本博文源于mysql,旨在对高级查询做相应学习与练习。内容包含多表查询/外连接查询/自连接查询/子查询/分组查询/使用正则表达式的查询。
在学习之前,必须先有两张表
create table tb_departments (dept_id int(11) primary key,dept_name varchar
(11),dept_call int(11),dept_type varchar(2));
insert into tb_departments values(1,'Computer',11111,'A');
insert into tb_departments values(2,'Math',22222,'A');
insert into tb_departments values(3,'Chinese',33333,'B');
insert into tb_departments values(4,'Economy',44444,'B');
insert into tb_departments values(5,'History',55555,'B');
上面是第一张表,第二张表
create table tb_students_info
(id INT(11) PRIMARY KEY,
name VARCHAR(10),dept_id INT(11),
age INT(11),sex VARCHAR(4),height FLOAT,login_date DATE);
然后插入记录
insert into tb_students_info values(1,'Dany',1,25,'F',160,'2015-09-10');
insert into tb_students_info values(2,'Green',3,23,'F',158,'2016-10-22');
insert into tb_students_info values(3,'Henry',2,23,'M',159,'2016-10-23');
insert into tb_students_info values(4,'Jane',1,22,'F',156,'2016-10-12');
insert into tb_students_info values(5,'Jim',1,24,'M',158,'2016-10-22');
insert into tb_students_info values(6,'John',2,21,'M',152,'2016-10-24');
insert into tb_students_info values(7,'Lily',6,22,'F',160,'2016-10-25');
insert into tb_students_info values(8,'Susan',4,23,'F',166,'2016-10-26');
insert into tb_students_info values(9,'Green',3,22,'M',170,'2016-10-27');
insert into tb_students_info values(10,'Green',4,23,'M',193,'2016-10-23');
有了它们,我们继续做练习
多表查询
连接查询是关系数据库重要的查询,主要包括内连接,外连接等。通过连接运算符可以实现多个表的查询。
内连接查询
内连接是通过在查询中设置连接条件的方式,来移除查询结果中某些数据行后的交叉连接。简单来说,就是利用条件表达式来消除交叉连接的某些数据行,在FROM子句中使用关键子INNER JOIN连接两张表,并使用ON子句来设置连接条件。如果没有任何条件,INNER JOIN和CROSS JOIN在语法上是等同的,两者可以互换。
格式
SELECT <列名1,列名2....>
FROM <表名1> INNER JOIN <表名2> [ON 子句]
例子:将两张表中有dept_id做内连接查询
select id,name,age,dept_name from tb_students_info,
tb_departments where tb_students_info.dept_id = tb_departments.dept_id;

例子:将两张表做innser join连接进行查询
select id,name,age,dept_name from tb_students_info
inner join tb_departments on tb_students_info.dept_id = tb_departments.dept_id;

在这里的查询语句中,两个表之间的关系通过INNERJOIN指定,连接的条件用ON而非用where
外连接查询
外连接更为麻烦,需要将连接的表分为基表和参考表,再以基表为依据返回满足和不满足条件的记录。外连接更加注重顺序,分为左外连接与右外连接。
左外连接又称为左连接,在FROM子句中使用关键字LEFT OUTER JOIN或者LEFT JOIN用于接受该关键字左表(基表)的所有行,并用这些行与该关键字右表中的行进行匹配,即匹配左表中的每一行及右表中符合条件的行。在左外连接的结果集中,除了匹配的行之外,还包括左表中有但在右表中不匹配的行,对于这样的行,从右表中选择的列的值被设置为NULL。
例子:在tb_students_info表和tb_departments表中查询所有学生,包括没有学院的学生
select name,dept_name from tb_students_info s
left outer join tb_departments d on s.dept_id = d.dept_id;

大家看到我们为表去别名,少用as,这是一种写法,还有Lily是NULL,希望大家认真仔细查看,因为Lily的dept_id是6,不在系id里,所以返回NULL
例子:在tb_students_info表和tb_departments表中查询所有学院,包括没有学生的学院
这个用右外连接做,比较好
select name,dept_name from tb_students_info s
right outer join tb_departments d on s.dept_id = d.dept_id;

