Java方法分为实例方法和静态方法
实例方法
1 /*实例方法*/ 2 public final class Integer{ 3 boolean equals(Object o){ 4 ... 5 } 6 } 7 8 9 /*静态方法*/ 10 public final class Integer{ 11 public static int parseInt(String s){ 12 ... 13 } 14 }
Java的实例方法隐含地传入了一个this变量,即实例方法总是有一个隐含参数this
函数式编程是把函数作为基本运算单元,函数可以作为变量,可以接收函数,还可以返回函数。历史上研究函数式编程的理论是Lambda演算,所以我们经常把支持函数式编程的编码风格称为Lambda表达式。
Lambda表达式
在Java程序中,我们经常遇到一大堆单方法接口,即一个接口只定义了一个方法:
- Comparator
- Runnable
- Callable
以Comparator为例我们想要调用Arrays.sort()时,可以传入一个Comparator实例,以匿名类方式编写如下:
1 String[] array = ... 2 Arrays.sort(array,new Comparator<String>()){ 3 public int compare(Sting s1,String s2){ 4 return s1.compareTo(s2); 5 } 6 }
上述写法非常繁琐。从Java 8 开始,我们可以用Lambda表达式替换单方法接口。改写上述代码如下:
1 public class Main{ 2 public static void main(String[] args){ 3 String[] array = new String[]{"Apple","Orange","Banana","Lemon"}; 4 Arrays.sort(array,(s1,s2)->{ 5 return s1.compareTo(s2); 6 }); 7 System.out.println(String.join(" ",array)); 8 } 9 }
Apple Banana Lemon Orange
观察Lambda表达式的写法,它只需要写出方法定义:
1 (s1,s2)->{ 2 return s1.compareTo(s2); 3 }
其中,参数是(s1,s2),参数类型可以省略,因为编译器可以自动推断出String类型。->{...}表示方法体,所有代码写在内部即可。Lambda表达式没有class定义,因此写法非常简洁。
如果只有一行return xxx的代码,可以用更简单的写法:
1 Arrays.sort(array,(s1,s2)->s1.compareTo(s2));
返回值的类型可由编译器自动推断,这里推断出的返回值是int,因此只要返回int,编译器就不会报错。
FunctionalInterface
我们把之定义了单方法的接口称之为FuncitonalInterface,用注解@FunctionalInterface标记。例如,Callable接口:
1 @FunctionalInterface 2 public interface Callable<V>{ 3 V call() throws Exception; 4 }
Comparator接口:
1 @FunctionalInterface 2 public interface Comparator<T>{ 3 int compare(T o1,T o2); 4 5 boolean equals(Object obj); 6 7 default Comparator<T> reversed(){ 8 return Collections.reverseOrder(this); 9 } 10 11 default Comparator<T> thenComparing(Comparator<? super T> other){ 12 .... 13 } 14 }
虽然Comparator接口有很多方法,但只有一个抽象方法int compare(T o1,T o2),其他的方法都是default方法或static方法。另外注意到boolean equals(Object obj)是Object定义的方法,不算在接口方法内。因此,Comparator也是一个FunctionalInterface。
而使用Lambda表达式,就不必编写FunctionalInterface接口的实现类,从而简化代码。
Arrays.sort(array,(s1,s2)->{return s1.compareTo(s2);})
还可以直接传入方法引用
1 public class Main{ 2 public static void main(String[] args){ 3 public[] array = new String[]{"Apple","Orange","Banana","Lemon"}; 4 Arrays.sort(array,Main::cmp); 5 System.out.println(String.join(",",array)); 6 } 7 static int cmp(String s1,String s2){ 8 return s1.compareTo(s2); 9 } 10 }
上述代码在Arrays.sort()中直接传入了静态方法cmp的引用,用Main::cmp表示。
因此,所谓方法引用,是指如果某个方法签名和接口恰好一致,就可以直接传入方法引用。
因为Comparator<String>接口定义的方法是int compare(String,String),和静态方法int cpm(String,String)相比,除了方法名外,方法参数一致,返回类型相同,因此,我们说两者的方法签名一致,可以直接把方法名作为Lambda表达式传入:
Arrays.sort(array,Main::cmp);
注意:在这里,方法签名只看参数类型和返回类型,不看方法名称,也不看类的继承关系。
再看看如何引用实例方法
1 public class Main { 2 public static void main(String[] args) { 3 String[] array = new String[] { "Apple", "Orange", "Banana", "Lemon" }; 4 Arrays.sort(array, String::compareTo); 5 System.out.println(String.join(", ", array)); 6 } 7 }
1 public final class String { 2 public int compareTo(String o) { 3 ... 4 } 5 }
这个方法的签名只有一个参数,为什么和int Comparator<String>.compare(String,String)能匹配呢?
