public void testCreateStreamByBaseDataType() {
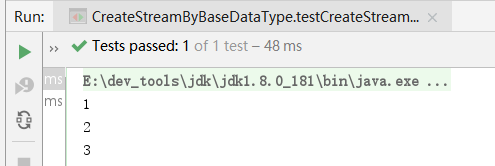
// 将int[]数组变为IntStream:
IntStream is = Arrays.stream(new int[]{1, 2, 3});
// 将Stream<String>转换为LongStream:
LongStream ls = Arrays.asList("1", "2", "3").stream().mapToLong(Long::parseLong);
ls.forEach(System.out :: println);
}
}
7.其他方法
创建Stream的第三种方法是通过一些API提供的接口,直接获得Stream。
例如,Files类的lines()方法可以文件变成一个Stream,每个元素代表文件的一行内容:
import org.junit.Test;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Stream;
public class CreateStreamByFile {
@Test
public void testCreateStreamByFile () {
try (Stream<String> lines = Files.lines(Paths.get("testRandom.txt"))) {
lines.forEach(System.out :: println);
} catch (IOException e) {
e.printStackTrace();
}
}
}
此方法对于按行遍历文本文件十分有用。
正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组:
import org.junit.Test;
import java.util.regex.Pattern;
import java.util.stream.Stream;
public class CreateStreamByPattern {
@Test
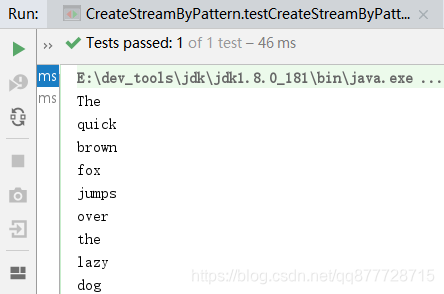
public void testCreateStreamByPattern() {
Pattern p = Pattern.compile("\\s+");
Stream<String> stream = p.splitAsStream("The quick brown fox jumps over the lazy dog");
stream.forEach(System.out::println);
}
}
8.通过Stream中的concat方法连接两个Stream对象生成新的Stream对象
9. 通过构建器生成流
@Test
public void createBuilderStream() {
// 通过构建器生成流
Stream<Object> s4 = Stream.builder().add("123").add("321").add("444").add("@21").build();
}
3.Stream对象的使用
1. 基本方法
Stream对象提供多个非常有用的方法,这些方法可以分成两类:
- 中间操作:
将原始的Stream转换成另外一个Stream;如filter返回的是过滤后的Stream。 - 终端操作:
产生的是一个结果或者其它的复合操作;如count或者forEach操作。
1.流中间操作
这里的流中间操作指的是该操作的返回值仍然是流。
| 方法 | 说明 |
|---|---|
| sequential | 返回一个相等的串行的Stream对象,如果原Stream对象已经是串行就可能会返回原对象 |
| parallel | 返回一个相等的并行的Stream对象,如果原Stream对象已经是并行的就会返回原对象 |
| unordered | 返回一个不关心顺序的Stream对象,如果原对象已经是这类型的对象就会返回原对象 |
| onClose | 返回一个相等的Steam对象,同时新的Stream对象在执行Close方法时会调用传入的Runnable对象 |
| close | 关闭Stream对象 |
| filter | 元素过滤:对Stream对象按指定的Predicate进行过滤,返回的Stream对象中仅包含未被过滤的元素 |
| map | 元素一对一转换:使用传入的Function对象对Stream中的所有元素进行处理,返回的Stream对象中的元素为原元素处理后的结果 |
| mapToInt | 元素一对一转换:将原Stream中的使用传入的IntFunction加工后返回一个IntStream对象 |
| flatMap | 元素一对多转换:对原Stream中的所有元素进行操作,每个元素会有一个或者多个结果,然后将返回的所有元素组合成一个统一的Stream并返回; |
| distinct | 去重:返回一个去重后的Stream对象 |
| sorted | 排序: 表示对流中的元素进行排序,需要使用Conparable和Comparator |
| peek | 使用传入的Consumer对象对所有元素进行消费后,返回一个新的包含所有原来元素的Stream对象 |
| limit | 用于从首个元素开始截取N个元素,组成新stream返回 |
| skip | skip表示放弃N个元素,将剩余元素组成新stream返回 |
| takeWhile | 如果Stream是有序的(Ordered),那么返回最长命中序列(符合传入的Predicate的最长命中序列)组成的Stream;如果是无序的,那么返回的是所有符合传入的Predicate的元素序列组成的Stream。 |
| dropWhile | 与takeWhile相反,如果是有序的,返回除最长命中序列外的所有元素组成的Stream;如果是无序的,返回所有未命中的元素组成的Stream。 |
| peek | 针对流中的每个元素执行操作action |
| mapToInt | 返回通过给定mapper作用于当前流的每个元素之后的结果组成的新的Int流 |
| mapToLong | 返回通过给定mapper作用于当前流的每个元素之后的结果组成的新的Long流 函数 |
| mapToDouble | 返回通过给定mapper作用于当前流的每个元素之后的结果组成的新的Double流 |
| flatMapToInt | 根据给定的mapper作用于当前流的每个元素,将结果组成新的Long流来返回 |
