2020中国高校计算机大赛·华为云大数据挑战赛-数据分析(二)
哈喽,小伙伴们好久不见,这几个星期由于个人原因,都没时间做比赛,直到最近几天开始做了下,趁周日写下分享记录,分数虽然不高,但是分享出来一些清洗数据和特征工程的看法,希望对大家有所帮助和启发。
这里继续上次的分析,上一篇我们主要分析了数据的结构,现在我们着重看下数据的gps。
一、行船轨迹
这里我画了几张相同trace的行船记录,看看他们的轨迹是否一致,为了和test保持一致,我画了出现在test里面的trace.

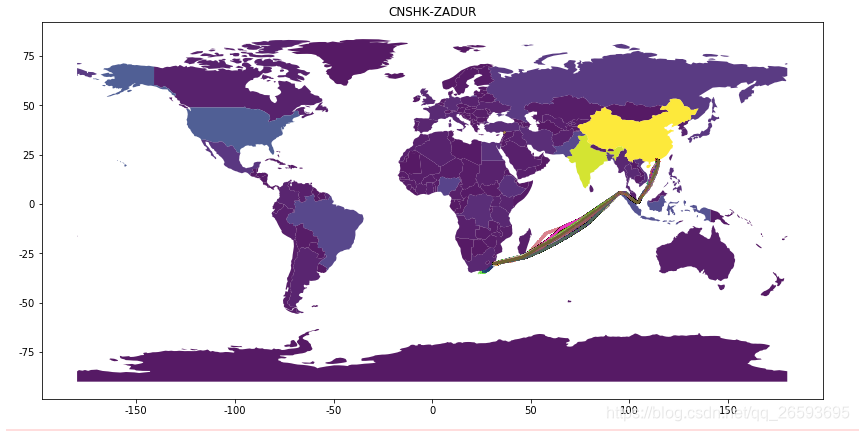


上面的轨迹图可以看出,一些轨迹还是比较规整的,但是一部分轨迹是存在不一致的,有的船可能因为总总原因,并不是按原路线行驶,甚至会有提前登陆的情况,这种情况在test可能也会发生。为此 我们在看看test里面截断的路线是怎样的



从test里面的gps轨迹可以看出来,一半截取的是前面的一小段,而后的记录几乎没有,这就需要我们的模型能够从test里面识别出完整的路劲,以及当前航道的目的地是哪里,这样才能准确预测到港时间。
从另一个角度来说就是通过test被截取的gps轨迹数据,能够在train里面找到相近的gps轨迹数据,从而找出这段轨迹对应的完整路劲。当然 通过trace字段也可以粗略知道轨迹,但是可能港口的名字有误差并不统一,或者说实际到港的目的地与trace并不相符,实际路劲也是有差别的,需要好好做数据清洗的工作。
二、数据提取
1、首先我们从20G的数据中,先通过流的方式逐一读取,由于test里面没有vesselNextport等字段,所以我暂时把这些字段都删除了,并对一些数值特征进行了类型转化,最大化在不损失精度的情况下压缩数据,下面是初步压缩后的信息。可以看到数据已经从原来的20G变成了5G以内。

2、第二步就是对我们抽取的数据进一步压缩,通过观察数据我们发现,一条船是可以有多个订单的,所以可能存在多个订单的状态全是一样的,这个相当于重复数据,同时存在一个订单在同一时间有多个一模一样重复的数据,所以我们可以通过vesselMMSI和timestamp 这两个字段去重,只保留一条船的运行数据,当然去重前要对订单和时间排序,这样才能保证保留一个船上同一个订单的完整记录。
去重之后我们的数据瞬间减少到了1G以内,这个对于普通的笔记本电脑内存都是可以足够操作的。
三、观察数据
接下来我们对数据观察一下,看看有什么规律。
Label问题
1、首先题目是要我们预测到港时间,那么怎样才算到港呢,这里我们截取了一个订单的最后几条记录,发现船的经纬度已经不在发生什么改变,speed也是0的状态,但是该订单仍然在记录,并且方向在不断改变,从这里结合实际情况我们能猜想到,该运单船只应该是遇到了塞港,导致需要不断变换方向,缓慢移动到目的地。但是根据官方的说明,其实这已经算是到港了。我们观察到这前后的时间差长达4个小时之久,那么如果我们取记录的最后一条log作为到港时间,就显的不太合理,这会与官方给的时间上有比较大的误差。所以在制作label的方面,我们可以考虑通过行船的状态比度speed为0,或者经纬度不在剧烈改变,或者距离目标港口一定距离等一系列方式,判断实际的到港。

