Dissecting Catastrophic Forgetting in Continual Learning by Deep Visualization
解释深度神经网络的行为(通常被认为是黑匣子)是至关重要的,尤其是当它们已被人类生活的各个方面广泛采用时。结合可解释人工智能的发展,本文提出了一种名为Auto DeepVis的新技术,用于剖析持续学习中的灾难性收获。在研究Auto DeepVis的困境时,还引入了一种用于处理灾难性遗忘的新方法,称为“严重冻结”。在字幕模型上进行的实验细致地展示了如何发生类别错误的遗忘,特别是说明了哪些成分正在遗忘或发生变化。然后评估我们技术的有效性;更确切地说,关键冻结要求在基线之前和之后的任务中均具有最佳性能,从而证明了调查的能力。我们的技术不仅可以补充现有解决方案,以彻底消除终身学习的灾难性遗忘,而且可以解释。
1. Introduction
关于人类进化,终身学习被认为是最关键的能力之一,有助于我们在整个一生中开发更复杂的技能。因此,这种学习策略的思想已在深度学习社区中广泛部署。终身学习(或持续学习)使机器学习模型能够感知新知识,同时公开向后转移,不遗忘或鲜为人知的学习(Ling&Bohn,2019)。尽管上述属性是终身学习系统的最终目标,但灾难性的遗忘或语义漂移自然会在深度神经网络(DNN)中发生,因为它们大多是根据梯度下降算法进行更新的(Goodfellow et al。,2013)。
已经成功进行了许多尝试来解决生成模型中的遗忘问题(Zhai等人,2019),对象检测(Shmelkov等人,2017),语义分割(Tasar等人,2019)或字幕(Nguyen)等,2019b)。然而,算法往往依赖于外部因素(例如,输入数据,网络结构),而忽略了为什么在内部发生类别营养遗忘。如果我们对遗忘过程有所了解并了解此问题如何影响模型,那将是学习无遗忘的第一步。
当代的可解释性方法为我们提供了了解深层神经网络决策过程的优势,从可视化的显着性图(Si-monyan等人,2013; Dabkowski&Gal,2017)到将模型转变为对人类友好的模型结构(Che et al,2016)。解释网络中神经元或层的激活有助于我们对每个块,层甚至一个节点的特定角色进行分类。已证明,较早的层提取了诸如边缘或颜色的基本特征。而更深的层负责检测独特的特征。预测差异分析(PDA)(Zintgraf et al。,2017)甚至更具体地突出显示了支持或抵消特定类别的像素,指示哪些特征对预测是正面还是负面的。
尽管灾难性的遗忘是困难且不希望的,但在AI社区中很少有人进行了解此问题的研究。对理解或衡量灾难性遗忘的兴趣与应对该问题的研究数量无关。(Kemker等人,2018)开发了新的指标,以帮助公平,直接地比较持续学习技术。 (Nguyen et al。,2019a)研究了哪些属性导致学习过程的难度。通过使用任务空间对所选属性进行建模,他们可以估计模型在顺序学习场景中遗忘了多少,从而阐明影响任务序列错误率的因素。但是,它们无法解释模型中遗忘了什么或遗忘了哪些组件,而是显示了任务的哪些属性触发了灾难性遗忘。相比之下,我们的工作重点是研究网络的哪些组件最有可能根据给定的任务序列进行更改。
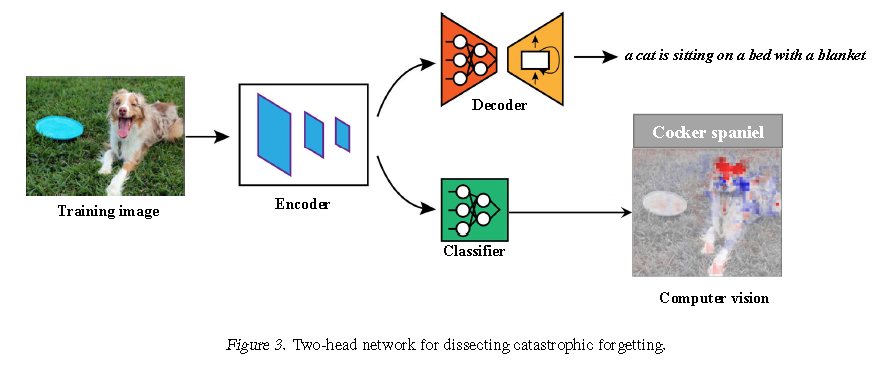
这项研究引入了一种新颖的方法,通过可视化增量学习(被认为是持续学习中最难的学习场景)中的隐藏层,来分解类属遗忘。在这种学习范例中,禁止使用以前的数据进行排练策略,并且到目前为止还看不到传入任务的样本。我们提出了一个名为Auto DeepVis的工具,该工具利用了来自(Zintgraf et al,2017)的预测差异分析。该工具可自动进行灾难性遗忘的剖析,准确指出模型中哪些组件导致遗忘。通过使用联合交叉口(IoU),可以在添加每个类之后测量遗忘的程度,从而使我们直观地了解在网络的给定部分上遗忘是如何发生的。
