system design之key-value存储引擎
前言
最近在准备微软的面试,各位朋友可能有的人不清楚,微软面试是需要考察system design的,基本上是给你一个挺大的设计问题,考察你对这一块的理解程度。
这里我基本上是参考了github上一位老哥的总结:soulmachine,侵删。
题目描述
请设计一个Key-Value存储引擎(Design a key-value store)。
分析
首先咱们要清楚,数据库与存储引擎的关系。其实一句话描述:存储引擎就是数据库的底层。咱们接触过的(我没接触过)MySQL数据库,其底层的存储引擎就可以是类似LevelDB或者是RocksDB这种东西。(在前者的基础上发展出后者)大多数分布式数据库的底层不约而同的都选择了RocksDB。
另外一个是随机写的问题了。啥叫随机写?很简单,就是用户每次插入一次数据,你这个存储引擎就往磁盘写入一次数据,那也太僵硬了,慢的要死。
sstable主要结构
sstable结构是我们必须要了解的一个东西。它全名sorted string table,就是对key进行排序排列的key-value键值对。当然它的结构还是比较有趣的,咱们要作为一种特殊的数据结构进行学习。这里我引用一下掘金@老钱的内容做介绍,侵删。先别管这个数据结构是用在什么地方的,先了解这个结构。

上面这张图很好的解释了sstable的三层结构。
Data block
1.我们最关心的key-value键值对表,就放在Data block中。咱们知道,因为是按照key进行有序排列的,所以相邻的key可能有很多字符前缀是重复的。咱们就可以对key进行一个压缩。
压缩的方法也很简单,就设置一个基准key,然后后续的key应该是根据基准key,有一些前缀相同,有一些后缀不同。
Key = sharedKey + unsharedKey
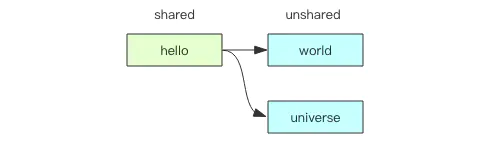
上面这张图就很好的描述了前缀(shared)的工作方式。
当然了,咱们不能只给一个Data block分配一个基准key,那越往后重复的就越少,压缩效果也就越小了。于是咱们要设置多一些的基准key,并把这些基准key的信息存储在Data block的前面部分作为索引。
Data block中一条索引的具体内容是:

可以看到,前面包括公共部分key的长度,独有部分key的长度,然后是具体的value长度与数值。
对于一个基准key来说,自然shared key length的长度是0,但是这不意味着只要这个数值是0,就是基准key。
最后Data block的格式就如下:

可以看到,先是基准key(图上叫restart point)数量,然后是各个基准key的偏移量。
如何设置这些基准key呢?其实设置的方式没那么智能,就是固定的按照每个dis个间距设置一个基准key。
一个 DataBlock 的默认大小只有 4K 字节,所以里面包含的键值对数量通常只有几十个。如果单个键值对的内容太大一个 DataBlock 装不下咋整?如果真的因为value太大导致一个Data block大小超过4K,那也没关系,就存储这一条数据,超了也就超了,没关系。
Filter block
这个是滤波器模块。(一般是布隆滤波器)
布隆过滤器用于加快 SSTable 磁盘文件的 Key 定位效率。如果没有布隆过滤器,它需要对 SSTable 进行二分查找,Key 如果不在里面,就需要进行多次 IO 读才能确定,查完了才发现原来是一场空。布隆过滤器的作用就是避免在 Key 不存在的时候浪费 IO 操作。通过查询布隆过滤器可以一次性知道 Key 有没有可能在里面。
咱们看看FilterBlock的结构:
struct FilterEntry {
byte[] rawbits;
}
struct FilterBlock {
FilterEntry[n] filterEntries;
int32[n] filterEntryOffsets;
int32 offsetArrayOffset;
int8 baseLg; // 分割系数
}
可见FilterBlock中有很多FilterEntry组成(bitmap存储哈希后的结果,一个key对应一个bit),每个entry负责一段固定长度的Data block数据的key的指纹化(你可能不清楚啥是指纹化,其实就可以直接理解为是将key做哈希)。这个baseLg指的是每个Entry对应的Data block长度,代表2 << baseLg个byte。
关于布隆过滤器我想和大家说的清楚一点。比如一个key输入进来以后,过滤器会将其传递到很多个哈希函数中最终得到的结果与过滤器的长度进行取模,然后把对应的bit设置成1.如果有哈希冲突,那就顺延一下。对删除操作而言,也是要先删除顺延的。
其实过滤器说有的,不一定有;但是说没有的,那么就一定没有。
IndexBlock
这个就是存储多个DataBlock使用的,内容如下:

可以看到这里没有restart point的概念,每个entry存放的都是对应的Data block的最大key信息。
compaction操作
归并操作是非常有必要的一个操作,当我们的sstable文件转存到磁盘上,久而久之,磁盘上的sstable文件也就越来越多,慢慢的就很僵硬了。于是咱们要在服务器端搞一个磁盘的sst文件周期性合并的操作,即compaction。
compaction一般会带来三个放大问题,分别是读放大、写放大和空间放大。
写放大,假设每秒写入10MB的数据,但观察到硬盘的写入是30MB/s,那么写放大就是3。
读放大,对应于一个简单query需要读取硬盘的次数。
空间放大,假设我需要存储10MB数据,但实际硬盘占用了30MB,那么空间放大就是3。
具体有两大类归并方法:
- Minor Compaction是指选取一个或多个小的、相邻的转储SSTable与0个或多个Frozen Memtable,将它们合并成一个更大的SSTable。一次Minor Compaction的结果是更少并且更大的SSTable。
- Major Compaction是指将所有的转储SSTable和一个或多个Frozen Memtable合并成一个SSTable,这个过程会清理被删除的数据。一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。
具体如何合并两个或者多个sstable呢?其实很简单,就类似有序线性表的合并,然后重新计算一下布隆滤波器的内容,更新一下上层的index表项,完成。
LevelDB主要结构

咱们看,用户执行写入操作时操作的直接对象是MemTable,它和转存到硬盘中的sstable还稍微有点不太一样,因为它要执行频繁的插入操作,所以在组织结构上是一种跳表的形式。每次执行MemTable的写入操作时都会先在磁盘的log文件中写入记录,防止咱们这次的操作还没来得及写入磁盘就丢失。
OK当MemTable写满了大小时,将其冻结(设置成只读),然后创建一个新的MemTable。那个冻结的table就写入到磁盘中,同时消除一下log。
写入磁盘时会涉及到compaction操作,这个咱们上文提到过。
当执行查询操作时,先查询一下内存的MemTable,有的话就成了;没有的话就到磁盘里查询。基本上是先定位到大致的范围,然后通过哈希查看过滤器是否满足条件:不满足则直接退出;满足则继续磁盘IO。
删除操作并不是直接将磁盘数据删除,而是给这个数据key-value写入一个标质量,表示这组数据已经死了,等待某次合并操作将其彻底删除掉。