| flatMapToLong | 根据给定的mapper作用于当前流的每个元素,将结果组成新的Long流来返回 |
| flatMapToDouble | 根据给定的mapper作用于当前流的每个元素,将结果组成新的Double流来返回 |
mapToInt、mapToLong、mapToDouble方法是map方法的扩展,其参数分别为ToIntFunction、ToLongFunction、ToDoubleFunction,分别接口一个参数,返回指定类型的值,分别为int、long、double,那么定义方法的时候就要注意返回值的类型了,必须一致,最后组成的新流就是一个int或long或double元素流(IntStream、LongStream、DoubleStream)。
2.流终结操作
| 方法 | 说明 |
|---|---|
| iterator | 返回Stream中所有对象的迭代器; |
| spliterator | 返回对所有对象进行的spliterator对象 |
| forEach | 对所有元素进行迭代处理,无返回值 |
| forEachOrdered | 如果有序,则按序遍历流中元素,针对每个元素执行指定操作 |
| forEachOrdered | 按Stream的Encounter所决定的序列进行迭代处理,无返回值 |
| toArray | 返回一个包含流中所有元素的数组,可以返回指定类型的数组 |
| reduce | 使用一个初始化的值,与Stream中的元素一一做传入的二合运算后返回最终的值。每与一个元素做运算后的结果,再与下一个元素做运算。它不保证会按序列执行整个过程。 |
| collect | 根据传入参数做相关汇聚计算 |
| min | 返回所有元素中最小值的Optional对象;如果Stream中无任何元素,那么返回的Optional对象为Empty |
| max | 与Min相反 |
| count | 所有元素个数 |
| anyMatch | 只要其中有一个元素满足传入的Predicate时返回True,否则返回False |
| allMatch | 所有元素均满足传入的Predicate时返回True,否则False |
| noneMatch | 所有元素均不满足传入的Predicate时返回True,否则False |
| findFirst | 返回第一个元素的Optioanl对象;如果无元素返回的是空的Optional; 如果Stream是无序的,那么任何元素都可能被返回。 |
| findAny | 返回任意一个元素的Optional对象,如果无元素返回的是空的Optioanl。 |
| isParallel | 判断是否当前Stream对象是并行的 |
T reduce(T identity, BinaryOperator<T> accumulator)以给定初始值为基础归纳流中元素,返回一个值Optional<T> reduce(BinaryOperator<T> accumulator)直接归纳流中的元素,返回一个封装有结果的Optional<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner)以给定的初始值为基础,(并行)归纳流中元素,最后将各个线程的结果再统一归纳,返回一个值<R, A> R collect(Collector<? super T, A, R> collector)根据给定的收集器收集元素<R> R collect(Supplier<R> supplier,BiConsumer<R, ? super T> accumulator,BiConsumer<R, R> combiner)根据给定的各个参数归纳元素
2 常用方法使用
我们把Stream提供的操作分为两类:转换操作和聚合操作
1.filter:过滤
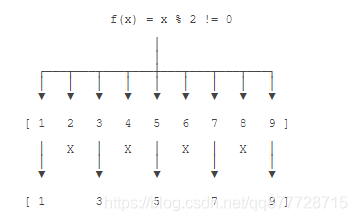
- 所谓filter()操作,就是对一个Stream的所有元素一一进行测试,
不满足条件的就被“滤掉”了,剩下的满足条件的元素就构成了一个新的Stream。
例如: 对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x) = x % 2 != 0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5:
用IntStream写出上述逻辑,代码如下:
import org.junit.Test;
import java.util.Arrays;
import java.util.stream.IntStream;
public class TestFilterStream {
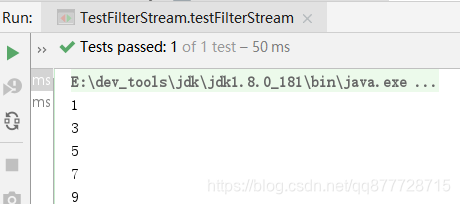
@Test
public void testFilterStream() {
IntStream intStream = Arrays.stream(new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9});
//测试Stream.map()的效果
/* intStream.map((n) -> {
return n + 1;
}).forEach((n) -> {
System.out.println(n);
});*/
//intStream.map((n) -> n - 1).forEach(System.out :: println);
//过滤掉不满足条件 n % 2 != 0 的元素, 剩下的元素返回一个新的stream
intStream.filter((n) -> n % 2 != 0).forEach(System.out :: println);
}
}
filter()方法接收的对象是Predicate接口对象,它定义了一个test()方法,负责判断元素是否符合条件:
@FunctionalInterface
public interface Predicate<T> {
// 判断元素t是否符合条件:
boolean test(T t);
}
filter()除了常用于数值外,也可应用于任何Java对象。
- 2.Java中使用fileter()
例如: 从一组给定的LocalDate中过滤掉工作日,以便得到休息日:
import java.time.*;
import java.util.function.*;
import java.util.stream.*;
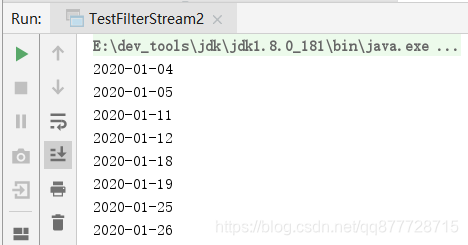