因为实例方法有一个隐含的this参数,String类的compareTo()方法在实际调用的时候,第一个隐含参数总是传入this,相当于静态方法:
1 public static int compareTo(this,String o);
所以,String.compareTo()方法也可作为方法引用传入。
构建方法引用
除了可以引用静态方法和实例方法,我们还可以引用构造方法。
我们来看一个例子:如果把一个List<String>转换为List<Person>,应该怎么办?
传统的做法事定义一个ArrayList<Person>,然后用for循环填充这个List:
1 List<String> names = List.of("Bob","Alice","Tim"); 2 List<Person> persons = new ArrayList<>(); 3 for(String name : names){ 4 persons.add(new Person(name)); 5 }
要更简单地实现String到Person的转换,我们可以引用Person的构造方法:
1 public class Main{ 2 public static void main(String[] args){ 3 List<String> names = List.of("Bob","Alice","Tim"); 4 List<Person> persons = names.stream().map(Person::new).collect(Collectors.toList()); 5 System.out.println(persons); 6 } 7 } 8 9 class Person{ 10 String name; 11 public Person(String name){ 12 this.name = name; 13 } 14 public String toString(){ 15 return "Person:" + this.name; 16 } 17 }
后面我们会讲到Stream的map()方法。现在我们看到,这里的map()需要传入的FunctionalInterface的定义是:
1 @FunctionalInterface 2 public interface Function<T,R>{ 3 R apply(T t); 4 }
把泛型对应上就是方法签名Person apply(String),即传入参数String,返回类型Person。而Person类的构造方法恰好满足这个条件,因为构造方法的参数是String,而构造方法虽然没有return语句,但它会隐式地返回this实例,类型就是Person,因此,此处可以引用构造方法。构造方法的引用写法是类名:: new,因此,此处传入Person::new。
从Java8开始,不但引入了Lambda表达式,还引入了一个全新的流式API:Stream API。它位于java.util.stream包中。
重点:这个Stream不同于java.io的InputStream和outpurStream,它代表的是任意java对象的序列。

一个顺序输出的java对象序列和一个List容器有什么区别呢
这个Stream和List不一样,List存储的每个元素都是已经存储在内存中的某个java对象,而Stream输出的元素可能并没有预先存储在内存中而是实时计算出来的。
List的用途是操作一组已存在的Java对象,而stream实现的是惰性计算

如果我们要表示一个全体自然数的集合,显然,用List是不可能写出来的,因为自然数是无限的,内存再大也没法放到List中,但是,用Stream可以做到,写法如下:
1 Stream<BigInteger> naturals = createNaturalStream();
首先,可以对每个自然数做一个平方,这样我们就把这个Stream转换成了另一个Stream:
1 Stream<BigInteger> naturals = createNaturalStream(); //全体自然数 2 Stream<BigInteger> streamNxN = naturals.map(n->n.multiply(n)); //全体自然数的平方
因为这个streamNxN也有无限多个元素,要打印它,必须首先把无限多个元素变成有限个元素,可以用limit()方法截取前100个元素,最后用forEach()处理每个元素,这样,我们就打印出了前100个自然数的平方:
1 Stream<BigInteger> naturals = createNaturalStream(); 2 naturals.map(n->n.multiply(n)) 3 .limit(100) 4 .forEach(System.out::println);
Stream特点:
它可以存储有限个或无限个元素。这里的存储打了个引号,是因为元素有可能已经全部存储在内存中,也有可能是根据需要实时计算出来的
一个Stream可以轻易转换为另一个Stream,而不是修改原Stream本身
最后,真正的计算通常发生在最后结果的获取,也就是惰性计算。
1 Stream<BigInteger> naturals = createNaturalStream();//不计算 2 Stream<BigInteger> s2 = naturals.map(BigInteger::multiply);//不计算 3 Stream<BigInteger> s3 = s2.limit(100);//不计算 4 s3.forEach(System.out::println);//计算
