作业题
1. 简述hive工作原理
1、执行查询:Hive接口,命令行或者web ui发送查询驱动程序
2、get plan:驱动程序查询编译器
3、词法分析/语法分析
4、语义分析
5、逻辑计划产生
6、逻辑计划优化
7、物理计划生成
8、物理计划优化
9、物理计划执行
10、查询结果返回
提示:以上是hive的大致工作原理流程,一般面试问到这里就算比较深入了
2. hie内部报表和外部表区别
创建表时:创建内部表,会将数据移动到数据仓库指定的路径;若创建外部表,仅记录数据所在的路径
不对数据的位置坐任何改变。
删除表时:在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除
数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
提示:内部表与外部表的区别一定要掌握,通常情况下我们都会使用外部表保证数据安全性,
但是像中间表,结果表这种我们就会考虑使用内部表
3. 有以下格式的数据创建出合适的表结构,并将数据导入表中
建表:
create table t_movie(movie_name string,actors array<string>,first_date date)
row format delimited fields terminated by ‘,’
collection items terminated by ‘,’ ;
导入数据
load data local inpath ‘/home/hadoop/movie’ into table t_movie ;
战狼,吴京:吴刚:卢靖姗,2017-08-16
大话西游,周星驰:吴孟达,1995-09-01
3.1 查询出每个电影的第二个主演
select movie_name,actors[1] ,first_date from t_movie;
3.2 查询每部电影有几名主演
select movie_name,actors,fitst_date,size(actors) as num from t_movie;
3.3 主演里面包含古天乐的电影
select movie_name ,actors from t_movie where array_contains(actors,‘古天乐’);
解析:在这里首先我们看到比较特殊的是主演的名字,而名字又都是string类型的,
所以考虑到使用array,因为array存储的都是相同类型的元素,这里我们要使用collection items
terminated by ‘,’ 这个设置来指定复杂数据类型中元素的分隔符
大家要注意 collection items terminated by 不仅是用来分割array的,它的作用是分割复杂数据类型里面的元素的
3.1我们只需要使用array的下角标即可
3.2 使用size这个内置函数判断array的元素的个数
3.3 使用array_contains来判断array中是否有这个元素
4. 有以下表格的数据创建出合适的表结构,并将数据导入表中
1,张三,18:male:北京
2,李四,29:feamle:上海
create table t_user(id int,name string,info struct<age:string,sex:string,addr:string>)
row format delimited fields terminated by ‘,’
collection items terminated by ‘:’ ;
导入数据:
load data local inpath '/home/hadoop/user' into table t_user ;
4.1 查询出每个人的id,名字,居住地址
select id,name,info.addr from t_user;
5. 有以下表格的数据创建出合适的表结构,并将数据导入表中
1,小明,father:张三#month:李丽#brother:小力,28
create table t_family(id int,name string,family_mem map<string,string>,age int)
row format delimited fields terminated by ‘,’
collection items terminated by ‘#’
map keys terminated by ‘:’ ;
5.1 查看每个人的父亲
select id,name,falimy_mem["father"],age from t_family;
5.2 每个人有哪些亲属关系
select id,name ,map_keys(family_mem),age from t_family;
5.3 查出每个人的亲人名字
select id,name,map_values(family_mem) asrelations ,age from t_family;
5.4 查出每个人的亲人数量
select id,name,size(family_mem) as relations,age from t_family;
======================================================================================================================
一、课前准备
1. 安装hive环境
二、课堂主题
本课堂主要围绕hive的DDL操作和DML操作进行讲解,主要包括以下几个方面
1. hive对表的DDL和DML操作
2. hive表的数据导入和数据导出方式
3. hive的分区表和分桶表
三、课堂目标
1. 掌握hive中数据导入的方式
2. 掌握hive中数据导出的方式
3. 掌握hive创建分区表和使用方式