public class TestFilterStream2{
public static void main(String[] args) {
//打印2020年一月份所有星期六星期天
Stream.generate(new LocalDateSupplier())
.limit(31)//自增31天
.filter(ldt -> ldt.getDayOfWeek() == DayOfWeek.SATURDAY || ldt.getDayOfWeek() == DayOfWeek.SUNDAY)//保留所有星期六/星期天的日期
.forEach(System.out::println);//遍历打印
}
}
//无限自增日期
class LocalDateSupplier implements Supplier<LocalDate> {
LocalDate start = LocalDate.of(2020, 1, 1);
int n = -1;
@Override
public LocalDate get() {
n++;
return start.plusDays(n);
}
}
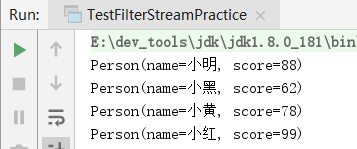
过滤出成绩及格的同学,并打印出名字。
import lombok.Data;
import java.util.Arrays;
import java.util.List;
public class TestFilterStreamPractice {
public static void main(String[] args) {
List<Person> personList = Arrays.asList(
new Person("小明", 88),
new Person("小黑", 62),
new Person("小白", 45),
new Person("小黄", 78),
new Person("小红", 99),
new Person("小林", 58));
// 请使用filter过滤出及格的同学,然后打印名字:
personList.stream().filter((person) -> person.getScore() > 60).forEach(System.out::println);
}
}
@Data
class Person {
String name;
int score;
Person(String name, int score) {
this.name = name;
this.score = score;
}
}
2.map:映射
map 是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream ,即:将一个Stream的每个元素 映射成另一个元素并`转换成一个新的Stream。
-
所谓map操作,就是把一种
操作运算,映射到一个序列的每一个元素上。 -
可以将
一种元素类型转换成另一种元素类型。 -
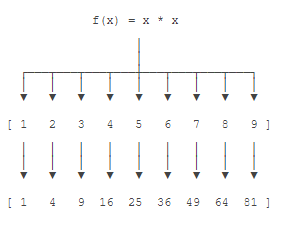
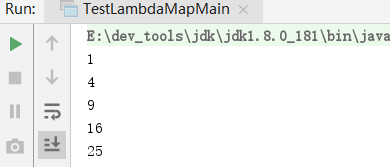
例如,对x计算它的平方,可以使用函数f(x) = x * x。我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16,25:
Stream<Integer> s = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> s2 = s.map(n -> n * n);
s2.forEach(System.out::println);
map()方法接收的对象是Function接口对象,它定义了一个apply()方法,负责把一个T类型转换成R类型:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
- Java中使用Map
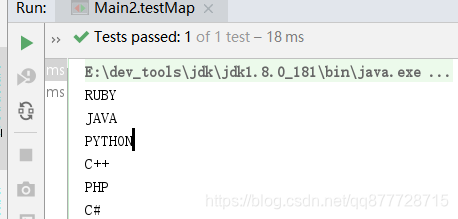
利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:
@Test
public void testMap() {
//1.创建一个Stream<String>并转换为List<String>
List<String> listResult = Stream.of(" java ", " python ", "C++", "php", "c#").collect(Collectors.toList());
listResult.add(0, "ruby");
//3.将List转换为stream然后通过Map,去空格以及转换成大写
List<String> strStream = listResult.stream()
.map(String::toUpperCase)//转大写
.map(String::trim)//去空格
.collect(Collectors.toList());// 转集合
//打印集合
strStream.forEach(System.out::println);
}
3.reduce
map()和filter()都是Stream的转换方法,而 Stream.reduce() 则是Stream的一个聚合方法,它可以 把一个Stream的所有元素按照聚合函数聚合成一个结果。
我们来看一个简单的聚合方法:
import java.util.stream.Stream;
public class TestReduceStream {
public static void main(String[] args) {
int sum = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (acc, n) -> acc + n);
System.out.println(sum); // 45
}
}
reduce()方法传入的对象是BinaryOperator接口,它定义了一个apply()方法,负责把上次累加的结果和 本次的元素进行运算,并返回累加的结果:
@FunctionalInterface
public interface BinaryOperator<T> {
// BI操作:两个输入,一个输出
T apply(T t, T u);
}
上述代码看上去不好理解,但我们用for循环改写一下,就容易理解了:
Stream<Integer> stream = ...
