一、数据编码主要三个
- 数据正规化(Data Normalization)
• 将数据重新分布在一个特定的范围内(0~1)
• 年龄 VS. 年薪
• 数据正规化的方法
• 极值正规化(Min-Max Normalization)
• Z-分数正规化(Z-Score Normalization)
2.数据一般化(Data Generalization)
• 数据的概念阶层(Concept Hierarchy)
向上提升
• 会员地址用城市或是北中南东四区取代
3.数据精简
• 记录精简(Record Reduction)
• 域值精简(Value Reduction)
• 字段精简(Attribute Reduction)
二、数据正规化常用方法
1.极值正规化(Min-Max Normalization)
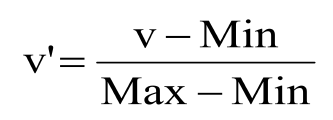
2.Z-分数正规化(Z-Score Normalization)

三.数据一般化的常用方法
数据型态的转换(Data Type Transformation)---两种形态数据之间的互转:类别转数值型;数值型转类别
• 1.类别型转换成数值型数据
• 连续性指派(Continuousness Arbitrary)
• 学历(以入学年龄取代):小学(6)、国中(12)、高中(15)、大学(18)、硕士(22)
• 性别(以逾期概率取代) :男、女
•2. 数值型转换成类别型数据
• 数据离散化(Data Discretization)
• 利用集群法将数值型态数据分群,接着将群集取合适名称,再利用群集的名称代替群集内所包含的数值型数据,转换成类别型数据
•3. 为什么要数值一般化?
数值型字段常常模型不稳定的来源之一。
• 常常我们会发现分类模型在训练数据集的预测准确度很高,但在测试数据集中的准确度却大幅度下滑
• 其中一个相当大的原因就是,许多的输入字段(尤其是数值型输入字段),在目标字段值上的分布,训练数据集与测试数据集的差异很大
•4. 数值一般化的优点?
对数值字段作离散化,有下列数个优点
• 1可使数据精简,降低数据的复杂度,让数据更容易被解释
• 2可支持许多无法处理数值型字段的分类算法
• 例如,贝氏分类(Bayesian Classification)算法、以关联规则(Association Rules)为基础的分类算法等
•3 可提高分类器的稳定性,进而提升分类模型的准确度
•4可找出输入字段在目标字段上的趋势(Trend),有助于未来的解
• 5 然而,数值字段离散化除了让数据精简、稳定模型外,如何让分析人员易于理解与解释也是非常重要的
一个易于理解与解释的离散化结果是,输入字段在目标字段上能够看出明显的趋势性(Trend)
四、数据一般化之--数值转类别方法
分离技术(Discretization):切割出数个区间来取代值域上众多的数据数值
• 依据对数据的认知、专家的建议、普遍存在的现象,将数据数值分离出数个区间
• 年龄可以分离出下列三个区间,(0, 30]、(30,60]、(60,120],并分别对应到 ‘青年’、‘中年’ 和 ‘老年’ 等三个数据数值
常用的分离技术:装箱法(Binning Method)
• 1.等宽(Equal-Width-Interval)装箱法
在使用者所给定之箱子个数n下,依据排序过后数据数值之最大值与最小值切割成n个等宽箱子
• 以年龄而言,在使用者所给定之箱子个数为3下,每一个箱子的宽度为 (36-28+1) /3 = 3
• 箱子一:28, 29, 30
• 箱子二:31, 32
• 箱子三:35, 36
• 2.等分(Equal-Frequency-Interval)装箱法
• Equal-Size-Interval Binning Method
• Histogram Equalization Binning Method
• 在使用者所给定之箱子个数n下,依据数据数值的数量切割成n个数量相等箱子
• 会员数据表中总共有7笔数据记录,在用户所给定之箱子个数为3下,每一个箱子可装载之数据笔数为为7/3 = 2.33,经四舍五入后为2
• 箱子一:28, 29
• 箱子二:30, 31
• 箱子三:32, 35, 36
五、数据精简的常用方法
(一)数据记录精简方法
1.数据记录精简的需求
• 随着数据表中的数据记录愈来愈多,有两个问题会浮现出来
• 整个数据挖掘所需的时间将跟着拉长
• 所有统计的方法通通失效
2.数据记录精简对所获得的知识影响
• 求得之知识可能多少有些误差
• 然而当数据集合中存在无关、偏差的数据记录时,将数据记录作适当的精简,将能获得更准确有效的知识
3.数据记录精简常用方法
(1)统计方法中抽样(Sampling)的作法
• 数据集合中抽取部分的数据记录样本来代表整个数据集合母体
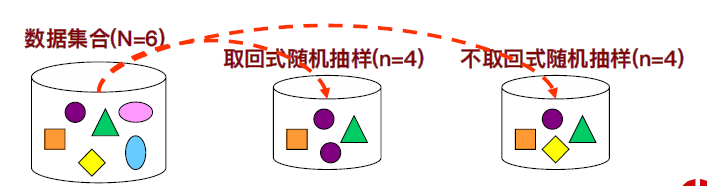
• 随机抽样(Random Sampling):有放回,无放回。
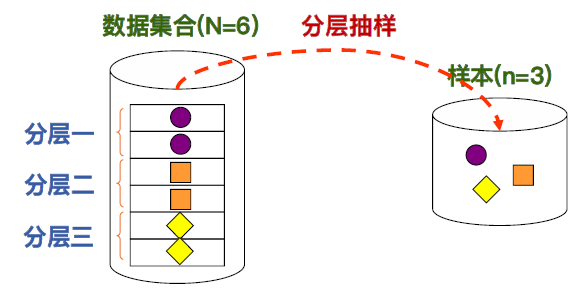
• 分层抽样(Stratified Sampling):针对数据集合中同构型高且互不重迭的分层,各自进行随机抽样。 将各分层的抽样结果结合成一个样本。
• 聚类抽样(Cluster Sampling):利用聚类技术,将整个数据集合分成数个群集,使得每个群集中的记录相似度很高,不同群集间的记录相似度很低随机由这些群集中选取数个群集形成样本。

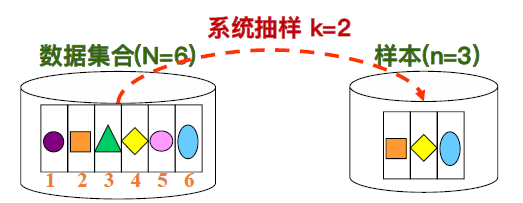
• 系统抽样(Systematic Sampling):假设数据集合中的数据记录笔数为N,而所需之样本数据记录笔数为n,则系统抽样的方式首先随机由1~N/n之间选取一个数字;假设所选取的数字为k, 以k开始,每N/n个间隔 (interval),将相对应的数据记录选取进样本之中。
• 两阶段式抽样(Two-Phase Sampling)
进行两个阶段的抽样选取以决定样本
• 第一阶段首先由数据集合中随机抽样出一个较大的样本,接着将第一阶段中所得到的样本当成数据集合,进行第二阶段的抽样
• 两阶段式抽样可以延伸成多阶段式抽样(Multi-Phase Sampling)