惰性计算的特点是:一个Stream转换为另一个Stream时,实际上只存储了转换规则,并没有任何计算发生。
例如,创建一个全体自然数的Stream,不会进行计算,把它转换为上述s2这个Stream,也不会进行计算。再把s2这个无限的Stream转换为s3这个有限的Stream,也不会进行计算。只有最后,调用forEach确实需要Stream输出的元素时,才进行计算。我们通常把Stream的操作写成链式操作,代码更简洁
1 createNaturalStream() 2 .map(BigInteger::multiply) 3 .limit(100) 4 .forEach(System.out::println);
因此,Stream API的基本用法就是:创建一个Stream,然后做若干次转换,最后调用一个求值获取真正计算的结果:
1 int result = createNaturalStream()//创建Stream 2 .filter(n->n%2==0) //任意个转换 3 .map(n->n*n) //任意个转换 4 .limit(100) //任意个转换 5 .sum(); //计算结果
总结:
- Stream API提供了一套新的流式处理的抽象序列;
- Stream API支持函数式编程和链式操作;
- Stream可以表示无限序列,并且大多数情况下是惰性求值的。
创建Stream
Stream.of()
创建Stream最简单的方式是直接用Stream.of()静态方法,传入可变参数即创建了一个能输出确定元素的Stream:
1 public class Main{ 2 public static void main(String[] args){ 3 Stream<Stream> stream = stream.of("A","B","C","D"); 4 //forEach()方法相当于内部循环调用, 5 // 可传入符合Consumer接口的void accept(T t)的方法引用 6 stream.forEach(System.out::println); 7 } 8 }
这种方式基本没啥实质性用途,但测试的时候很方便
基于数组或Collection
第二种创建Stream的方法是基于一个数组或者Collection,这样该Stream输出的元素就是数组或者Collection持有的元素:
1 public class Main{ 2 public static void main(String[] args){ 3 Stream<String> stream1 = Arrays.stream(new String[]{"A","B","C"}) 4 }; 5 Stream<String> stream2 = List.of("X","Y","Z").stream(); 6 stream1.forEach(System.out::println); 7 stream2.forEach(System.out::println); 8 }
把数组变成Stream使用Arrays.stream()方法。对于Collection(List、Set、Queue等),直接调用stream()方法就可以获得Stream
上述创建Stream的方法都是把一个现有的序列变为Stream,它的元素是固定的。
基于Supplier
创建Stream还可以通过Stream.generate()方法,它需要传入一个Supplier对象:
1 Stream<String> s = Stream.generate(Supplier<String> sp);
基于Supplier创建的Stream会不断调用Supplier.get()方法来不断产生下一个元素,这种Stream保存的不是元素,而是算法,它可以用来表示无限序列。
例如,我们编写一个能不断产生自然数的Supplier,它的代码非常简单,每次调用get()方法,就生成下一个自然数:
1 public class Main{ 2 public static void main(String[] args){ 3 Stream<Integer> natual = Stream.generate(new NatualSupplier()); 4 natual.limit(20).forEach(System.out::println); 5 } 6 } 7 8 class NatualSupplier implements Supplier<Integer>{ 9 int n = 0; 10 public Integer get(){ 11 n++; 12 return n; 13 } 14 }
上述代码我们用Supplier<Integer>模拟了一个无限序列(当然受int范围限制不是真的无限大)。如果用List表示,即便在int范围内,也会占用巨大的内存,而Stream几乎不占用空间,因为每个元素都是实时计算出来的,用的时候再算。
对于无限序列,直接调用forEach()或者count()这些最终求值操作,会进入死循环,因为永远无法计算完这个序列,所以正确的方法是先把无限序列变成有限序列,例如,用limit()方法可以截取前面若干个元素,这样就变成了一个有限序列,对这个有限序列调用forEach()或者count()操作就没有问题
其他方法
创建Stream的第三种方法是通过一些API提供的接口,直接获得Stream。