int sum = 0;
for (n : stream) {
sum = (sum, n) -> sum + n;
}
可见,reduce()操作首先初始化结果为指定值(这里是0),紧接着,reduce()对每个元素依次调用(acc, n) -> acc + n,其中,acc是上次计算的结果:
// 计算过程:
acc = 0 // 初始化为指定值
acc = acc + n = 0 + 1 = 1 // n = 1
acc = acc + n = 1 + 2 = 3 // n = 2
acc = acc + n = 3 + 3 = 6 // n = 3
acc = acc + n = 6 + 4 = 10 // n = 4
acc = acc + n = 10 + 5 = 15 // n = 5
acc = acc + n = 15 + 6 = 21 // n = 6
acc = acc + n = 21 + 7 = 28 // n = 7
acc = acc + n = 28 + 8 = 36 // n = 8
acc = acc + n = 36 + 9 = 45 // n = 9
因此,实际上这个reduce()操作是一个求和。
如果去掉初始值,我们会得到一个Optional<Integer>:
Optional<Integer> opt = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce((acc, n) -> acc + n);
if (opt.isPresent()) {
System.out.println(opt.get());
}
这是因为Stream的元素有可能是0个,这样就没法调用reduce()的聚合函数了,因此返回Optional对象,需要进一步判断结果是否存在。
使用reduce进行求积运算
public static void main(String[] args) {
int count = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(1, (acc, n) -> acc * n);
System.out.println(count ); // 362880
}
注意:计算求积时,初始值必须设置为1
除了可以对数值进行累积计算外,灵活运用reduce()也可以对Java对象进行操作。
下面的代码演示了如何将配置文件的每一行配置通过map()和reduce()操作聚合成一个Map<String, String>:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
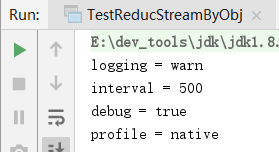
public class TestReducStreamByObj {
public static void main(String[] args) {
// 按行读取配置文件:
List<String> props = Stream.of("profile=native", "debug=true", "logging=warn", "interval=500").collect(Collectors.toList());
Map<String, String> map = props.stream()
//将每一个Stream<String>类型的元素转换为 Stream<Map<String,String>>类型
.map(str -> {
//切分
String[] strArr = str.split("\\=", 2);
//将当前Stream类型转换为 Stream<Map<String,String>>类型
Map<String, String> hashMap = new HashMap<>();
hashMap.put(strArr[0],strArr[1]);
return hashMap;
})
// 初始化聚合容器为HashMap<String, String>, 把 Stream<Map<String,String>>所有元素聚合到一个HashMap中
.reduce(new HashMap<String, String>(), (lastMap, currentMap) -> {
lastMap.putAll(currentMap);
return lastMap;
});
// 打印结果:
map.forEach((k, v) -> {
System.out.println(k + " = " + v);
});
}
}
执行结果
- 3.小结
-
reduce()方法将一个Stream的每个元素依次作用于BinaryOperator,并将结果合并。 -
reduce()是聚合方法,聚合方法会立刻对Stream进行计算。
-
4.排序:sorted
对Stream的元素进行排序十分简单,只需调用sorted()方法:
//此方法要求Stream的每个元素必须实现Comparable接口,并返回一个新的Stream。
Stream<T> sorted();
//此方法要求传入一个比较器Comparaotr进行自定义排序,并返回一个新的Stream。
Stream<T> sorted(Comparator<? super T> comparator);
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
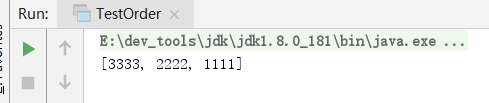
public class TestOrder {
public static void main(String[] args) {
List<String> list = Arrays.asList("2222", "3333", "1111")
.stream()
.sorted((n1, n2) -> n2.compareTo(n1))//使用比较器倒序
.collect(Collectors.toList());
System.out.println(list);
}
}
5.去重:distinct
对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():
- distinct() 判断元素是否相同是通过
equals()进行比较 - distinct()也是一个转换操作,将返回一个新的stream‘’
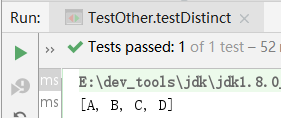
List<String> list = Arrays.asList("A", "B", "A", "C", "B", "D")
.stream()
.distinct()
.collect(Collectors.toList()); // [A, B, C, D]
System.out.println(list);
6.截取:limit/skip
截取操作常用于把一个无限的Stream转换成有限的Stream
- skip(): 用于跳过当前Stream的前N个元素
- limit() : 用于截取当前Stream最多前N个元素:
