文章目录
零、读前说明
- 本文中没有涉及到很多的相关理论知识,也没有做深入的了解,所以,您如果是想要系统的学习、想要多学习关于理论的知识等,那么本文可能并不合适您。
- 本文中所有设计的代码均通过测试,并且在功能性方面均实现应有的功能。
- 设计的代码并非全部公开,部分无关紧要代码并没有贴出来。
- 如果你也对此感兴趣、也想测试源码的话,可以私聊我,非常欢迎一起探讨学习。
- 由于时间、水平、精力有限,文中难免会出现不准确、甚至错误的地方,也很欢迎大佬看见的话批评指正。
- 嘻嘻。。。。 。。。。。。。。收!
一、概述
线性表的链式存储结构,由于它不要求逻辑上相邻的元素在物理位置上也相邻,因此它没有顺序存储结构所具有的弱点,但同时也失去了顺序表可随机存取的优点。
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的)。因此,为了表示每个数据元素ai与其直接后继数据元素ai+i之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。这两部分信息组成数据元素ai的存储映像,称为节点(node)。它包括两个域,分别为:
- 其中存储数据元素信息的域称为数据域
- 存储直接后继存储位置的域称为指针域
在使用链表的时候,只是关心她所在的线性表中节点之间的逻辑关系,不关心每个节点在存储器中实际的位置。
二、线性表链式存储的进化
2.1、传统链表
根据概述的简单说明、不难理解,传统链表及状态可以表示为如下图所示。

缺点:当链表业务发生改变的时候,整个链表的业务逻辑也需要同步发生改变。
2.2、非传统链表
非传统链表辑状态可以表示为如下图所示。

链表的逻辑节点不包含任何业务节点相关的信息,而是让业务节点去包含链表的逻辑节点,也就是linux内核链表。而且在不改变业务节点的情况,可以任意的修改链表的逻辑节点,比如修改成循环链表、双向链表等。
缺点:在找到链表的逻辑节点之后,想要找到业务节点的首地址,必须通过一定的偏移量才能找到,而且,偏移量的计算也根据业务节点的复杂程度变得复杂。
2.3、通用链表
在非传统节点的基础上,设置一个固定的规则,即,将链表逻辑节点的位置放置在业务节点的第一个位置上,那么在存储中,链表逻辑节点的地址与业务节点的首地址是一致的,那在这种情况下,找到链表的逻辑节点,同时也找到了业务节点的首地址。这样就形成了一个通用链表的形式,所以,通用链表辑状态可以表示为如下图所示。
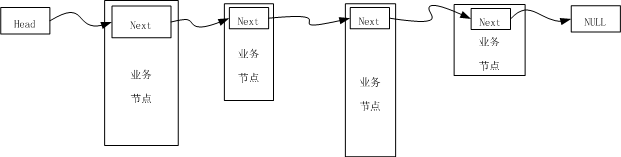
说明:头指针和头结点的异同(部分摘自《大话数据结构》)
头指针:
1、头指针是指链表指向第一个节点的指针,若链表有头结点,则是指向头节点的指针
2、头指针具有标识作用,所以常用头指针冠以链表的名字
3、无论链表是否为空,头指针均不为空,头指针是链表的必要元素。
头结点:
1、头结点是为了操作的统一和方便而设立的,放在第一个元素的节点之前,其数据域一般无意义(也可以存放链表的长度)
2、头结点不一定是链表的必要元素
3、有了头结点,对第一个元素节点钱插入节点和删除节点,其操作与其他节点的一致
4、头节点:数据段为空,地址段为NULL,可用于做循环结束的条件
三、线性表链式存储的代码实现 - 传统链表
3.1、链表的存储结构
对于传统链表,业务节点与链表的逻辑节点合而为一,所以,其存储结构在C语言中可以使用结构体来表示为:
#define int data_t
typedef struct node
{
data_t data; // 数据域
struct node *next; // 指针域
} Node;
3.2、操作函数定义
对于传统链表,本文设计的操作函数定义如下:
/**
* linklist.h 文件
**/
#ifndef __LINKLIST_H__
#define __LINKLIST_H__
#include "list.h"
#include <stdio.h>
#include <stdlib.h>
//数据类型
typedef int data_t;
//节点类型
typedef struct node
{
data_t data; //存储数据
struct node *next; //存储下一个节点的地址
} linknode_t;
//开辟空的链表
linknode_t *linklist_create();
