表很大的时候,性能下降?
如果表有索引,增删改变慢,需要维护索引。
1.如果1个或少量查询以然很快
2.当并发或sql复杂会受硬盘带宽影响速度。
常识:
硬盘:寻址慢、带宽慢。
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
为什么redis 单线程的还很快呢?

因为cpu很快,磁盘IO很慢。很多请求来了之后,由于cpu的速度很快,所以执行起来依然很快。一笔一笔处理,所以线程安全。
内核的epoll同步,非阻塞多路复用。
redist 取的是字节流,而不是字符流。所以redis是二进制安全的
redis 安装这里就不教了下面使用的是window的
打开redis的目录,启动 redis-server.exe,redis-cli.exe 。顺序的,否则报错。 server为服务端。
redis默认有16个库。0和1号不能更名。
help @generic 查看指令帮助文档
help @string 会出现string相关的使用
flushdb 清库
help set 查看当前组的类型
redis String , String 类型又分为三种存储类型 : String、数值、bitmap
set key value 设置一个key和value
get key value 查询一个key和value
select 8 切换到8号库。

set key value1 nx:
nx 不存在这个key的时候才去设置 key 的value 为value1。如果存在这个key,则返回nil。新建
msetnx key1 value1 key2 value 同上,不过可以操作多个,并且是原子性,一个失败则全部失败
场景:分布式锁。
set key value1 xx : xx 只有当这个key存在的时候才可以进行操作,修改value 为value1.否则返回nil。更新
mset key1 a key2 b : 批量插入。
mget key1 key2 : 批量查询。
APPEND key1 “world” : 给key1追加内容
GETRANGE key1 4 7 : 取出key1 的第5到8个字符的内容。索引从0开始
GETRANGE key1 4 -1 : 取出key1 的第5到最后一个个字符的内容。反向,最后一个为-1,倒数第二个为-2
SETRANGET key 5 d : 将key的第5个位置设置为d。如果是 ddd,那就从第6个位置开始覆盖
STRLEN key : 输出key的value长度
type key : 查看key的value类型
当这个组(group)的类型为string,value值为99也是string型的。但是object encoding 可以是 int的

INCR key,encoding 为int 的会进行自增。 INCRBY key 22 加上22.如果之前为99,则新的为121. 抢购、秒杀、商品详情页,对数据库的事务操作完全由redis内存代替,微博点赞、评论等。
DECR key 5,类似INCR key,不过是减。DECRBY key 5同INCRBY
INCRBYFLOAT key 0.5 ,类似INCR key,不过是加0.5的float操作。

先设置key1 为23 ,这是type key1 是string,因为这个group的type就是string。但是不影响它的object encoding 是int的。
在key1 后面追加 22,这时候就是字符串追加了。 key1 由 23 --> 2322。object encoding 变成 raw。
对key1 执行incr ,加1 操作, 2322 变成2323,这时object encoding 又回到 int了。
说明,不同的操作会改变value的object encoding。

这里追加一个中字,可能是不兼容,中文显示的不友好。长度变为3.这里中文的长度跟字符编码有关,如果是UTF-8,则占3个长度。存储的时候存储的是字节
getset 命令,设置一个新值并返回旧值

bitmap
setbit 设置指定offset 值,offset 下标从0开始。8bit = 1byte。修改完位后,值为对应的ascll码


help bitpos :Find first bit set or clear in a string 查找bit中第一个字符的位置
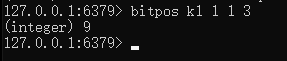
查找k1 中从0到9 字节中值为1的位位置。这里是字节,非位。返回的是第几位
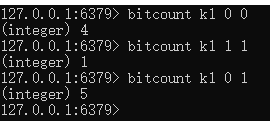
bitcount : 只统计 1 出现了几次。
bitcount k1 0 0 : 统计 k1 中从0到0个字节里面1出现了几次
bitcount k1 1 1 : 统计 k1 中从1到1个字节里面1出现了几次
bitcount k1 0 1 : 统计 k1 中从0到1个字节里面1出现了几次
bitop 按位操作
bitop and andkey k1 k2 :对k1 和 k2 进行按位与操作(有0则0,全1则1),然后将值放入到 andkey 中

bitop or orkey k1 k2 :对k1 和k2 进行按位或操作(有1 则1,全0则0),将值放入到orkey中

位图应用。
bitcount
例如,统计某个用户是否登录过。一年365天。给到400位 = 50个字节。
setbit user1 5 1 : 第五天登录了, setbit user1 300 1: 第三天登录了。
统计: bitcount user1 -1 -1 最后8天内有没有登录过。
按位或应用
统计双11,双12登录的人数,去重,注册用户3E。
key11、key12,分别分配 3亿 位 = 3亿 / 8 字节 ,每位对应一个用户
setbit key11 1530 1 ,设置11 第 1530位用户登录了
bitop or key1112 key11 key12 , 然后对 key1112 进行bitcout 0 -1 统计所有的字节里面的为1的
按位或、按位与 : 二维计算模型
key查找
keys * : 显示所有key,不推荐!!!
scan
SCAN 命令是一个基于游标的迭代器(cursor based iterator): SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。
当 SCAN 命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
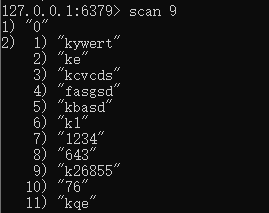
遍历所有的key : scan 0,返回下标 9 ,告诉我们这次找到了9个key,下次从9开始找
scan 9 : 从下标9开始找,返回0,告诉我们遍历完了。

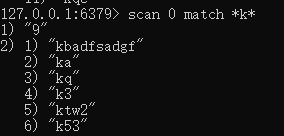
模糊查询
scan 0 match *k*: 找到了9个,下次从9继续。
scan 0 match *k* count 20 : 从0开始找,匹配 带'k' 的key,并返回20个。

SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)