- 截取操作也是一个转换操作,将返回新的Stream。
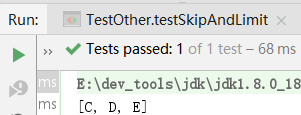
List<String> list = Arrays.asList("A", "B", "C", "D", "E", "F")
.stream()
.skip(2) // 跳过A, B
.limit(3) // 截取C, D, E
.collect(Collectors.toList()); // [C, D, E]
System.out.println(list);
7.合并:concat
将两个Stream合并为一个Stream可以使用Stream的静态方法concat():
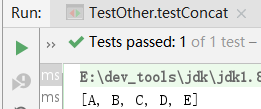
Stream<String> s1 = Arrays.asList("A", "B", "C").stream();
Stream<String> s2 = Arrays.asList("D", "E").stream();
// 合并:
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]
8.一对多转换:flatMap
对原Stream中的所有元素使用传入的Function进行处理,每个元素经过处理后生成一个多个元素的Stream对象,然后将返回的所有Stream对象中的所有元素组合成一个统一的Stream并返回;
方法定义如下:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
如果Stream的元素是集合:
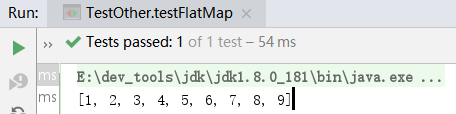
Stream<List<Integer>> streamList = Stream.of(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9));
而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():
Stream<Integer> intStream = streamList .flatMap(list -> list.stream());
List<Integer> intList = intStream.collect(Collectors.toList());
所谓flatMap(),是指把Stream的每个元素(这里是List)映射为Stream,然后 合并成一个新的Stream:

9. 并行:parallel
通常情况下,Stream对元素进行处理是单线程的,即 一个一个元素进行处理。但是很多时候,我们希望可以 并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。
- 把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用
parallel()进行转换:
Stream<String> s = Stream.of("1","2");
String[] result = s.parallel() // 变成一个可以并行处理的Stream
.sorted() // 可以进行并行排序
.toArray(String[]::new);
经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。 不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。
10.输出为List
reduce()只是一种聚合操作,如果我们希望把Stream的元素保存到集合,例如List,因为List的元素是确定的Java对象,因此把Stream变为List 不是一个转换操作,而是一个聚合操作,它会强制Stream输出每个元素。
将一组String先过滤掉空字符串,然后把非空字符串保存到List中:
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestToList {
public static void main(String[] args) {
Stream<String> stream = Stream.of("Apple", "", null, "Pear", " ", "Orange");
List<String> list = stream.map(str -> {// 去除字符串空格
return str != null ? str.trim() : null;
}).filter(s -> s != null && !s.isEmpty())// 保留非空字符串
.collect(Collectors.toList());// 转换成List
System.out.println(list);
}
}

把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中(实际上是ArrayList)。
- 类似的,
collect(Collectors.toSet())可以把Stream的每个元素收集到Set中。
11.输出为数组
把Stream的元素输出为数组和输出为List类似,我们只需要调用 toArray() 方法,并 传入数组的“构造方法”:
import java.util.Arrays;
import java.util.List;
public class TestToArr {
public static void main(String[] args) {
List<String> list = Arrays.asList("Apple", "Banana", "Orange");
//调用Steam.toArray()
String[] array = list.stream().toArray(String[]::new);
System.out.println(Arrays.toString(array));
}
}

注意到传入的“构造方法” 是 String[]::new ,它的签名实际上是IntFunction<String[]>定义的String[] apply(int),即传入int参数,获得String[]数组的返回值。
12.输出为Map
如果我们要把Stream的元素收集到Map中,就稍微麻烦一点。
因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:
import lombok.Data;
import org.junit.Test;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestToMap {
/**
* list字符串对象集合转Map
*/
@Test
public void listToMap() {
Stream<String> fruitStream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, String> fruitMap = fruitStream.collect(
