本文是对Sofa数据竞赛上的练习项目:问答网站问题及回答数量预测进行结果展示。主要是根据日期这一唯一的特征,预测某问答网站每天新增的问题数和回答数。最终排名3/155。
1.背景介绍
给出美国某大型问答社区从2010年10月1日到2016年11月30日,每天新增的问题的个数和回答的个数。任务是预测2016年12月1日到2017年5月1日,该问答网站每天新增的问题数和回答数。在本练习赛中,日期是唯一的特征。
2.导入包和数据
2.1导入必要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
%matplotlib inline
sns.set(style="ticks")
pd.set_option("display.max_columns",None)#展示所有列数据
pd.set_option("display.max_rows",None)#展示所有行数据
# 忽视警告
import warnings
warnings.filterwarnings('ignore')
# 提取节假日,周末等信息
from datetime import date
from workalendar.usa import UnitedStates
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor
2.2导入数据并查看
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
submit = pd.read_csv("sample_submit.csv")
train.head()

# 查看数据量
train.shape,test.shape
((2253, 4), (152, 2))
3.探索性数据分析及数据预处理
3.1时间特征预处理
由于分析的是日期特征,因此需要将数据的类型转为datetime格式。定义如下函数,提取日期中的年月日,周末等信息。处理后的数据如下。
def get_date(data):
data['date'] = pd.to_datetime(data['date'],format='%Y-%m-%d')
data['d_w']=data['date'].dt.dayofweek
data['d_d'] = data['date'].dt.day
data['d_m'] = data['date'].dt.month
data['d_y'] = data['date'].dt.year
return data
train=get_date(train)
test=get_date(test)
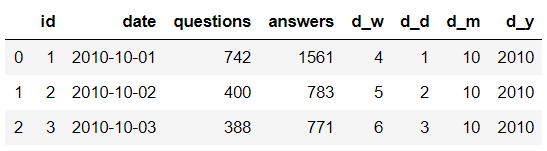
train[:3]
3.2三个变化趋势
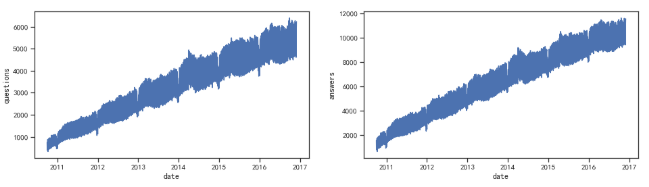
3.2.1宏观趋势
可以看到,随着日期的增加,从宏观趋势上,问答数也在逐渐增加,且呈线性趋势,不过上下浮动较大。
fig=plt.figure(figsize=(16,4))
ax1=plt.subplot(1,2,1)
sns.lineplot(x='date',y='questions',data=train)
ax2=plt.subplot(1,2,2)
sns.lineplot(x='date',y='answers',data=train)
plt.show()
3.2.1特殊时间点趋势
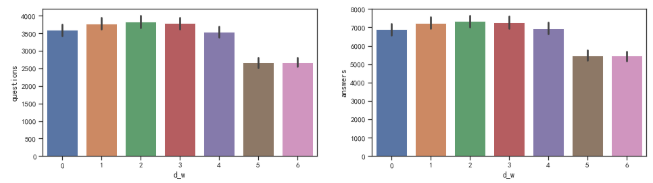
3.2.1.1周末因素
主要探究时间特征中对问答数量有影响的因素。可以看到周5和周6的问答数量有明显的下降。
分析是因为周5周6正要处于休息时期,所以网上的活动较少,导致问答数量下降。
fig=plt.figure(figsize=(16,4))
ax1=plt.subplot(1,2,1)
sns.barplot(x='d_w',y='questions',data=train)
ax2=plt.subplot(1,2,2)
sns.barplot(x='d_w',y='answers',data=train)
plt.show()
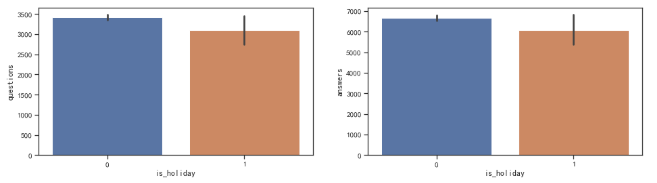
3.2.1.2节假日因素
这里应用python中的workalendar模块,可以查到每一年的各国节日的日期。
cal = UnitedStates()
cal.holidays(2010)

对日期特征进行判断,是节假日的为1,不是的则为0。绘图查看节假日中问答数量。可以看到节假日的问答数量有明显的下降。
分析是因为节假日正处于休息时期,理由同上。由此分析可考虑一个新的特征,即日期距离其最近两个节假日的天数。
fig=plt.figure(figsize=(16,4))
