Redis.conf详解
启动的时候,就通过配置文件来启动!
-
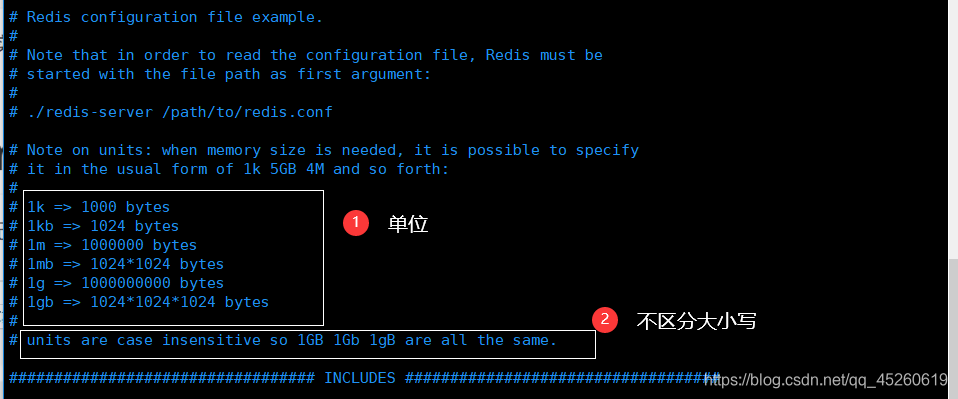
基本介绍
-
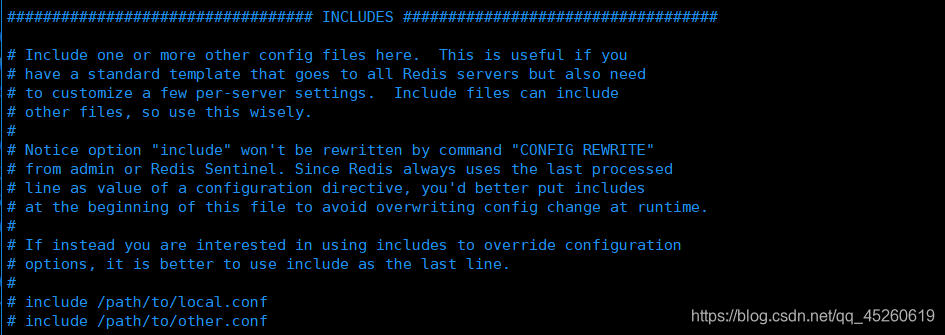
包含(INCLUDES)
-
网络
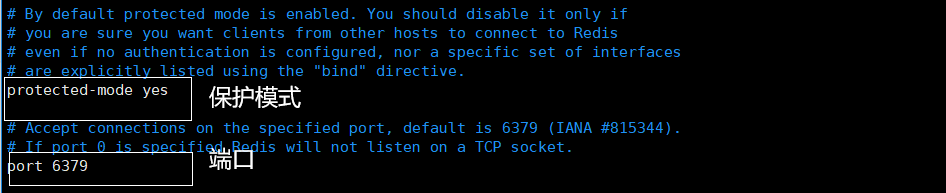
- bind 127.0.0.1 #绑定的ip

- protected-mode yes # 保护模式
- bind 127.0.0.1 #绑定的ip
-
通用 (GENERAL)
-
daemonize yes # 以守护进程的方式运行(后台运行),默认是 no , 我们需要自己开启 yes

-
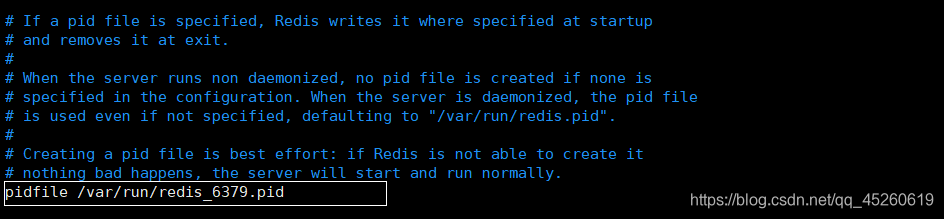
pidfile /var/run/redis_6379.pid #如果以后台方式运行,我们就需要指定一个pid文件
-
loglevel notice #日志等级
-logfile “” # 日志的文件位置名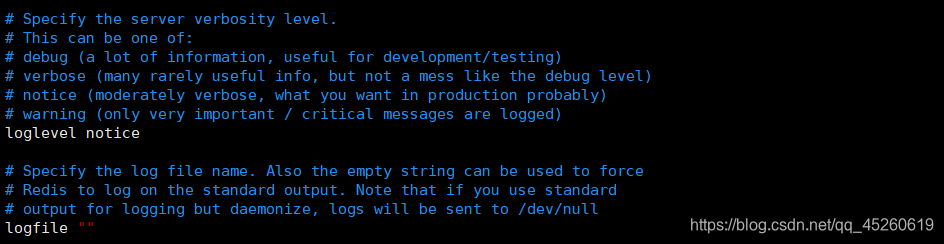
-
databases 16 # 数据库数量 默认16个
扫描二维码关注公众号,回复: 11349149 查看本文章
-
always-show-logo yes # 是否总是显示LOGO 开启服务是的logo
-
-
快照
持久化,在规定的时间内执行了多少次,则会持久化到我们的文件。
redis 是内存数据库,如果没有持久化,那么数据断电即失去。
save 900 1 # 如果 900s 内,如果至少有 1 个key 进行了修改,那么就进行持久化操作。
save 300 10
save 60 10000 # 之后学习持久化,会自己定义
stop-writes-on-bgsave-error yes # 持久化如果出错了,是否还需要继续工作
rdbcompression yes # 是否压缩 rdb 文件,需要消耗 CPU 资源
rdbchecksum yes # 保存 rdb 文件的时候,进行错误的检查
dir ./ # rdb 文件保存的目录- 安全(SECURITY)
可以在这里设置redis的密码,默认是没有密码的!
127.0.0.1:6379> config get requirepass # 查看密码
1) "requirepass"
2) ""
127.0.0.1:6379> config set requirepass "123456" # 设置redis密码