Collectors.toMap(
// 把元素s映射为key:
s -> s.substring(0, s.indexOf(':')),
// 把元素s映射为value:
s -> s.substring(s.indexOf(':') + 1))
);
fruitMap.forEach(( k,v) -> {
System.out.println(k+"------"+v);
});
//MSFT------Microsoft
//APPL------Apple
}
/**
* list对象集合转Map
*/
@Test
public void objToMap() {
Stream<User> streamList =Stream.of(
new User("小明", 88),
new User("小黑", 62),
new User("小白", 45),
new User("小黄", 78),
new User("小红", 99),
new User("小林", 58));
// Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft");
Map<String, Integer> userMap = streamList.collect(
Collectors.toMap(
// 把元素s映射为key:
user -> user.getName(),
// 把元素s映射为value:
user -> user.getScore())
);
userMap.forEach(( k,v) -> {
System.out.println(k+"------"+v);
});
/*
小林------58
小明------88
小白------45
小红------99
小黑------62
小黄------78*/
}
}
@Data
class User {
String name;
int score;
User(String name, int score) {
this.name = name;
this.score = score;
}
}
13.分组输出
Stream还有一个强大的分组功能,可以按组输出
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class TestGroupOut {
@Test
public void testGroupOut () {
List<String> list = Arrays.asList("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots");
Map<String, List<String>> groups = list.stream()
.collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList()));
groups.forEach( (k,v) -> {
System.out.println(k + "-----"+ v);
});
}
}
可见,结果一共有3组,按"A","B","C"分组,每一组都是一个List。
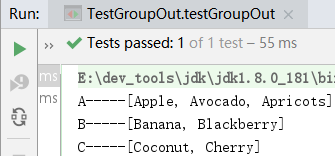
分组输出使用Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里
使用s -> s.substring(0, 1), 表示只要首字母相同的String分到一组, 第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List
如果我们有一个Stream<Student>,利用分组输出,可以非常简单地按年级或班级把Student归类。
import lombok.AllArgsConstructor;
import lombok.Data;
import org.assertj.core.util.Lists;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class GroupOutDemo {
public static void main(String[] args) {
//如果我们有一个Stream<Student>,利用分组输出,可以非常简单地按年级或班级把Student归类。
Student student1 = new Student(1,1,"张三",78);
Student student2 = new Student(2,2,"李四",58);
Student student3 = new Student(3,1,"小明",88);
Student student4 = new Student(1,2,"小王",69);
Student student5 = new Student(2,1,"小朱",99);
Student student6 = new Student(3,2,"小苟",43);
List<Student> studentList = Lists.list(student1,student2,student3,student4,student5,student6);
//根据年级分组
Map<Integer,List<Student>> studentMap = studentList.stream().collect(Collectors.groupingBy( stu -> stu.getGradeId(), Collectors.toList()));
//根据班级分组
//Map<Integer,List<Student>> studentMap = studentList.stream().collect(Collectors.groupingBy( stu -> stu.getClassId(), Collectors.toList()));
studentMap.forEach( (k,v) -> {
System.out.println(k +"---"+ v);
});
}
}
@Data
@AllArgsConstructor
class Student {
private int gradeId; // 年级
private int classId; // 班级
private String name; // 名字
private int score; // 分数
}

14.遍历:forEach和forEachOrdered
public class StreamTest {
public static void forEachTest(List<String> list){
list.stream().parallel().forEach(System.out::println);
}
public static void forEachOrderedTest(List<String> list){