这个方法真好使,直接将left换为right就行了,不用那么复杂改动其他语句。大家可以从这里体会编程的优化本质是对人进行极大的解放。偷懒和懒惰是人的本质。
自连接查询
自连接是将一个表和它自身进行连接,也是内连接的一种,同样使用INNER JOIN或者JOIN关键字进行连接。
如果需要在一个表中查找相同列值的行。就可以考虑用自连接。注意,在使用自连接的时候,需要为表指定两个不同的别名,且对所有查询的引用必须使用表别名的弦定,否则SELECT操作会失败。
例子:查询id为1的学生所在学院的其他学生的信息
select s1.id,s1.name from tb_students_info s1,tb_students_info s2
where s1.dept_id = s2.dept_id and s2.id = 1;

子查询
使用子查询的时机
子查询指一个查询语句嵌套在另一个查询语句内部的查询。在SELECT子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。
子查询中常用的操作符有ANY(SOME)、ALL、IN和EXISTS。子查询可以添加到SELECT、UPDATE和DELETE语句中,而且可以进行多层嵌套。子查询也可以使用比较运算符,如“<”,"<=",">",">=","!="等。
子查询中常用的运算符
- IN子查询:用于判断一个给定值是否存在于子查询的结果集中。
<表达式> [NOT] IN <子查询>
- 比较运算符子查询::主要用于对表达式的值和子查询返回值进行比较运算
<表达式> { = | < | > | >= | <= | <=> | < > | !=}
{ALL | SOME | ANY} <子查询>
- EXIST子查询:用于判断子查询的结果集是否为空
EXIST <子查询>
子查询的应用
例子:在tb_departments表中查询dept_type为A的学院ID,并根据学院ID查询该学院学生的名字
select name from tb_students_info
where dept_id in (select dept_id from tb_departments where dept_type='A');

例子:在th_departments表中查询dept_name等于"Computer"的学院id,然后在tb_students_info表中查询所有学院的学生的姓名
select name from tb_students_info where
dept_id = (select dept_id from tb_departments where dept_name='Computer');

例子:在th_departments表中查询dept_name不等于"Computer"的学院id,然后在tb_students_info表中查询所有学院的学生的姓名
select name from tb_students_info
where dept_id <> (select dept_id from tb_departments where dept_name='Computer');

例子:查询tb_departments表中是否存在dept_id=1的信息,如果存在,就查询tb_students_info表中的记录
select * from tb_students_info where
exists (select dept_name from tb_departments where dept_id =1);

分组查询
分组查询的格式
GROUP BY {<列名> | <表达式> | <位置>} [ASC | DESC]
下面会介绍例子加深影响
聚合函数在分组查询中的应用
group by通常跟聚合函数一起,聚合函数例如:MAX()/MIN()/COUNT()/SUM()/AVG()
例子:根据dept_id对tb_students_info表中的数据进行分组统计
select dept_id ,count(dept_id) as cnt from tb_students_info group by dept_id;

大家可以从这里总结出规律,group by要分类的字段,select必须要有!不妨再看下面一个例子
例子:根据dept_id对tb_students_info表中的数据进行分组,将每个学院的学生姓名显示出来
select dept_id ,group_concat(name) as names from tb_students_info group by dept_id;

使用having关键字设置条件
这个关键字大家一定要记住跟group by搭配的,可以这样理解:有group by可以没有having,但是having一定要有group by
HAVING <条件>
例子:根据dept_id对tb_students_info表中的数据进行分组,并显示学生人数大于1的分组
留心的会发现,这个例子其实是上个例子加个having分组条件。
select dept_id,group_concat(name) as names
from tb_students_info group by dept_id having count(name)>1;