OK
127.0.0.1:6379> ping # 发现所有的命令都没有权限了
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth 123456 # 使用密码登录
OK
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> config get requirepass
1) "requirepass"
2) "123456"Redis持久化
重点!
RDB (Redis DataBase)
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的 Snapshot 快照,它恢复时,是将快照文件直接读入内存。
Redis 会单独创建 (fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何 IO 操作的。这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那么 RDB 方式要比 AOF 方式更加的高效。
RDB 的缺点是最后一次持久化的数据可能会丢失。我们默认就是RDB,一般情况不需要修改这个配置!
rdb 保存的文件是 dump.rdb,都是在配置文件中的快照中配置
dump.rdb 文件就在 /usr/local/bin/
触发机制
1、save的规则满足的情况下,会自动触发rdb规则 #save规则就是在redis的配置文件中定义的
2、执行 flushall 命令,也会出发rdb规则
3、退出 redis,也会产生rdb 文件
如何恢复rdb文件!
1、只需要将 rdb 文件放在redis的启动目录就可以,redis启动的时候会自动检查dump.rdb 回复其中的数据。
优点 :
1、适合大规模的数据恢复!
2、对数据的完整性要求不高
缺点:
1、需要一定的时间间隔去操作!
2、fork进程的时候,会占用一定的内存空间!
AOF(Append Only File)
将我们所有命令都记录下来,恢复的时候就把这个文件全部再执行一遍。
以日志的行是来记录每个写操作,将Redis 执行过的所有指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写命令从前到后执行一次以完成数据的恢复工作。
Aof保存的是 appendonly.aof 文件
要使用AOF,只需要在redis的配置文件中将 appendonly后边默认的 no 改为 yes 即可!