list.stream().parallel().forEachOrdered(System.out::println);
}
public static void main(String[] args) {
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
forEachTest(list);
System.out.println("----------");
forEachOrderedTest(list);
}
}
执行结果:
asdaa
212121121
789
1101
2321eew
3e3e3e
456
123
----------
123
456
789
1101
212121121
asdaa
3e3e3e
2321eew
二者都是遍历操作,从结果是可以看出来,如果是单线程(也就是不加parallel方法的情况)那么二者结果是一致的,但是如果采用并行遍历,那么就有区别了,forEach并行遍历不保证顺序(顺序随机),forEachOrdered却是保证顺序来进行遍历的。
15.收集器:collect
collect操作是Stream中最强大的方法了,几乎可以得到任何你想要的结果,collect方法有两个重载方法:
public interface Stream<T> extends BaseStream<T, Stream<T>> {
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);// 编号1
<R, A> R collect(Collector<? super T, A, R> collector);// 编号2
}
collect是收集的意思,这里的作用就是收集归纳,将流中的数据映射为各种结果。
首先看看编号1方法,有三个参数:supplier用于生成一个R类型的结果容器来盛放结果,accumulator累加器用于定义盛放的方式,其中T为一个元素,R为结果容器,第三个参数combiner的作用是将并行操作的各个结果整合起来。
public class StreamTest {
public static void collectTest1(List<String> list){
ArrayList<String> arrayList = list.stream().skip(4).collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
arrayList.forEach(System.out::println);
}
public static void main(String[] args) {
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
collectTest1(list);
}
}
执行结果
212121121
asdaa
3e3e3e
2321eew
例子中:
- 第一个:ArrayList::new表示创建一个新的ArrayList集合,
- 第二个 ArrayList::add表示将元素一个一个添加到之前的集合中,
- 第三个ArrayList::addAll表示将多个线程的ArrayList集合一个一个的整体添加到第一个集合中,最终整合出一个最终结果并返回。
重点来看看编号2方法。
- 它只需要一个Collector类型的参数,这个Collector可以称呼为收集器,我们可以随意组装一个收集器来进行元素归纳。
Collector是定义来承载一个收集器,但是JDK提供了一个Collectors工具类,在这个工具类里面预实现了N多的Collector供我们直接使用,之前的Collectors.toList()就是其用法之一。具体见下文。
public class StreamTest {
public static void collectTest2(List<String> list){
Set<String> set = list.stream().skip(4).collect(Collectors.toSet());
set.forEach(System.out::println);
}
public static void main(String[] args) {
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
collectTest2(list);
}
}
执行结果为
212121121
2321eew
3e3e3e
asdaa
有关Collector具体可阅读:Java流式操作系列-Collector和Collectors
16.归纳:reduce
reduce方法有三个重载的方法,
public interface Stream<T> extends BaseStream<T, Stream<T>> {
Optional<T> reduce(BinaryOperator<T> accumulator);// 编号1
T reduce(T identity, BinaryOperator<T> accumulator);// 编号2
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);// 编号3
}
这三个方法的作用其实是一样的,就是归纳总结的意思。
-
编号1方法,只有一个参数accumulator,这是一个累加器,方法的作用就是将这个累加器作用到流中的每一个元素,他需要两个输入参数,有一个输出参数,意思是对两个元素执行某些操作,返回一个结果,然后将这个结果与下一个元素作为参数再输入该方法,执行操作后再返回一个新结果,以此类推,直到最后一个元素执行完毕,返回的就是最终结果,因为流中的元素我们是不确定的,那么我们就无法确定reduce的结果,因为如果流为空,那么将会返回null,所以使用Optional作为返回值,妥善处理null值。
-
编号2方法,在编号1方法的基础上加了一个identity,且不再使用Optional,为什么呢,因为新加的identity其实是个初始值,后续的操作都在这个值基础上执行,那么也就是说,,如果流中没有元素的话,还有初始值作为结果返回,不会存在null的情况,也就不用Optional了。
-
编号3方法,在编号2方法的基础上又加了一个参数combiner,其实这个方法是用于处理并行流的归纳操作,最后的参数combiner用于归纳各个并行的结果,用于得出最终结果。
那么如果不使用并行流,一般使用编号2方法就足够了。
public class StreamTest {
public static void reduceTest(){
List<Integer> ints = Arrays.asList(1,2,3,4,5,6,7,8,9);
Optional<Integer> optional = ints.stream().reduce(Integer::sum);
System.out.println(optional.get());
System.out.println("-------------");
Integer max = ints.stream().reduce(Integer.MIN_VALUE, Integer::max);
