目录
文章目录
文章目录
《C 语言编程 — GCC 工具链》
《C 语言编程 — 程序的编译流程》
《C 语言编程 — 静态库、动态库和共享库》
《C 语言编程 — 程序的装载与运行》
《计算机组成原理 — 指令系统》
《C 语言编程 — 结构化程序流的汇编代码与 CPU 指令集》
为什么要保留汇编语言
汇编语言是与机器语言最接近的高级编程语言(或称为中级编程语言),汇编语言基本上与机器语言对应,即汇编指令和计算机指令是相对匹配的。虽然汇编语言具有与硬件的关系密切,占用内存小,运行速度快等优点,但也具有可读性低、可重用性差,开发效率低下等问题。高级语言的出现是为了解决这些问题,让软件开发变得更加简单高效,易于协作。但高级语言也存在自己的缺陷,例如:难以编写直接操作硬件设备的程序等。
所以为了权衡上述的问题,最终汇编语言被作为中间的状态保留了下来。一些高级语言(e.g. C 语言)提供了与汇编语言之间的调用接口,汇编程序可作为高级语言的外部过程或函数,利用堆栈在两者之间传递参数或参数的访问地址。两者的源程序通过编译或汇编生成目标文件(OBJ)之后再利用连接程序(linker)把它们连接成为可执行文件便可在计算机上运行了。保留汇编语言还为程序员提供一种调优的手段,无论是 C 程序还是 Python 程序,当我们要进行代码性能优化时,了解程序的汇编代码是一个不错的切入点。
顺序程序流
计算机指令是一种逻辑上的抽象设计,而机器码则是计算机指令的物理表现。机器码(Machine Code),又称为机器语言,本质是由 0 和 1 组成的数字序列。一条机器码就是一条计算机指令。程序由指令组成,但让人类使用机器码来编写程序显然是不人道的,所以逐步发展了对人类更加友好的高级编程语言。这里我们需要了解计算机是如何将高级编程语言编译为机器码的。
Step 1. 编写高级语言程序。
// test.c
int main()
{
int a = 1;
int b = 2;
a = a + b;
}
Step 2. 编译(Compile),将高级语言编译成汇编语言(ASM)程序。
$ gcc -g -c test.c
Step 3. 使用 objdump 命令反汇编目标文件,输出可阅读的二进制信息。下述左侧的一堆数字序列就是一条条机器码,右侧 push、mov、add、pop 一类的就是汇编代码。
$ objdump -d -M intel -S test.o
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
}
18: 5d pop rbp
19: c3 ret
NOTE:这里的程序入口是 main() 函数,而不是第 0 条汇编代码。

条件程序流
值得注意的是,某些特殊的指令,比如跳转指令,会主动修改 PC 的内容,此时下一条地址就不是从存储器中顺序加载的了,而是到特定的位置加载指令内容。这就是 if…else 条件语句,while/for 循环语句的底层支撑原理。

Step 1. 编写高级语言程序。
// test.c
#include <time.h>
#include <stdlib.h>
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
}
Step 2. 编译(Compile),将高级语言编译成汇编语言。
$ gcc -g -c test.c
Step 3. 使用 objdump 命令反汇编目标文件,输出可阅读的二进制信息。我们主要分析 if…else 语句。
if (r == 0)
33: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