使用正则表达式的查询
到处都能遇到正则,大家学过高级语言一定深有体会。web用正则匹配url,linux里也用正则做脚本。大家如果对正则理论的模型实现感兴趣,可以看这篇博文,博主用简单的方式讲解一个正则实现原理
正则表达式原理底层–有限状态机
^:匹配文本的开始字符
例子:'^b' 匹配以字母b开头的字符串
$:匹配文本的结束字符
例子:'st$' 匹配以st结尾的字符串
.:匹配任何单个字符
例子:'b.t'匹配任何b和t之间有一个字符
*:匹配零个或多个在它前面的字符
例子:'f*n':匹配字符n前面有任意个字符f
+:匹配前面的字符1词或多次
例子:'ba+'匹配以b开头的,后面至少紧跟一个a
<字符串>:匹配包含指定字符的文本
例子:'fa'匹配'fa'的字符串
[字符集合]:匹配字符集合中的任何一个字符
例子:'[xz]'匹配x或者z
[^]:匹配不在括号中的任何字符
例子:'[^abc]'匹配任何不包含a,b或c的字符串
字符串{n,}匹配前面的字符串至少n次
例子:b{2}匹配2个或更多的b
- 字符串
{n,m}匹配前面的字符串至少n次,至多m次。如果n为0,此参数为可选参数
例子:b{2,4}匹配最少2个,最多4个b
查询以特定字符或字符串开头的记录
^:匹配文本的开始字符
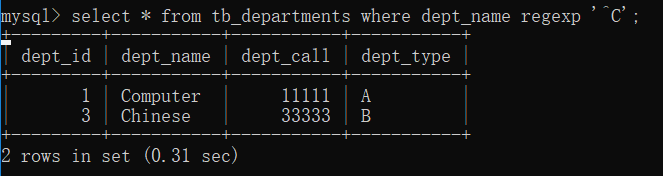
例子:在tb_departments表中,查询dept_name字段以字母“C”开头的记录
select * from tb_departments where dept_name regexp '^C';
查询以特定字符或字符串结尾的记录
$:匹配文本的结束字符
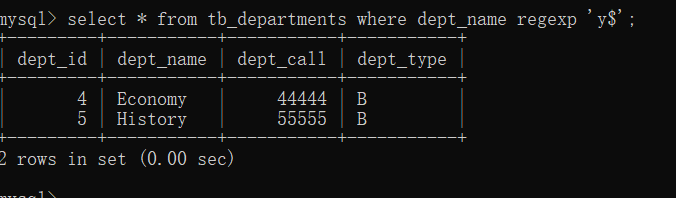
例子:在tb_departments表中,查询dept_name字段以字母“y”结尾的记录
select * from tb_departments where dept_name regexp 'y$';
用符号“.”代替字符串中的任意一个字符
在这里插入代码片
例子:在tb_departments表中,查询dept_name字段值包含字母"o"与字母“y”,且两个字母之间只有1个字母的记录
select * from tb_departments where dept_name regexp 'o.y';

使用“*”和“+”来匹配多个字符
-
*:匹配零个或多个在它前面的字符 -
+:匹配前面的字符1词或多次
例子:在tb_departments表中,查询dept_name字段值包含字母"C",且“C”后面出现字母"h"的记录
如何大家用*做匹配,会包含0这种情况也就被认为h可出现可不出现,这时候必须要用+
两种代码大家都来跑一遍吧
select * from tb_departments where dept_name regexp '^Ch*';
select * from tb_departments where dept_name regexp '^Ch+';
打完体会正则的强大与标准。

匹配指定字符串
<字符串>:匹配包含指定字符的文本
例子:在tb_departments表中,查询dept_name字段值包含字符串"in"的记录
select * from tb_departments where dept_name regexp 'in';

匹配指定字符串中的任意一个
[字符集合]:匹配字符集合中的任何一个字符
例子:在tb_departments表中,查询dept_name字段值包含字母"o"或者‘e’的记录
select * from tb_departments where dept_name regexp '[io]';

匹配指定字符以外的字符
[^]:匹配不在括号中的任何字符
例子:在tb_departments表中,查询dept_name字段值包含字母a-t以外的字符记录
select * from tb_departments where dept_name regexp '[^a-t]';
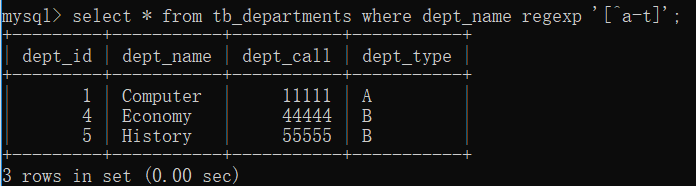
大家会发现Chinese和Math被排除了。