例如,Files类的lines()方法可以把一个文件变成一个Stream,每个元素代表文件的一行内容
try(Stream<String>) lines = Files.lines(Paths.get("/path/to/file.txt")){ ... }
此方法对于按行遍历文本文件十分有用。
另外,正则表达式的Pattern对象有一个splitAsStream()方法,可以直接把一个长字符串分割成Stream序列而不是数组:
1 Pattern p = Pattern.compile("\\s+"); 2 Stream<String> s = p.splitAsStream("The quick brown fox jumps over the lazy dog"); 3 s.forEach(System.out::println);
基本类型
因为Java的范型不支持基本类型,我们无法用Stream<int>这样的类型,会发生编译错误。为了保存int,只能使用Stream<Integer>,但这样会产生频繁的装箱、拆箱操作。为了提高效率,java标准提供了IntStream<Integer>、LongStream和DoubleStream这三种使用基本类型的Stream,它们的使用方法和范型Stream没有大的区别,设计这三个Stream的目的是提高运行效率:
1 IntStream is = Arrays.stream(new int[]{1,2,3}); 2 LongStream ls = List.of("1","2","3").stream().mapToLong(Long::parseLong);
使用map
Stream.map()是Stream最常用的一个转换方法,它把一个Stream转换为另一个Stream。
所谓map操作,就是把一种操作运算,映射到一个序列的每一个元素上,例如,对x计算它的平方,可以使用函数f(x) = x*x。我们把这个函数映射到一个序列1,2,3,4,5上,就得到了另一个序列1,4,9,16,25

可见,map操作,把一个Stream的每个元素一一对应到应用了目标函数的结果上。
1 Stream<Integer> s = Stream.of(1,2,3,4,5); 2 Stream<Integer> s2 = s.map(n->n*n);
如果我们查看Stream的源码,会发现map()方法接收的对象是Function接口对象,它定义了一个apply()方法,负责把一个T类型转换成R类型:
<R> Stream<R> map(Function<? super T,? extends R> mapper);
其中,Function的定义是:
1 @FunctionalInterface 2 public interface Function<T,R>{ 3 R apply(T t); 4 }
利用map(),不但能完成数学计算,对于字符串操作,以及任何Java对象都是非常有用的。例如:
1 public class Main{ 2 public static void main(String[] args){ 3 List.of("Apple","pear","ORANGE","BANANA") 4 .stream() 5 .map(String::trim) //去空格 6 .map(String::toLowerCase) // 变小写 7 .forEach(System.out::println);//打印 8 } 9 }
使用filter(过滤器)
Stream.filter()是Stream的另一个常用转换方法。
所谓filter()操作,就是对一个Stream的所有元素一一进行测试,不满足条件的就被滤掉了,剩下的满足条件的元素就构成了一个新的Stream。
例如我们对1,2,3,4,5这个Stream调用filter(),传入的测试函数f(x)=x%2!=0用来判断元素是否是奇数,这样就过滤掉偶数,只剩下奇数,因此我们得到了另一个序列1,3,5
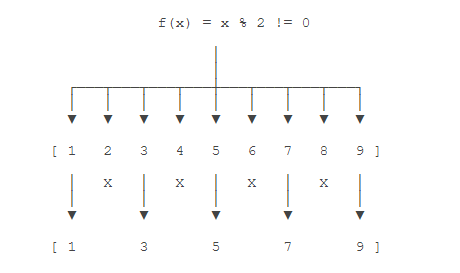
1 public class Main{ 2 public static void main(String[] args){ 3 IntStream.of(1,2,3,4,5,6,7,8,9) 4 .filter(n->n%2!=0) 5 .forEach(System.out::println); 6 } 7 }
从结果可知,经过filter()生成的Stream元素可能变少。
filter()方法接收的对象是Predicate接口对象,它定义了一个test()方法,负责判断元素是否符合条件:
1 @FunctionalInterface 2 public interface Predicate<T>{ 3 boolean test(T t); 4 }
filter()除了常用于数值外,也可应用于任何Java对象。例如,从一组给定的LocalDate中过滤掉工作日,以便得到休息日:
1 public class Main{ 2 public static void main(String[] args){ 3 Stream.generate(new LocalDateSupplier()) 4 .limit(31) 5 .filter(ldt->ldt.getDayOfweek()==DayOfWeek.SATURDAY||ldt.getDayOfWeek()==DayOfWeek.SUNDAY) 6 .forEach(System.out::println); 7 } 8 } 9 10 class LocalDateSupplier implements Supplier<LocalDate>{ 11 LocalDate start = LocalDate.of(2020,1,1); 12 int n = -1; 13 public LocalDate get(){ 14 n++; 15 return start.plusDays(n); 16 } 17 }