重启redis就可以生效!
shutdown
exit
redis-server myconfig/redis.conf
redis-cli -p 6379如果这个 aof 文件有错误,这时候 redis 是启动不起来的,我们需要修复这个 aof 文件。
redis 给我们提供了一个工具 redis-check-aof --fix
redis-check-aof --fix appendonly.aof优点:
1、每一次修改都同步,文件的完整性更加的好!
2、每秒同步一次,可能会丢失一秒的数据
缺点:
1、相对于数据文件来说,aof远远大于rdb,修复的速度也比 rdb慢
2、aof 运行效率也要比 rdb 慢,所以默认使用 rdb持久化!
主从复制
在Redis客户端通过info replication可以查看与复制相关的状态,对于了解主从节点的当前状态,以及解决出现的问题都会有帮助。
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制,读写分离!80%的情况都是在读!减轻主服务器压力!
最低配置: 一主二从
环境配置
只配置从库,不用配置主库!
info replication
127.0.0.1:6379> info replication #查看当前库的信息
# Replication
role:master # 角色 master
connected_slaves:0 # 没有从机
master_replid:76578db3d1f516289dace0af08811d030c6686e9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0打开4个ssh端口,3个配置,一个测试
首先复制三份redis.conf的配置文件。
对三三份配置文件修改配置,需要修改的部分有
protected-mode yes
port 6380
pidfile /var/run/redis_6381.pid # 更改pid名字
logfile "6380.log" # 防止日志文件重名
dbfilename dump6380.rdb # 防止rdb文件重名
然后启动三个redis,并查看进程:

一主二从
默认情况下,每台Redis服务器都是主节点;
一般情况下,只用配置从机就好了。
一主(79)二从(80 81)
从机 6380
[root@iz8vb4nxo286g9mk6p8fnhz bin]# redis-server myconfig/redis80.conf
[root@iz8vb4nxo286g9mk6p8fnhz bin]# redis-cli -p 6380
127.0.0.1:6380> ping
PONG
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # 用从机进行配置
OK
127.0.0.1:6380> info replication # 查看从机信息
# Replication
role:slave # 当前身份是从机
master_host:127.0.0.1 # 主机
master_port:6379 # 主机的端口
master_link_status:up # 主机的状态
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:0
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:5039f26aab7d10438ca58c066295a2f2ae7c42d1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
127.0.0.1:6380>
#查看主机
127.0.0.1:6379> info replication
# Replication
role:master # 当前身份是主机
connected_slaves:2 # 有两台从机
slave0:ip=127.0.0.1,port=6380,state=online,offset=28,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=28,lag=0
master_replid:5039f26aab7d10438ca58c066295a2f2ae7c42d1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28
127.0.0.1:6379> 真是的开发中使用配置文件来配置是永久的,我们这里使用的是命令,是暂时的!
细节
主机可以写 , 从机不可以写(只能读)
主机中的所有数据都会被从机保存。
主结点崩了 从节点还在!
如果使用命令行来配置的主从,这个时候从机断开,重启之后,就会变回主机!
还有一种连接方式:
层层链路
这时候也可以主从复制。
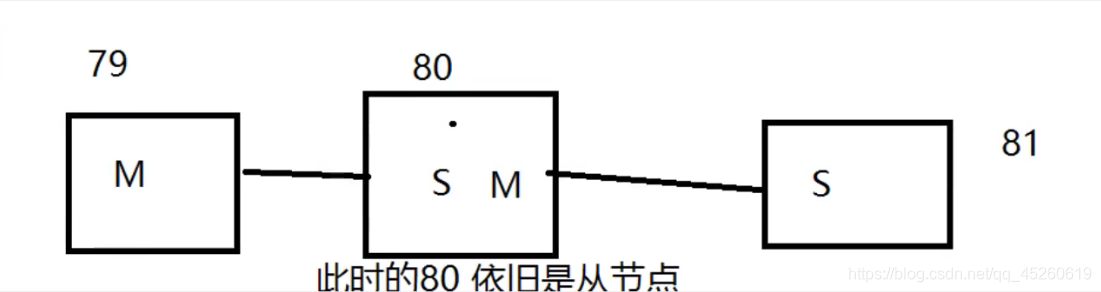
如果老大挂了,这时候需要再出来一个老大!手动!
