故事是这样子的:PM说需要将一批线下数据文件(只存放bid),需要通过bid查询数据获取基本信息以及股东信息,最后拼接成新的数据。
一开始:我想着从数据库直接查询sql语句不就可以了吗?简单的很。
但是我说了我的想法之后被老大果断丢弃掉了(这批数据量很大,而且还的在线上查询,这样对数据库影响很大),于是告诉了我了解一下:hadoop、spark。我说好的。
好了,已上都不是重点,重点开始了,只介绍命令以及实现过程。
Hadoop简单介绍
Hadoop是一个开源框架,可编写和运行分布式应用来处理大规模数据,分布式计算是一个不断变化且宽泛的领域。
优点:
1.易用性。Hadoop运行在由一般商用机器构成的大型集群上。
2.可靠性。Hadoop致力于一般商用机器上,其架构假设硬件会频繁出现失效,它可以从容处理大多数此类故障。
3.可扩展。Hadoop通过增加集群节点,可以线性地拓展以处理更大数据集。
4.简单。Hadoop允许用户快速的编写出高效地并行代码。
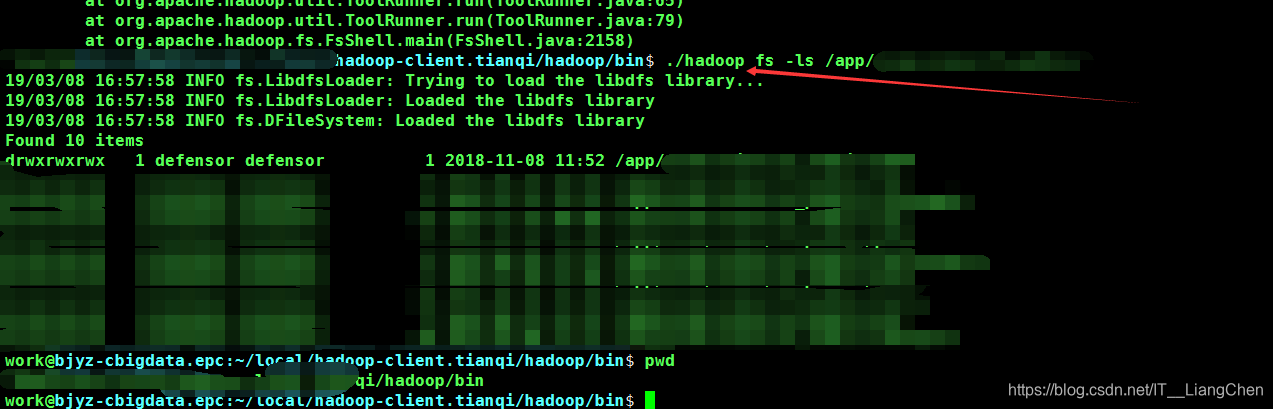
a. 查看hadoop文件:hadoop fs -ls [local | ]
具体hadoop命令: https://blog.csdn.net/wuwenxiang91322/article/details/22166423
Spark简单介绍
在我的理解spark相当于Navvicat一个连接数据库的工具,hadoop相当于数据库。
当然更详细更彻底的理解个人推荐:https://blog.csdn.net/qq_34795664/article/details/79946527
但是,博主的安装我没有实际性操作过,我的都是公司内部本身就有的。
连接命令(不懂字段含义可自行百度):./pyspark --num-executors=xxx --executor-cores=xxx --master=yarn --queue=spark-defensor --name=xxx
输出数据表字段:v00001.printSchema()
输出数据具体内容:v00001.show()