37: 75 09 jne 42 <main+0x42>
{
a = 1;
39: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
40: eb 07 jmp 49 <main+0x49>
} else {
a = 2;
42: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
}
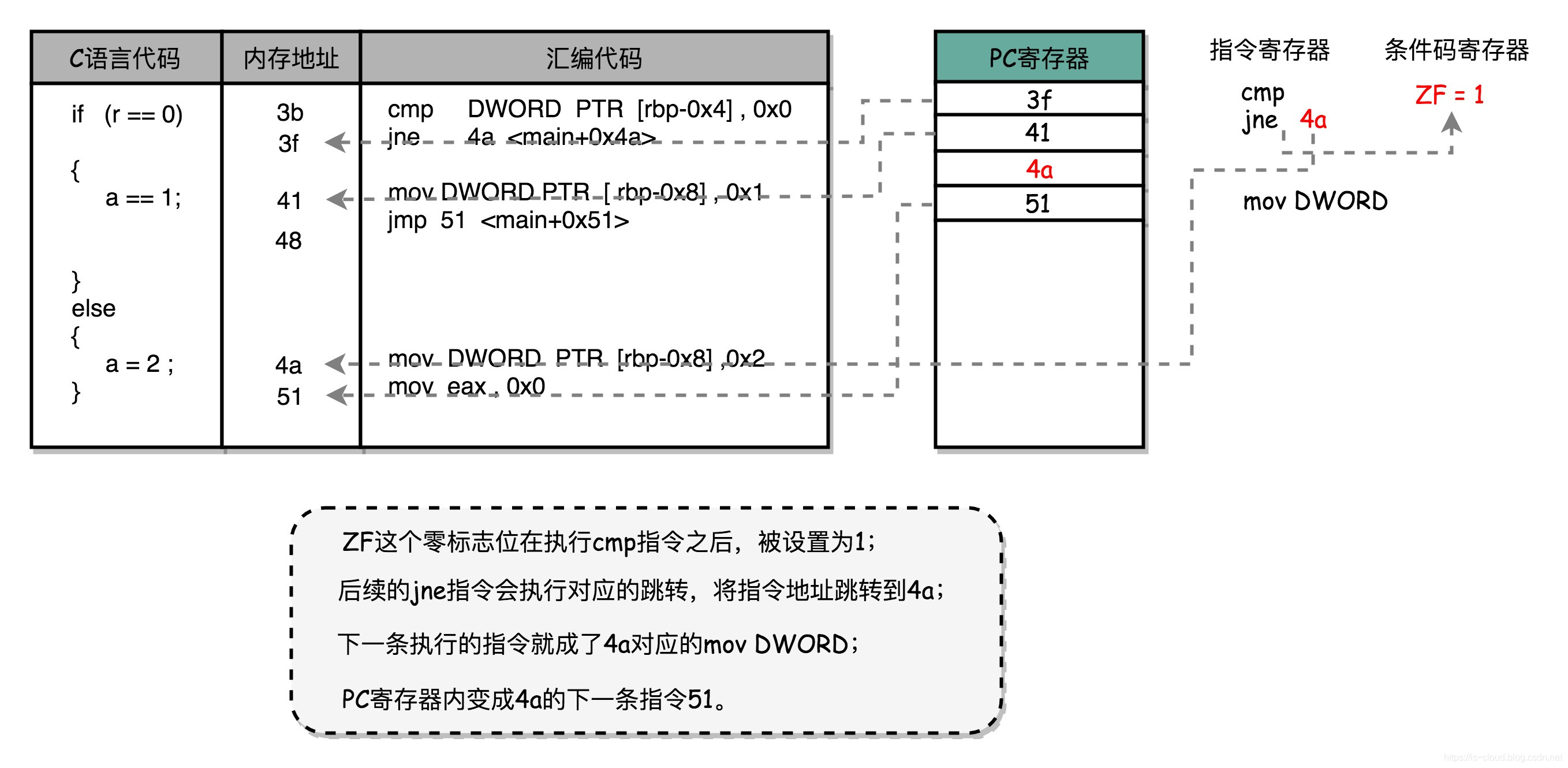
首先进入条件判断,汇编代码为 cmp 比较指令,比较数 1:DWORD PTR [rbp-0x4] 表示变量 r 是一个 32 位整数,数据在寄存器 [rbp-0x4] 中;比较数 2:0x0 表示常量 0 的十六进制。比较的结果会存入到 条件码寄存器,等待被其他指令读取。当判断条件为 True 时,ZF 设置为 1,反正设置为 0。
条件码寄存器(Condition Code)是一种单个位寄存器,它们的值只能为 0 或者 1。当有算术与逻辑操作发生时,这些条件码寄存器当中的值就随之发生变化。后续的指令通过检测这些条件码寄存器来执行条件分支指令。常用的条件码类型如下:
- CF:进位标志寄存器。最近的操作是最高位产生了进位。它可以记录无符号操作的溢出,当溢出时会被设为 1。
- ZF:零标志寄存器,最近的操作得出的结果为 0。当计算结果为 0 时将会被设为 1。
- SF:符号标志寄存器,最近的操作得到的结果为负数。当计算结果为负数时会被设为 1。
- OF:溢出标志寄存器,最近的操作导致一个补码溢出(正溢出或负溢出)。当计算结果导致了补码溢出时,会被设为 1。
回到正题,PC 继续自增,执行下一条 jnp 指令。jnp(jump if not equal)会查看 ZF 的内容,若为 0 则跳转到地址 42 <main+0x42>(42 表示汇编代码的行号)。前文提到,当 CPU 执行跳转类指令时,PC 就不再通过自增的方式来获得下一条指令的地址,而是直接被设置了 42 行对应的地址。由此,CPU 会继续将 42 对应的指令读取到 IR 中并执行下去。
42 行执行的是 mov 指令,表示将操作数 2:0x2 移入到 操作数 1:DWORD PTR [rbp-0x8] 中。就是一个赋值语句的底层实现支撑。接下来 PC 恢复如常,继续以自增的方式获取下一条指令的地址。
循环程序流
- C 语言代码
// test.c
int main()
{
int a = 0;
int i;
for (i = 0; i < 3; i++)
{
a += i;
}
}
- 计算机指令与汇编代码
for (i = 0; i < 3; i++)
b: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x8],0x0
12: eb 0a jmp 1e <main+0x1e>
{
a += i;
14: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
17: 01 45 fc add DWORD PTR [rbp-0x4],eax
for (i = 0; i < 3; i++)
1a: 83 45 f8 01 add DWORD PTR [rbp-0x8],0x1
1e: 83 7d f8 02 cmp DWORD PTR [rbp-0x8],0x2
22: 7e f0 jle 14 <main+0x14>
}

函数调用栈的工作原理