ax1=plt.subplot(1,2,1)
sns.barplot(x='is_holiday',y='questions',data=train)
ax2=plt.subplot(1,2,2)
sns.barplot(x='is_holiday',y='answers',data=train)
plt.show()
3.2.2年月日趋势
通过上述分析,可知每年问答数都会增加。因此先探究月份对问答数量的影响。可以看到各月份对问答数量的影响参差不齐。
fig=plt.figure(figsize=(16,4))
ax1=plt.subplot(1,2,1)
sns.barplot(x='d_m',y='questions',data=train)
ax2=plt.subplot(1,2,2)
sns.barplot(x='d_m',y='answers',data=train)
plt.show()
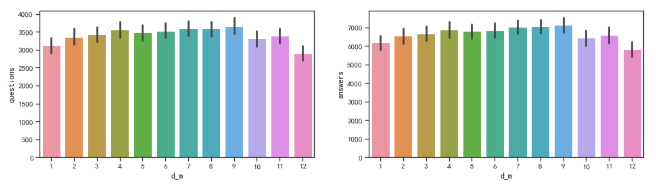
这里也根据季度因素,对月份进行拆分。
def get_season(month):
if month >=1 and month <=3:
return 1
elif month >=4 and month <=6:
return 2
elif month >=7 and month <=9:
return 3
else:
return 4
train['season'] = train['d_m'].apply(lambda x: get_season(x))
test['season'] = test['d_m'].apply(lambda x: get_season(x))
对于日趋势,这里利用pandas中的diff()函数,求得上下日期的间距。这里碰巧跟id是重复的,因此,将id视为日期间距。
处理后的特征如下:
train.columns
Index(['id', 'date', 'questions', 'answers', 'd_w', 'd_d', 'd_m', 'd_y',
'sqrt_id', 'not_wd', 'is_holiday', 'last_day', 'first_day', 'season'],
dtype='object')
3.3日期特征的拆分总结
- 提取年月日,对日期数据进行基础提取;
- 提取节假日及周末特征,判断是否为特殊日期;
- 计算时间差,即距离特定日期的天数,如节假日,周末等。
4.建模预测
这里参考网站给的标杆模型,先用id个sqrt_id,进行LightGM的预测。
# 根据特征['id', 'sqrt_id'],构造模型预测questions
reg = LGBMRegressor()
reg.fit(train[cols_lr], q)
q_fit = reg.predict(train[cols_lr])
q_pred = reg.predict(test[cols_lr])
# 根据特征['id', 'sqrt_id'],构造模型预测answers
reg =LGBMRegressor()
reg.fit(train[cols_lr], a)
a_fit = reg.predict(train[cols_lr])
a_pred = reg.predict(test[cols_lr])
将预测值和真实值的差异作为新的目标特征,利用XGBoost模型,对其进行拟合,得出最终结果。
# 得到questions和answers的训练误差
q_diff = q - q_fit
a_diff = a - a_fit
************************************
reg = XGBRegressor()
reg.fit(train, q_diff)
q_pred_xgbr = reg.predict(test)
reg = XGBRegressor()
reg.fit(train, a_diff)
a_pred_xgbr = reg.predict(test)
************************************
submit['questions'] = q_pred + q_pred_xgbr
submit['answers'] = a_pred + a_pred_xgbr
submit.to_csv('my_Lr_Knn_prediction_nlx.csv', index=False)
模型评估函数如下:
def MAPE(true, pred):
diff = np.abs(np.array(true) - np.array(pred))
return np.mean(diff / true)
5.思路参考
http://sofasofa.io/others.php?f=1000064