System.out.println(max);
System.out.println("-------------");
Integer min = ints.parallelStream().reduce(Integer.MAX_VALUE, Integer::min, Integer::min);
System.out.println(min);
}
public static void main(String[] args) {
reduceTest();
}
}
45
-------------
9
-------------
1
17. 最大值/最小值:max\min
通过给定的比较器,得出流中最大\最小的元素,为避免null返回,这里使用Optional来封装返回值。
public class StreamTest {
public static void maxMinTest(List<String> list){
System.out.println("长度最大:" + list.stream().max((a,b)-> a.length()-b.length()));
System.out.println("长度最小:" + list.stream().min((a,b)-> a.length()-b.length()));
}
public static void main(String[] args) {
List<String> list = Arrays.asList("123","456","789","1101","212121121","asdaa","3e3e3e","2321eew");
maxMinTest(list);
}
}
执行结果为
长度最大:Optional[212121121]
长度最小:Optional[123]
17.多对一匹配:
4.Optional
1.什么是Optional
- Optional是Java8中用于简化
Java中对空值的判断处理,以防止出现各种空指针异常。 - Optional实际上是
对一个变量进行封装,它包含有一个属性value,实际上就是这个变量的值。
2.Optional对象创建
- Optional构造方法都是
private类型的,因此要初始化一个Optional的对象无法通过其构造函数进行创建。 - Optional提供了一系列的
静态方法用于构建Optional对象:
empty()
用于创建一个空的Optional对象;其value属性为Null。
Optional o = Optional.empty();
of()
根据传入的值构建一个Optional对象;传入的值必须是非空值,否则如果传入的值为空值,则会抛出空指针异常。
o = Optional.of("test");
ofNullable()
根据传入值构建一个Optional对象,传入的值可以是空值,如果传入的值是空值,则与empty返回的结果是一样的。
3.Optional方法常用方法
| 方法名 | 说明 |
|---|---|
| get | 获取Value的值,如果Value值是空值,则会抛出NoSuchElementException异常;因此返回的Value值无需再做空值判断,只要没有抛出异常,都会是非空值。 |
| isPresent | Value是否为空值的判断; |
| ifPresent | 当Value不为空时,执行传入的Consumer; |
| ifPresentOrElse | Value不为空时,执行传入的Consumer;否则执行传入的Runnable对象; |
| filter | 当Value为空或者传入的Predicate对象调用test(value)返回False时,返回Empty对象;否则返回当前的Optional对象 |
| map | 一对一转换:当Value为空时返回Empty对象,否则返回传入的Function执行apply(value)后的结果组装的Optional对象; |
| flatMap | 一对多转换:当Value为空时返回Empty对象,否则传入的Function执行apply(value)后返回的结果(其返回结果直接是Optional对象) |
| or | 如果Value不为空,则返回当前的Optional对象;否则,返回传入的Supplier生成的Optional对象; |
| stream | 如果Value为空,返回Stream对象的Empty值;否则返回Stream.of(value)的Stream对象; |
| orElse | Value不为空则返回Value,否则返回传入的值; |
| orElseGet | Value不为空则返回Value,否则返回传入的Supplier生成的值; |
| orElseThrow | Value不为空则返回Value,否则抛出Supplier中生成的异常对象; |
4.使用场景
- 判断结果不为空后使用
如某个函数可能会返回空值,以往的做法:
String s = test();
if (null != s) {
System.out.println(s);
}
现在做法:
Optional<String> s = Optional.ofNullable(test());
s.ifPresent(System.out::println);
乍一看代码复杂度上差不多甚至是略有提升;那为什么要这么做呢?
- 一般情况下,我们在使用某一个方法返回值时,要做的第一步就是去分析这个方法是否会返回空值;如果没有进行分析或者分析的结果出现偏差,导致函数会抛出空值而没有做检测,那么就会相应的抛出空指针异常!
- 而有了Optional后,在我们不确定时就可以不用去做这个检测了,所有的检测Optional对象都帮忙我们完成,我们要做的就是按上述方式去处理。
- 变量为空时提供默认值
如要判断某个变量为空时使用提供的值,然后再针对这个变量做某种运算;
以往做法:
if (null == s) {
s = "test";
}
System.out.println(s);
现在做法:
Optional<String> o = Optional.ofNullable(s);
System.out.println(o.orElse("test"));
- 变量为空时抛出异常,否则使用
以往做法:
if (null == s) {
throw new Exception("test");
}
System.out.println(s);
现在做法:
Optional<String> o = Optional.ofNullable(s);
System.out.println(o.orElseThrow(()->new Exception("test")));
JDK8新特性:使用Optional避免null导致的NullPointerException
引用自相关文章
Java 8 新特性
Java函数式编程(一)
Java函数式编程(二)
Java基础系列-Stream-1
Java基础系列-Collector和Collectors-2
Java8-函数式编程好博客