使用reduce
map()和filter()都是Stream的转换方法,而Stream.reduce()则是Stream的一个聚合方法,它可以把一个Stream的所有元素按照聚合函数聚合成一个结果。
1 public class Main{ 2 public static void main(String[] args){ 3 int sum = Stream.of(1,2,3,4,5,6,7,8,9).reduce(0,(acc,n)->acc+n)); 4 System.out.println(sum); 5 } 6 }
reduce()方法传入的对象是BinaryOperator接口,它定义了一个apply()方法,负责把上次累加的结果和本次的元素进行运算,并返回累加的结果:
1 @FunctionalInterface 2 public interface BinaryOperator<T>{ 3 T apply(T t,T u); 4 }
上述代码看上去不好理解,但我们用for循环改写一下,就容易理解了:
1 Stream<Integer> stream = ... 2 int sum = 0; 3 for(n:stream){ 4 sum = (sum,n)->sum+n; 5 }
可见,reduce()操作首先初始化结果为指定值(这里是0),紧接着,reduce()对每个元素依次调用(acc,n)->acc+n,其中,acc是上次计算的结果
acc = 0 acc = acc + n = 0+ 1 =1// n = 1 acc = acc + n = 1 + 2 = 3 // n = 2 acc = acc + n = 3 + 3 = 6 // n = 3 acc = acc + n = 6 + 4 = 10 // n = 4 acc = acc + n = 10 + 5 = 15 // n = 5 acc = acc + n = 15 + 6 = 21 // n = 6 acc = acc + n = 21 + 7 = 28 // n = 7 acc = acc + n = 28 + 8 = 36 // n = 8 acc = acc + n = 36 + 9 = 45 // n = 9
实际这个reduce()操作是一个求和
如果去掉初始值,我们会得到一个Optional<Integer>:
Optional<Integer> opt = stream.reduce((acc,n)->acc+n); if(opt.isPresent){ System.out.println(opt.get()); }
这是因为Stream的元素有可能是0个,这样就没法调用reduce()的聚合函数了,因此返回Optional对象,需要进一步判断结果是否存在。
利用reduce(),我们可以把求和改成求积,代码也十分简单
1 public class Main{ 2 public static void main(String[] args){ 3 int s = Stream.pf(1,2,3,4,5,6,7,8,9).reduce(1,(acc,n)->acc*n); 4 System.out.println(s);//362800 5 } 6 }
注意:计算求积时,初始值必须设置为1。
除了可以对数值进行累积计算外,灵活运用reduce()也可以对java对象进行操作。下面的代码演示了如何将配置文件的每一行配置通过map()和reduce()操作聚合成一个Map<String,String>;
1 public class Main{ 2 public static void main(String[] args){ 3 //按行读取配置文件 4 List<String> props = List.of("profile = native","debug=true","logging = warn","interval=500"); 5 Map<String,String> map = props.stream(); 6 .map(kv ->{ 7 String[] ss = kv.split("\\=",2); 8 return Map.of(ss[0],ss[1]); 9 }) 10 .reduce(new HashMap<String,String>(), 11 (m,kv)->{m.putAll(kv); 12 return m; 13 }); 14 map.forEach((k,v)->{ 15 System.out.println(k + "=" + v ); 16 }); 17 } 18 }
输出集合
我们介绍了Stream的几个常见操作:map()、filter()、reduce()。这些操作对Stream来说可以分为两类,一类是转接操作,即把一个Stream转换成另一个Stream,例如map()和filter(),另一类是聚合操作,即对Stream的每个元素进行计算,得到一个确定的结果,例如reduce()
区分这两种操作是非常重要的,因为对于Stream来说,对其进行转换操作并不会触发任何计算!
