1,安装 与 启动
1,环境:centos7,这里不推荐使用 windows 系统,可以免去很多不必要的麻烦
2,安装:pip3 install scrapyd
3,启动:scrapyd
2,配置文件
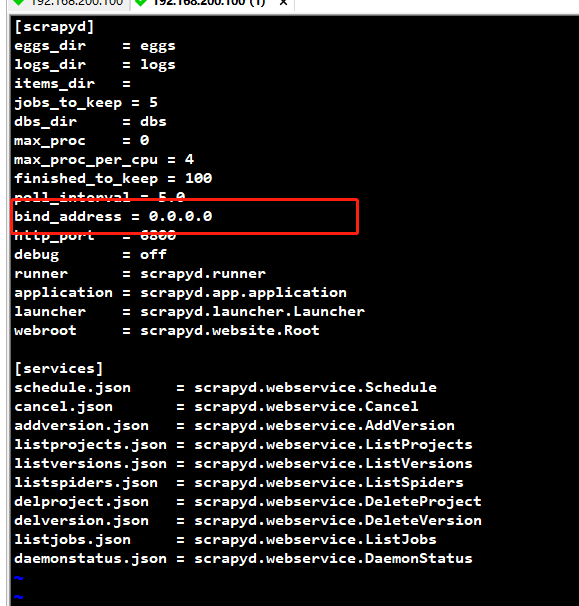
1, 所在地址 /usr/local/lib/python3.6/site-packages/scrapyd/default_scrapyd.conf
2,配置能被外网访问,将配置文件的下图中的一项设置为 0.0.0.0
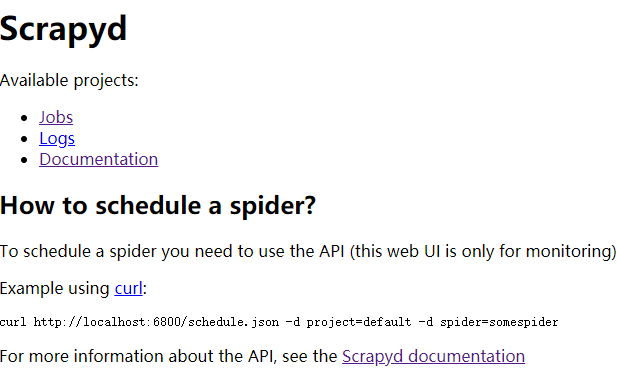
3,测试是否启动成功,浏览器访问 ip:6800,如笔者为 192.168.200.100:6800,出现如下界面为安装成功
3,部署自己的爬虫
1,安装客户端:pip3 install scrapyd-client
2,修改爬虫项目根目录下的自带配置文件:scrapy.cfg
[settings]
default = reptile.settings
[deploy:reptile] # deploy 后面的为自定义客户端名
url = http://localhost:6800/ # 服务器的地址
project = reptile # 项目名称
3,查看当前项目有多少可以部署的爬虫,注意命令要在项目根路径下执行
scrapy list

4,获取当前项目的配置的:客户端名称 和 服务器地址,同时检测模块依赖是否安装完整
scrapyd-deploy -l

5,安装完依赖模块后,部署项目,命令格式为:scrapyd-deploy 客户端名 -p 项目名
scrapyd-deploy reptile -p reptile

curl http://localhost:6800/schedule.json -d project=reptile -d spider=court_headlines