如果主机断开了连接,我们可以使用slaveof no one来使自己成为主机
哨兵模式(自动选举老大)
概述
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
测试
目前的状态是一主二从
一、首先在 /usr/local/bin/myconfig 下创建一个
哨兵sentinel.conf ,写上下边内容
myredis : 哨兵的名字
#sentinel monitor 被监控的名称 host port 1
sentinel monitor myredis 127.0.0.1 6379 1后边这个数字1,代表主机挂了,slave 投票来看让谁接替成为主机,票数最多的成为主机。
二、启动哨兵
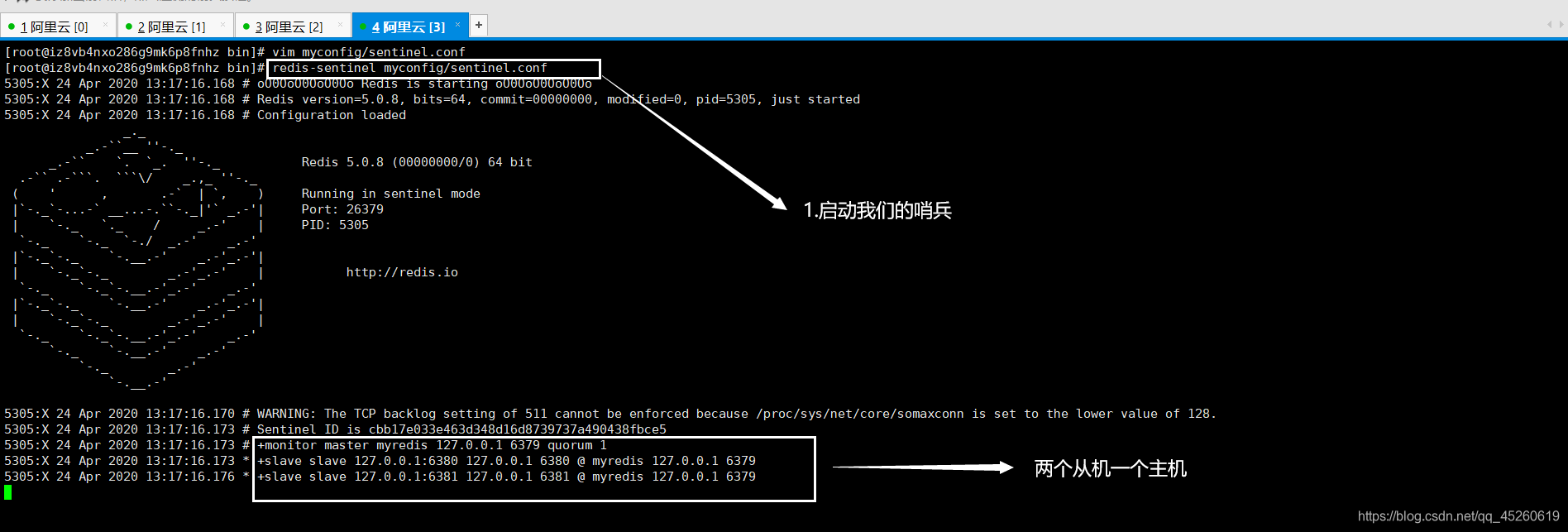 如果Master结点断开,就会在从机中随机选择一个服务器!(这里边有一个投票算法)
如果Master结点断开,就会在从机中随机选择一个服务器!(这里边有一个投票算法)
哨兵模式
优点:
1、哨兵集群,基于主从复制模式,所有主从配置优点,他全有
2、主从可以切换,故障可以转移,系统的可用性就会更好
3、哨兵模式就是主从模式的升级,手动到自动!