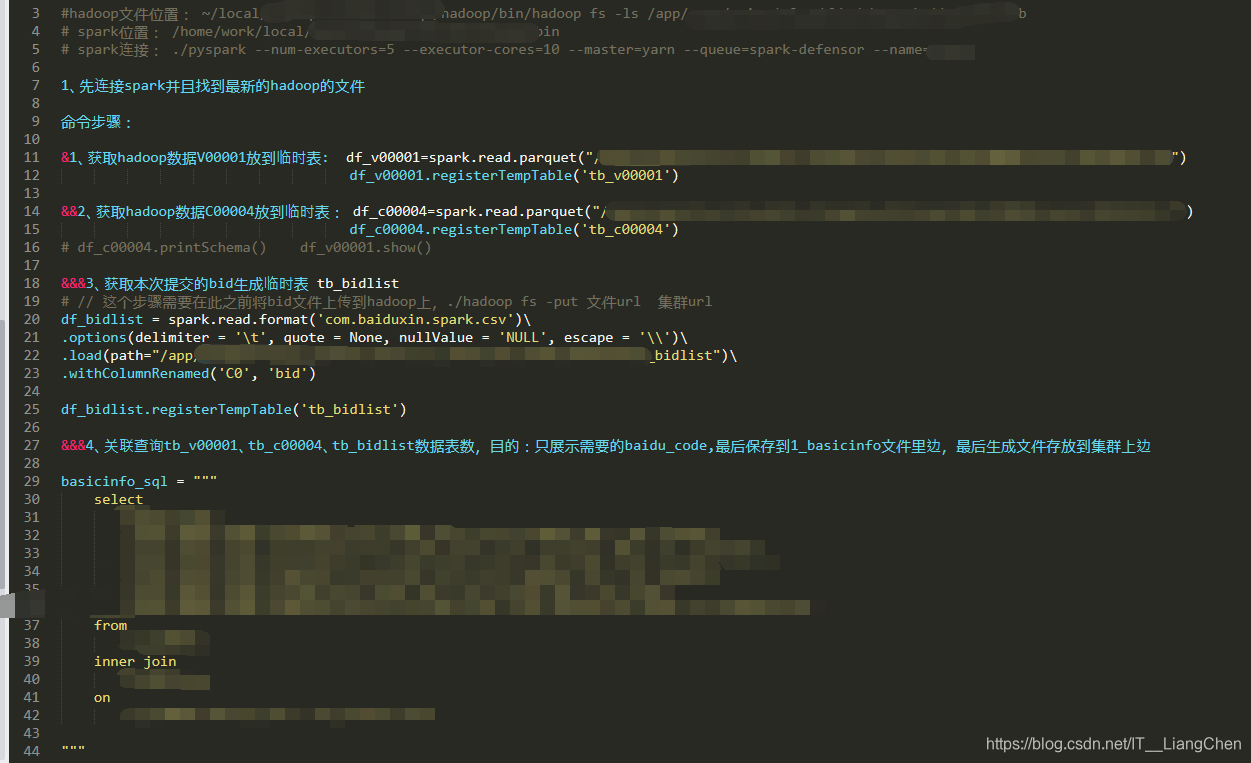
实现步骤:
- 1、先获取hadoop数据V00001文件数据 – 存储到临时表 tb_v00001。
- 2、获取hadoop数据C00004文件数据 – 存储到临时表 tb_c00004。
- 3、获取本次需要的bid文件数据 – 存储到临时表 tb_bidlist。
- 4、关联查询tb_v00001、tb_c00004、tb_bidlist数据表数,目的:只展示需要的bid,最后保存到1_basicinfo文件里边,最后生成文件存放到集群上边
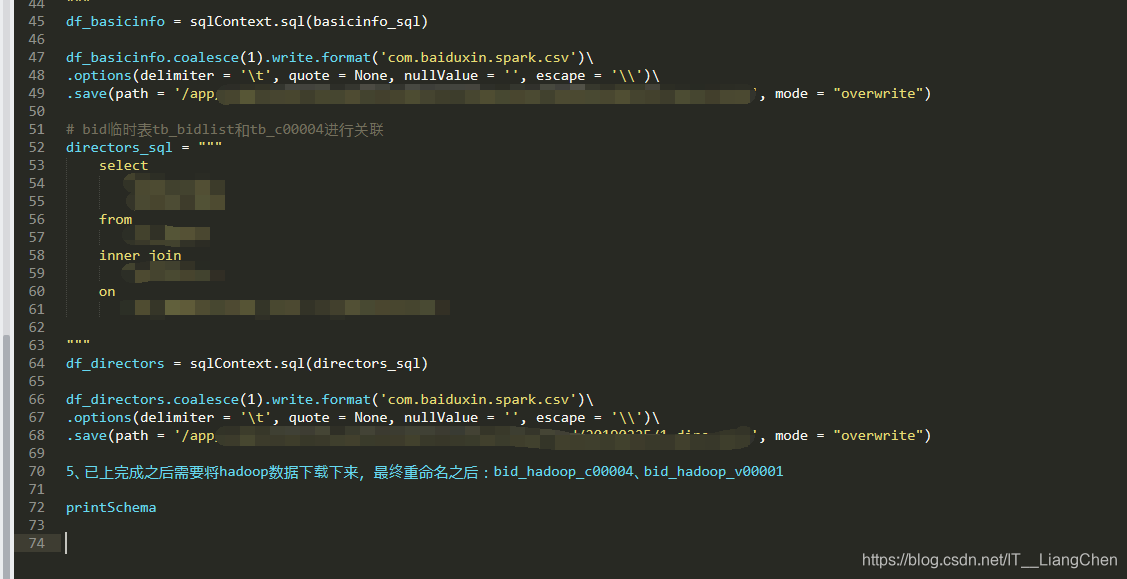
- 5、已上完成之后需要将hadoop数据下载下来
命令:
1、获取文件数据赋值到变量 df_v00001=spark.read.parquet("/app/xxxx.txt")
2、生成临时表:df_v00001.registerTempTable(‘tb_v00001’)
3、讲本地文件数据获取到并且加上数据表字段存到临时表:df_bidlist = spark.read.format(‘XXX’)
.options(delimiter = ‘\t’, quote = None, nullValue = ‘NULL’, escape = ‘\’)
.load(path="/xxxxxxxxx/20190225/0_bidlist")
.withColumnRenamed(‘C0’, ‘bid’)
4、sql语句查询:df_basicinfo = sqlContext.sql(basicinfo_sql)
5、将查询到数据以一定格式保存到本地文件:df_basicinfo.coalesce(1).write.format(‘xxx’)
.options(delimiter = ‘\t’, quote = None, nullValue = ‘’, escape = ‘\’)
.save(path = ‘/xxxx/1_basicinfo’, mode = “overwrite”)