轨迹问题
2、test中的trace 在trian里面并不是全都有,但是目的港口相同的或者相识的轨迹是存在的,所以我们从训练集中提取轨迹相似的数据进行训练就可以达到比较好的效果,保证训练集和测试集的一致性。
我们先对trace相同的trian中的数据做一个label的平均,看看不同trace和相似trace的分布差异性。

从上图我们可以看到,相似trace即目的地和始发地相识或者相近的trace,他们的平均用时是差不多的,所以我们在筛选数据的时候,可以把相近的数据也拿出来,扩大训练样本。当然也可以对这些相似的trace或者用时相近的trace做一个分箱,将相近的数据作为同一类别特征,输入到模型当中,相当于衡量了相似度。
对于相似度计算,其实有很多方法,比如直接把路由信息做KNN聚类,KD树分类,或者对GPS进行geohash编码,采用文本分类的方法,比如w2v、TFIDF等训练词向量,计算距离,等等。(当然如果时间多,并且追求准确性,也可以采用人工智能的方法把轨迹图全部画出来,人工分类)
坐标问题
3、对于测试集中的数据,我们观察到Onboard的时间都是第一条记录的时间,但是第一条记录的坐标却和出发港的坐标相差很大,我们猜测test里面的起始数据也有可能被截断了,导致记录并不是真正的初始记录,而是已经行船了一定时间的记录,但是Onboard的时间确实是截断的最早时间。这样说可能有点绕,我们从下图看就一目了然。
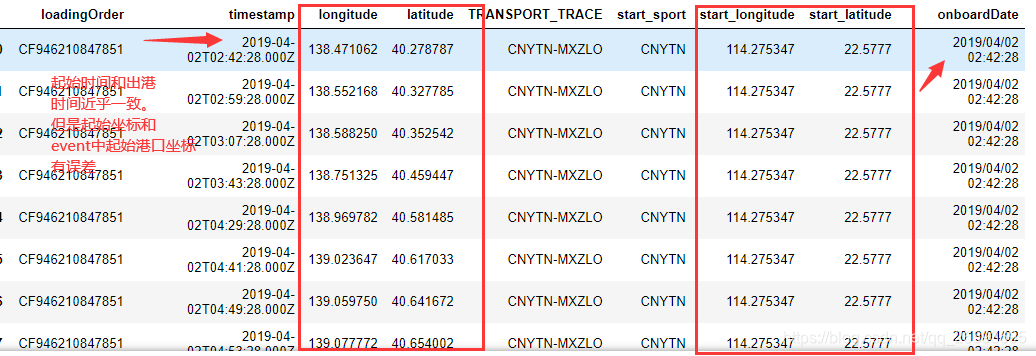
关于港口坐标信息,我们可以从event里面的sport文件中得到,当然里面存在大量无用或者错误的Gps信息,通过官方的说明我们可以删除那些无用的数据,然后merger到我们的训练集中。一般test里面的港口信息在event里面都是有的,所以我们不需要做太多处理。另外我们也可以根据百度地图来分析验证各个港口的坐标以及船只的实际航行位置。这里放上百度地图的坐标查询工具:坐标拾取系统
训练集
4、关于训练集的构建,周周星也都分享过了,这里就不过多说明了,但是还是想说一点,test里面的数据和train中的数据并不是一样的,通过筛选,我们基本上是可以从train里面得到完整路由的数据的,但是test里面是得不到的,保持训练和测试集的一致性就需要我们在构造特征的时候也要把tran进行截断来构造。但是截断的方式有很多,随机截断也不一定是最好的,因为test的数据还存在一定的稀疏性,所以这得充分考虑进行,观察测试数据,构造一个合理的训练集。
四、总结与展望
那这次的分析分享大概就到这里,由于目前排名并不是很靠前,所以太多技巧性的东西也不是很有把握,希望大家在看完本篇后能有所启发,也预祝大家能取得好成绩!后期复赛的话自己也有很多想法,比如从NLP的角度,这个题目有点类似于文本分类、文本相似度、以及句子翻译等任务。比如输入一段gps等特征序列,得到一串的估计时间等等。当然也可以传统的NN+LGB来做,这些都还只是猜想,思考问题从不同的角度出发,有时候往往能有意想不到的收获。不过目前最重要的还是先狗进复赛再说。后续如果还有时间和机会做这个比赛的话,也会和大家持续分享自己的思路!希望大家多多支持! 共同学习进步!!