4. 掌握hive的静态分区和动态分区
5. 理解hive中的分桶表作用
四、知识要点
1. Hive的分区表
1.1 hive的分区表的概念
吧表的数据分目录存储,存储在不同的文件夹下
后期安装不同的目录查询数据,不需要进行全量扫描,提升查询的效率
在文件系统上简历文件夹,把表的数据放在不同文件夹下面,加快查询速度。
1.2 hive分区表的构建
创建一个分区字段的分区表
create table student_partition( id int, name string, age int ) partitioned by (dt string) row format delimited fields terminated by '\t' ;
创建二级分区表
create table student_partition2( id int, name string, age int ) partitioned by (month string,day string) row format delimited fields terminated by '\t' ;
2. hive修改表结构
2.1 修改表的名称
alter table t_old rename to t_new;
2.2 表的结构信息
desc tb;
desc formatted tb;
2.3 增加/修改/替换列信息
- 增加列
alter table tb add columns(address string);
- 修改列
alter table tb change column address_old address_new int;
- 替换列
alter table tb replace columns(deptno string,dname string,loc string);
#表示替换表中的所有字段
2.4 增加/删除/查看分区
- 添加分区
- 添加单个分区
alter table tb add partition(dt="20170601");
- 添加多个分区
alter table tb add partition(dt="20170101") partition(dt="20180101");
- 删除分区
alter table tb drop partition(dt="20200101");
alter table tb drop partition(dt=‘20200101’),partition(dt=‘20200202’);
- 查看分区
show partitions tb;
3. hvie数据导入
3.1 向表中加载数据(load)
3.2 通过查询语句向表中插入数据insert
3.3 查询语句中创建表并加载数据 as select
3.4 创建表时通过location 指定加载数据路径
3.5 import 数据到指定hive表
注意:先用export导出后,再将数据导入
create table s2 like s1;
export table s1 to '/export/s1'
import table s2 from '/export/s1'
4. hive数据导出
4.1 insert导出
- 1、将查询的结果导出到本地
insert overwrite local directory ‘/opt/bigdata/export/student’
select * from s1;
- 2、将查询结果格式化导出到本地
insert overwrite local directory ‘/opt/bigdata/export/student’
row format delimited fields terminated by ‘,’
select * from s1;
- 3、将查询的结果导出到hdfs上(没有local)
insert overwrite directory ‘/opt/bigdata/export/student’
row format delimited fields terminated by ‘,’
select * from s1;
4.2 hadoop命令导出到本地
hdfs dfs -get /user/hive/warehouse/student/student.txt /opt/bigdata/data
4.3 hive shell命令导出
基本语法
hive -e “sql语句” > file
hive -f “sql文件” > file
4.4 export 导出到hdfs上
export table default.tb1 to ‘/user/hive/warehouse/export/tb1’;
5. hive静态分区和动态分区
5.1 静态分区
表的分区字段的值需要开发人员手动给定
5.2 动态分区
按照需求实现把数据自动导入到表的不同分区中,不需要手动指定
要进行动态分区,需要设置参数
使用动态分区,
非严格模式
分区数量
注意字段查询的顺序,分区字段放在最后面,否则数据会有问题
五、拓展点
hive的分桶表
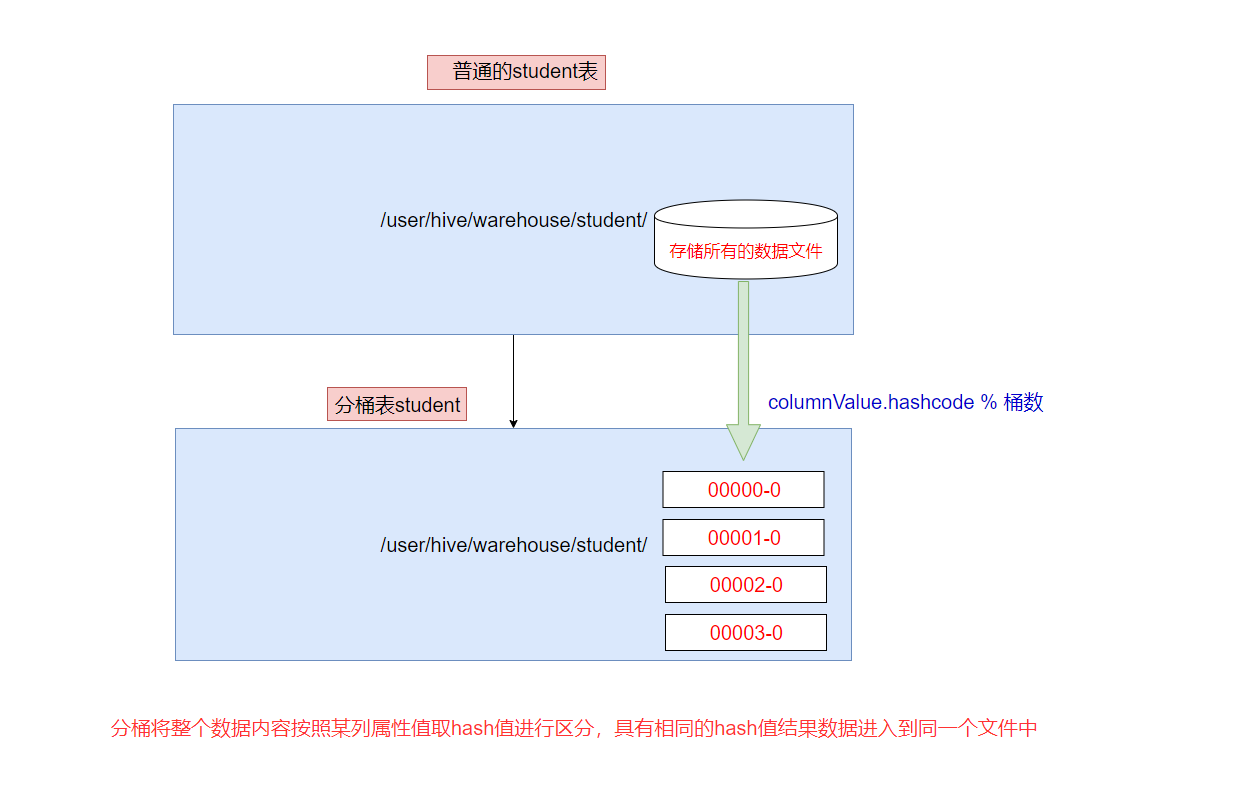
分桶表是相对分区进行更细粒度的划分
分桶将整个数据内容安装某列属性值取hash值进行区分、具有相同hash值的数据进入到同一个文件中
比如安装name属性分为3个桶,就是对name属性值的hash值对3取模,按照取模结果对数据分桶
作用:
1. 取样smapling更高效,没有分区的话需要扫描整个数据集
2. 提升某些查询操作效率,例如map side join
set hive.enforce.bucketing=true;开启对分桶的支持
set mapreduce.job.reduces=4;设置与桶相同的reduce个数(默认只有一个reduce)
=====================
有点无聊 [手动狗头]