32位下的内存地址分布图如下:1g为内核空间,3g为用户空间
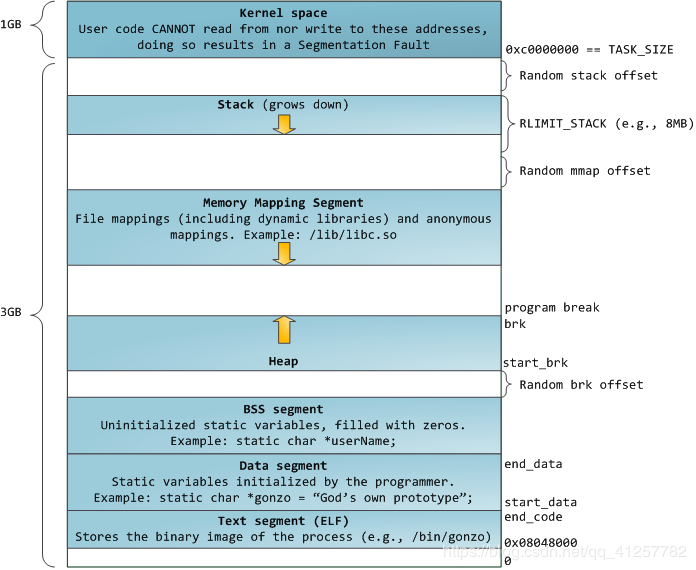
内核空间:内核空间表示运行在处理器最高级别的超级用户模式(supervisor mode)下的代码或数据,内核空间占用从0xC0000000到0xFFFFFFFF的1GB线性地址空间,内核线性地址空间由所有进程共享,但只有运行在内核态的进程才能访问,用户进程可以通过系统调用切换到内核态访问内核空间,进程运行在内核态时所产生的地址都属于内核空间。
用户空间:
用户空间占用从0x00000000到0xBFFFFFFF共3GB的线性地址空间,每个进程都有一个独立的3GB用户空间,所以用户空间由每个进程独有,但是内核线程没有用户空间,因为它不产生用户空间地址。另外子进程共享(继承)父进程的用户空间只是使用与父进程相同的用户线性地址到物理内存地址的映射关系,而不是共享父进程用户空间。运行在用户态和内核态的进程都可以访问用户空间。
在用户空间内内存被分为:0x08048000开始
text段-代码段
text段存放程序代码,运行前就已经确定(编译时确定),通常为只读
.rodata-只读数据段
存放一些只可以读的常量数据 比如:被const修饰的全局变量,被define宏定义的常量,和只可读的字符串常量。
.data
存放在编译阶段(而非运行时)就能确定的数据,可读可写。也就是通常所说的静态存储区,赋了初值的全局变量和赋初值的静态变量存放在这个区域,常量也存放在这个区域,static 声明的变量,不管它是全局变量也好,还是在函数之中的也好,只要是没有赋初值都存放在.bss段,如果赋了初值,则把它放在.data段。
.bss
定义而没有赋初值的全局变量和静态变量,放在这个区域;
heap
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。
当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);
当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。由低向高。
共享库区域
这里被内核用来把文件内容直接映射到内存。所有的应用程序都可以使用linux提供的mmap()系统调用或者在windows中使用CreateFileMapping()/MapViewOfFile来进行这样的映射。memory mapping是进行文件I/O的高效方法,所以动态库的加载使用这个方式来实现。当然,也可以进行一些不关联到文件的程序数据的匿名memory mapping。在linux中,如果你通过malloc()来申请一块大的内存,C库就会在memory mapping segment中创建一个匿名memory mapping而不是使用堆空间。这里的“大”意味着大于MMAP_THRESHOLD字节,默认是128kb,可以通过mallopt()来进行调整。
stack
stack段存储参数变量和局部变量,由系统进行申请和释放,属于静态内存分配。由高向低