与普通的跳转程序(e.g. if…else、while/for)不同,函数调用的特点在于具有回归(return)的特点,在调用的函数执行完之后会再次回到执行调用的 call 指令的位置,继续往下执行。能够实现这个效果,完全依赖堆栈(Stack)存储区的特性。 首先我们需要了解几个概念。
-
堆栈(Stack):是有若干个连续的存储器单元组成的先进后出(FILO)存储区,用于提供操作数、保存运算结果、暂存中断和子程序调用时的线程数据及返回地址。通过执行堆栈的 Push(压栈)和 Pop(出栈)操作可以将指定的数据在堆栈中放入和取出。堆栈具有栈顶和栈底之分,栈顶的地址最低,而栈底的地址最高。堆栈的 FILO 的特性非常适用于函数调用的场景:父函数调用子函数,父函数在前,子函数在后;返回时,子函数先返回,父函数后返回。
-
栈帧(Stack Frame):是堆栈中的逻辑空间,每次函数调用都会在堆栈中生成一个栈帧,对应着一个未运行完的函数。从逻辑上讲,栈帧就是一个函数执行的环境,保存了函数的参数、函数的局部变量以及函数执行完后返回到哪里的返回地址等等。栈帧的本质是两个指针寄存器: EBP(基址指针,又称帧指针)和 ESP(栈指针)。其中 EBP 指向帧底,而 ESP 指向栈顶。当程序运行时,ESP 是可以移动的,大多数信息的访问都通过移动 ESP 来完成,而 EBP 会一直处于帧低。EBP ~ ESP 之间的地址空间,就是当前执行函数的地址空间。
NOTE:EBP 指向当前位于系统栈最上边一个栈帧的底部,而不是指向系统栈的底部。严格说来,“栈帧底部” 和 “系统栈底部” 不是同一个概念,而 ESP 所指的栈帧顶部和系统栈顶部是同一个位置。
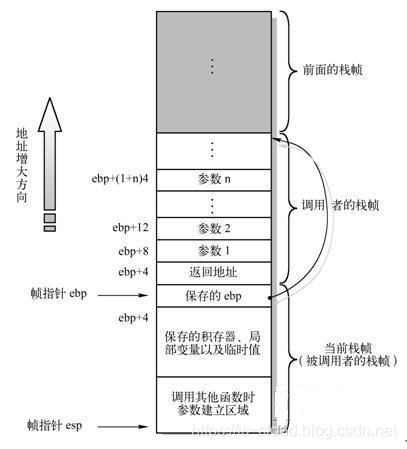
简单概括一下函数调用的堆栈行为,ESP 随着当前函数的压栈和出栈会不断的移动,但由于 EBP 的存在,所以当前执行函数栈帧的边界是始终清晰的。当一个当前的子函数调用完成之后,EBP 就会跳到父函数栈帧的底部,而 ESP 也会随其自然的来到父函数栈帧的头部。所以,理解函数调用堆栈的运作原理,主要要掌握 EBP 和 ESP 的动向。下面以一个例子来说明。
NOTE:我们习惯将将父函数(调用函数的函数)称为 “调用者(Caller)”,将子函数(被调用的函数)称为 “被调用者(Callee)”。
- C 程序代码
#include <stdio.h>
int add(int a, int b) {
int result = 0;
result = a + b;
return result;
}
int main(int argc, char *argv[]) {
int result = 0;
result = add(1, 2);
printf("result = %d \r\n", result);
return 0;
}
- 使用gcc编译,然后gdb反汇编main函数,看看它是如何调用add函数的
(gdb) disassemble main
Dump of assembler code for function main:
0x08048439 <+0>: push %ebp
0x0804843a <+1>: mov %esp,%ebp
0x0804843c <+3>: and $0xfffffff0,%esp
0x0804843f <+6>: sub $0x20,%esp
0x08048442 <+9>: movl $0x0,0x1c(%esp) # 给 result 变量赋 0 值
0x0804844a <+17>: movl $0x2,0x4(%esp) # 将第 2 个参数 argv 压栈(该参数偏移为esp+0x04)