缺点:
1、Redis 不好在线扩容,集群容量一旦到达上限,在线扩容九十分麻烦。
2、实现哨兵模式的配置其实是很麻烦的,里面有很多选择!
缓存穿透(查不到)
概述
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
解决方案
(1) 布隆过滤器
布隆过滤器是一种数据结构,垃圾网站和正常网站加起来全世界据统计也有几十亿个。网警要过滤这些垃圾网站,总不能到数据库里面一个一个去比较吧,这就可以使用布隆过滤器。假设我们存储一亿个垃圾网站地址。
可以先有一亿个二进制比特,然后网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。接下来用一个随机数产生器 G 把这八个信息指纹映射到 1 到1亿中的八个自然数 g1, g2, …,g8。最后把这八个位置的二进制全部设置为一。过程如下:
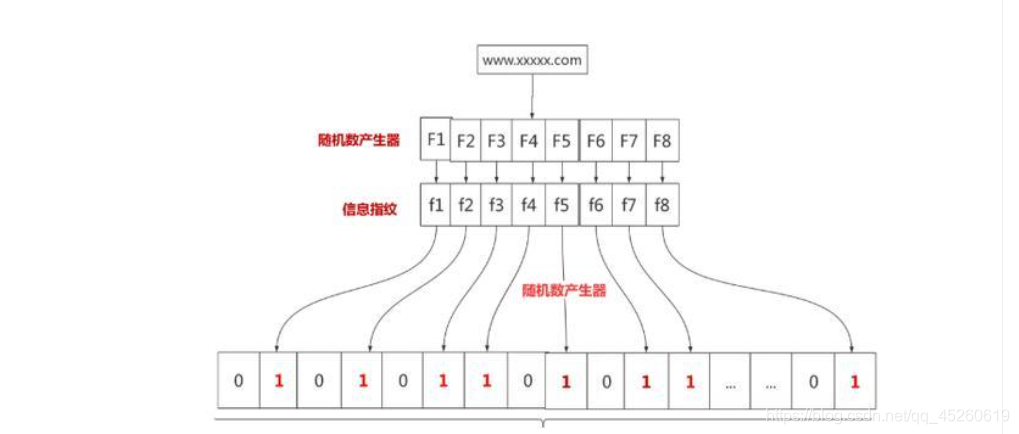
有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,首先将可疑网站通过哈希映射到1亿个比特数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。