(Kemker等人,2018)的工作进行了关于解决灾难性遗忘的最新持续学习技术的实验。结果表明,尽管算法有效,但只能在弱约束和不公平的基线上进行,因此遗忘问题尚未得到完全解决。他们坚持认为在持续学习中使用MNIST(Kirkpatrick等,2017)或CIFAR(Zenke等,2017)等玩具数据集是不可行的。因此,我们选择Split MS-COCO(Nguyen et al。2019b)来测量深度神经网络上的遗忘。从解剖的结果来看,我们只是冻结网络中大多数可塑性组件以保护累积的信息。除了在卷积神经网络(CNN)上进行可视化之外,我们还简要研究了由循环神经网络(RNN)组成的解码器如何在持续学习中发生变化。
我们将这项工作的贡献总结如下:首先,我们提出了一种新颖的开拓性方法来分析持续学习中的灾难性遗忘。自动DeepVis在学习任务序列时会自动指出网络中的遗忘组件。其次,我们基于发现结果介绍了一种减轻灾难性遗忘的新方法。我们的技术可以在消除灾难性遗忘的步骤中发挥补充作用。
2. Related Work
特征可视化 要了解模型如何获取以前学习的功能,我们需要可视化模型如何处理输入图像。为此,执行模型的逐层可视化。迄今为止,我们已经获得了旧模型(或原始模型),表示过去任务的知识。另一方面,新模型(或当前模型)是面对新传入任务的网络,应避免灾难性的遗忘。
有几种尝试通过各种方式可视化卷积神经网络的作品。(Zeiler&Fer-gus,2014)利用多层反卷积网络(deconvnet),通过开关来记录原始输入图像的局部最大值。 Deconvnet允许我们识别网络的特定部分需要哪些功能,或者图像的哪些特性最能激发选定的神经元。 (Yosinski et al。,2015)并未生成输入图像进行诊断,而是尝试生成合成图像,该图像通过梯度下降算法最大程度地激活给定神经元。
(Simonyan et al,2013)另一种被广泛使用的方法称为显着性图,提出了一种基于梯度的技术来衡量由于像素的微小变化而敏感地改变了分类分数。这项工作显示了反卷积层的通用版本。 (Robnik-ˇSikonja&Kononenko,2008)提出了一种类似的方法,该方法完全删除了输入像素,而不是计算这些像素的梯度。 (Zintgraf et al。,2017)提出了上述工作的一种称为PDA的变体。他们利用条件采样来清除连接像素的斑块,而不是一次删除一个像素,从而最终显示出更好的可视化结果。但是,此工具只能生成计算机视觉,从而为用户留下结论。当我们在卷积块中有数百个甚至数千个特征图时,这种手动过程无法确保观测的质量。在这项工作中,采用PDA来构建用于可视化灾难性遗忘的自动工具。
灾难性的遗忘 (McCloskey&Cohen,1989)在连接主义网络中首次引入了灾难性的遗忘。最近,(Toneva et al。,2018)重新构造了遗忘的定义,就像在学习过程中样本模型的预测从正确转变为错误一样。深入研究模型,我们可以认为神经元的值已经发生了巨大变化,从而可能导致相同输入图像的答案有所不同。
弹性重量合并-EWC(Kirkpatrick et al。,2017)使用Fisher信息矩阵来帮助模拟人脑的突触合并机制。保护执行旧任务的重要参数,同时更新其他重要参数以最大程度地减少新数据集上的损失。相比之下,神经网络中每个突触(或权重)的重要性在本地计算(Zenke et al,2017)。当出现干扰分布时,突触状态会通过在线估计来保持并估计突触的重要性,从而防止关键突触发生变化。学习不遗忘-LwF(Li&Hoiem,2017)在传入数据上生成伪标签,以帮助捕获先前的分布。在训练中,知识蒸馏(Hinton等人,2015)将伪标签变成软目标,并应用预热步骤。 (Lee et al。,2017)基于贝叶斯神经网络,在两个任务上都匹配后代时刻,以将新网络引导到常见的低误差区域。在(Hou et al。,2018)中进行了从旧模型和专家特征提取器的知识蒸馏,并辅以对旧数据的琐碎回顾。 Rusu et al。,2016)通过专门的子网动态扩展网络,以吸收新知识,同时冻结旧模块。
灾难性的遗忘通常可以通过规范化,数据重放或更改网络体系结构来解决。在这项研究中,我们表明,仅通过冻结网络的易碎块,我们就可以显着提高泛化性能。