0x08048452 <+25>: movl $0x1,(%esp) # 将第 1 个参数 argc 压栈(该参数偏移为esp+0x00)
0x08048459 <+32>: call 0x804841c <add> # 调用 add 函数
0x0804845e <+37>: mov %eax,0x1c(%esp) # 将 add 函数的返回值地址赋给 result 变量,作为子函数调用完之后的回归点
0x08048462 <+41>: mov 0x1c(%esp),%eax
0x08048466 <+45>: mov %eax,0x4(%esp)
0x0804846a <+49>: movl $0x8048510,(%esp)
0x08048471 <+56>: call 0x80482f0 <printf@plt>
0x08048476 <+61>: mov $0x0,%eax
0x0804847b <+66>: leave
0x0804847c <+67>: ret
End of assembler dump.
(gdb) disassemble add
Dump of assembler code for function add:
0x0804841c <+0>: push %ebp # 将 ebp 压栈(保存函数调用者的栈帧基址)
0x0804841d <+1>: mov %esp,%ebp # 将 ebp 指向栈顶 esp(设置当前被调用函数的栈帧基址)
0x0804841f <+3>: sub $0x10,%esp # 分配栈空间(栈向低地址方向生长)
0x08048422 <+6>: movl $0x0,-0x4(%ebp) # 给 result 变量赋 0 值(该变量偏移为ebp-0x04)
0x08048429 <+13>: mov 0xc(%ebp),%eax # 将第 2 个参数的值赋给 eax 寄存器(准备运算)
0x0804842c <+16>: mov 0x8(%ebp),%edx # 将第 1 个参数的值赋给 edx 寄存器(准备运算)
0x0804842f <+19>: add %edx,%eax # 运算器执行加法运算 (edx+eax),结果保存在 eax 寄存器中
0x08048431 <+21>: mov %eax,-0x4(%ebp) # 将运算结果 eax 赋给 result 变量
0x08048434 <+24>: mov -0x4(%ebp),%eax # 将 result 变量的值赋给 eax 寄存器(eax 的地址将作为函数返回值)
0x08048437 <+27>: leave # 恢复函数调用者的栈帧基址(pop %ebp)
0x08048438 <+28>: ret # 返回(准备执行下条指令)
End of assembler dump.
- 示意图

可见,每一次函数调用,都会对调用者的栈帧基址 EBP 进行压栈操作(为了调用回归),并且由于子函数的栈帧基址 EBP 来自于栈指针 ESP 而来(生成新的子函数的栈帧),所以各层函数的栈帧基址很巧妙的构成了一个链,即当前的栈帧基址指向下一层函数栈帧基址所在的位置。

由此当子函数执行完成时,ESP 依旧在栈顶,但 EBP 就跳转到父函数的栈帧底部了,并且堆栈下一个弹出的就是子函数的调用回归点,最终程序流回到调用点并继续往下执行。
通过函数调用堆栈的工作原理我们可以看出,无论程序中具有多少层的函数调用,或递归调用,只需要维护好每个栈帧的 EBP 和 ESP 就可以管理还函数之间的跳转。但堆栈也是由容量限制的,如果函数调用的层级太多就会出现栈溢出的错误(Stack Overflow)。