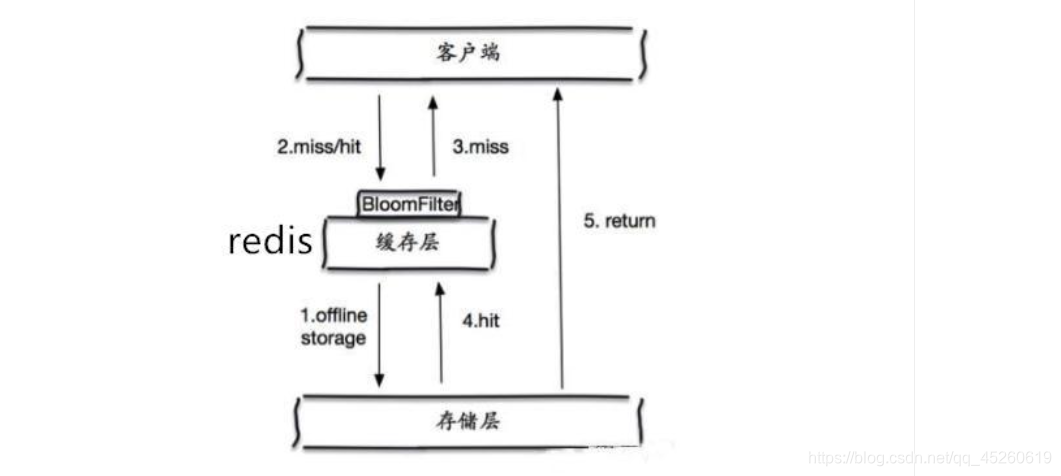
(2) 缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
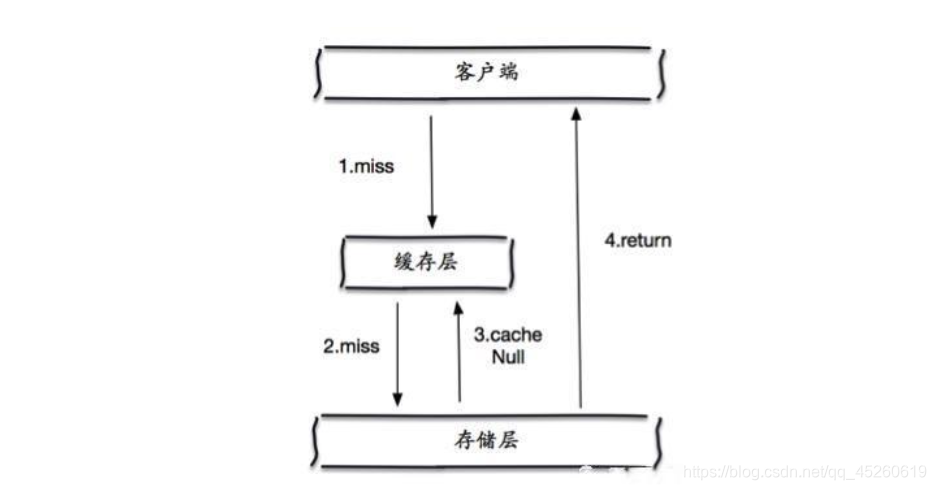
但是这种方法会存在两个问题:
- 如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
- 即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期!)
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞
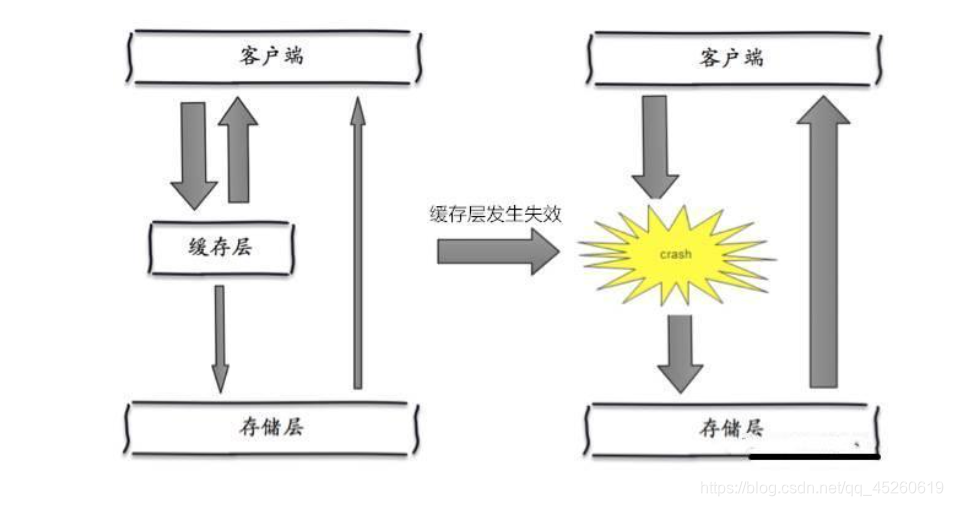
缓存雪崩
缓存雪崩是指,缓存层出现了错误,不能正常工作了。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。