1 public class Main { 2 public static void main(String[] args) { 3 Stream<Long> s1 = Stream.generate(new NatualSupplier()); 4 Stream<Long> s2 = s1.map(n -> n * n); 5 Stream<Long> s3 = s2.map(n -> n - 1); 6 System.out.println(s3); // java.util.stream.ReferencePipeline$3@49476842 7 } 8 } 9 10 class NatualSupplier implements Supplier<Long> { 11 long n = 0; 12 public Long get() { 13 n++; 14 return n; 15 } 16 }
因为s1是一个Long类型的序列,它的元素高达922亿个,但执行上述代码,既不会有任何内存增长,也不会有任何计算,因为转换操作只是保存了转换规则,无论我们对一个Stream转换多少次,都不会有任何实际计算发生。
而聚合操作则不一样,聚合操作会立刻促使Stream输出它的每一个元素,并依次纳入计算,以获得最终结果。所以,对一个Stream进行聚合操作,会触发一系列连锁反应:
1 Stream<Long> s1 = Stream.generate(new NatualSupplier()); 2 Stream<Long> s2 = s1.map(n -> n * n); 3 Stream<Long> s3 = s2.map(n -> n - 1); 4 Stream<Long> s4 = s3.limit(10); 5 s4.reduce(0, (acc, n) -> acc + n);
我们对s4进行reduce()聚合计算,会不断请求s4输出它的每一个元素。因为s4的上游是s3,它又会向s3请求元素,导致s3向s2请求元素,s2向s1请求元素,最终,s1从Supplier实例中请求到真正的元素,并经过一系列转换,最终被reduce()聚合出结果。
可见,聚合操作是真正需要从Stream请求数据的,对一个Stream做聚合计算后,结果就不是一个Stream,而是一个其他的Java对象。
reduce()只是一种聚合操作,如果我们希望把Stream的元素保存到集合,例如List,因为List的元素是确定的Java对象,因此,把Stream变为List不是一个转换操作,而是一个聚合操作,它会强制Stream输出每个元素。
下面的代码演示了如何将一组String先过滤掉空字符串,然后把非空字符串保存到List中:
1 public class Main{ 2 public static void main(String[] args){ 3 Stream<String> stream = Stream.of("Apple","",null,"Pear"," ","Oreange"); 4 List<String> list = stream.filter(s->s!=null&&!s.isBlank()).collect(Collectors.toList()); 5 System.out.println(list); 6 } 7 }
把Stream的每个元素收集到List的方法是调用collect()并传入Collectors.toList()对象,它实际上是一个Collector实例,通过类似reduce()的操作,把每个元素添加到一个收集器中(实际上是ArrayList)。
类似的,collect(Collectors.toSet())可以把Stream的每个元素收集到Set中。
输出为数组
把Stream的元素输出为数组和输出为List类似,我们只需要调用toArray()方法,并传入数组的“构造方法”:
1 List<String> list = List.of("Apple","Banana","Orange"); 2 String[] array = list.stream().toArray(String[]::new);
注意到传入的“构造方法”是String[]::new,它的签名实际上是IntFunction<String[]>定义的String[] apply(int),即传入int参数,获得String[]数组的返回值。
输出为Map
如果我们要把Stream的元素收集到Map中,就稍微麻烦一点。因为对于每个元素,添加到Map时需要key和value,因此,我们要指定两个映射函数,分别把元素映射为key和value:
1 public class Main { 2 public static void main(String[] args) { 3 Stream<String> stream = Stream.of("APPL:Apple", "MSFT:Microsoft"); 4 Map<String, String> map = stream 5 .collect(Collectors.toMap( 6 // 把元素s映射为key: 7 s -> s.substring(0, s.indexOf(':')), 8 // 把元素s映射为value: 9 s -> s.substring(s.indexOf(':') + 1))); 10 System.out.println(map); 11 } 12 }
{MSFT=Microsoft, APPL=Apple}
分组输出
Stream还有一个强大的分组功能,可以按组输出。我们看下面的例子:
1 public class Main { 2 public static void main(String[] args) { 3 List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); 4 Map<String, List<String>> groups = list.stream() 5 .collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList())); 6 System.out.println(groups); 7 } 8 }
{A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry]}
分组输出使用Collectors.groupingBy(),它需要提供两个函数:一个是分组的key,这里使用s -> s.substring(0, 1),表示只要首字母相同的String分到一组,第二个是分组的value,这里直接使用Collectors.toList(),表示输出为List
排序
对Stream的元素进行排序十分简单,只需调用sorted()方法:
1 public class Main { 2 public static void main(String[] args) { 3 List<String> list = List.of("Orange", "apple", "Banana") 4 .stream() 5 .sorted() 6 .collect(Collectors.toList()); 7 System.out.println(list); 8 } 9 }
[Banana, Orange, apple]
此方法要求Stream的每个元素必须实现Comparable接口。如果要自定义排序,传入指定的Comparator即可,sorted()只是一个转换操作,它会返回一个新的Stream。
去重
对一个Stream的元素进行去重,没必要先转换为Set,可以直接用distinct():
1 List.of("A", "B", "A", "C", "B", "D") 2 .stream() 3 .distinct() 4 .collect(Collectors.toList()); // [A, B, C, D]
截取
截取操作常用于把一个无限的Stream转换成有限的Stream,skip()用于跳过当前Stream的前N个元素,limit()用于截取当前Stream最多前N个元素:
1 List.of("A", "B", "C", "D", "E", "F") 2 .stream() 3 .skip(2) // 跳过A, B 4 .limit(3) // 截取C, D, E 5 .collect(Collectors.toList()); // [C, D, E]
截取操作也是一个转换操作,将返回新的Stream。
合并
将两个Stream合并为一个Stream可以使用Stream的静态方法concat():
Stream<String> s1 = List.of("A", "B", "C").stream();
Stream<String> s2 = List.of("D", "E").stream();
// 合并:
Stream<String> s = Stream.concat(s1, s2);
System.out.println(s.collect(Collectors.toList())); // [A, B, C, D, E]
flatMap
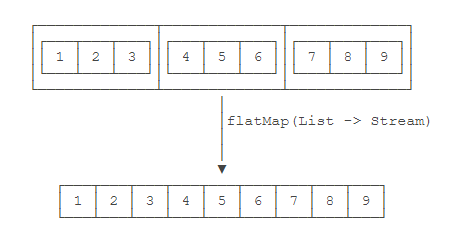
如果Stream的元素是集合:
1 Stream<List<Integer>> s = Stream.of( 2 Arrays.asList(1, 2, 3), 3 Arrays.asList(4, 5, 6), 4 Arrays.asList(7, 8, 9));
而我们希望把上述Stream转换为Stream<Integer>,就可以使用flatMap():
Stream<Integer> i = s.flatMap(list -> list.stream());
因此,所谓flatMap(),是指把Stream的每个元素(这里是List)映射为Stream,然后合并成一个新的Stream:
并行
通常情况下,对Stream的元素进行处理是单线程的,即一个一个元素进行处理。但是很多时候,我们希望可以并行处理Stream的元素,因为在元素数量非常大的情况,并行处理可以大大加快处理速度。
把一个普通Stream转换为可以并行处理的Stream非常简单,只需要用parallel()进行转换:
1 Stream<String> s = ... 2 String[] result = s.parallel() // 变成一个可以并行处理的Stream 3 .sorted() // 可以进行并行排序 4 .toArray(String[]::new);
经过parallel()转换后的Stream只要可能,就会对后续操作进行并行处理。我们不需要编写任何多线程代码就可以享受到并行处理带来的执行效率的提升。
其他聚合方法
除了reduce()和collect()外,Stream还有一些常用的聚合方法:
count():用于返回元素个数;max(Comparator<? super T> cp):找出最大元素;min(Comparator<? super T> cp):找出最小元素。
针对IntStream、LongStream和DoubleStream,还额外提供了以下聚合方法:
sum():对所有元素求和;average():对所有元素求平均数。
还有一些方法,用来测试Stream的元素是否满足以下条件:
boolean allMatch(Predicate<? super T>):测试是否所有元素均满足测试条件;boolean anyMatch(Predicate<? super T>):测试是否至少有一个元素满足测试条件。
最后一个常用的方法是forEach(),它可以循环处理Stream的每个元素,我们经常传入System.out::println来打印Stream的元素:
1 Stream<String> s = ... 2 s.forEach(str -> { 3 System.out.println("Hello, " + str); 4 });
Stream提供的常用操作有:
转换操作:map(),filter(),sorted(),distinct();
合并操作:concat(),flatMap();
并行处理:parallel();
聚合操作:reduce(),collect(),count(),max(),min(),sum(),average();
其他操作:allMatch(), anyMatch(), forEach()。
参考:https://www.liaoxuefeng.com/wiki/1252599548343744/1305158055100449