//头插入
int linklist_insert_head(linknode_t *head, data_t value);
//尾插入
int linklist_insert_tail(linknode_t *head, data_t value);
//按位置插入
int linklist_insert_pos(linknode_t *head, int pos, data_t value);
//按顺序插入(递增)
int linklist_insert_sort(linknode_t *head, data_t value);
//头删除
int linklist_delete_head(linknode_t *head);
//尾删除
int linklist_delete_tail(linknode_t *head);
//通用删除
int linklist_delete_pos(linknode_t *head, int pos);
//判断为空返回1 非空返回0
int linklist_is_empty(linknode_t *head);
//获取
data_t linklist_get(linknode_t *head, int pos);
//修改
int linklist_change(linknode_t *head, data_t old, data_t new);
//数据翻转
int linklist_revers(linknode_t *head);
//遍历
int linklist_show(linknode_t *head);
#endif
3.3、链表的元素插入
3.3.1、头插入法
即表示的是在头节点之后第一个节点之前插入新的节点,在插入的过程中,根本不需要关心后续节点是什么情况。引入当前位置指针current,新插入节点为node,那么,在头插入法中,current即为head,插入示意图如下图所示。
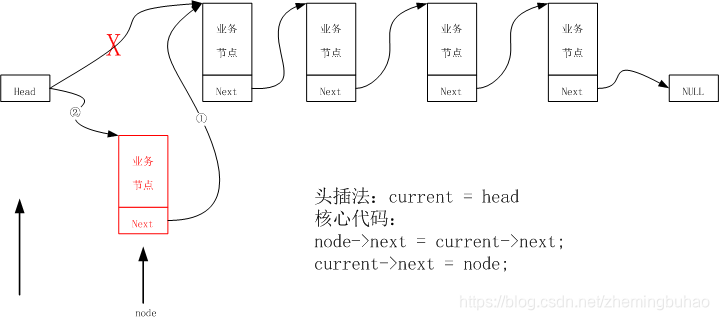 示例代码为:
示例代码为:
int linklist_insert_head(linknode_t *head, data_t value)
{
if (head == NULL)
return -1;
linknode_t *node = (linknode_t *)malloc(sizeof(linknode_t)); //开辟新节点的空间
node->data = value; //数据段存储数据
node->next = head->next; //新节点与第一个节点相连
head->next = node; //头节点与新节点相连
return 0;
}
3.3.2、尾插入法
对于尾插法,相对于头插入法而言,需要遍历整个链表,找到最末尾才能进行插入的操作,引入当前位置指针current,新插入节点为node,那么,在尾插入法中,current指针的判定条件为 head->next = NULL,插入示意图如下图所示。
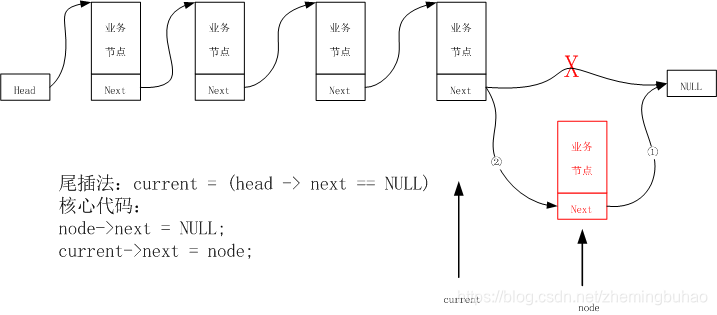
示例代码为:
int linklist_insert_tail(linknode_t *head, data_t value)
{
if (head == NULL)
return -1;
linknode_t *node = (linknode_t *)malloc(sizeof(linknode_t)); //开辟新节点的空间
node->data = value;
node->next = NULL;
linknode_t *current = head;
while (current->next != NULL)
{
current = current->next; //循环让指针向后移动
} //结束循环时head指向最后一个节点
current->next = node; //最后一个节点与新节点相连
return 0;
}
3.3.3、通用插入法
对于通用插法,与尾插入法类似,都需要进行遍历(部分)链表,如果插入位置pos为1,则实际为头插入法,如果pos大于链表的实际长度,那么可以修正pos改为尾插入,那么在pos有效取值范围之内,设定当前位置指针为current,新插入节点为node,那么,current指针即为插入位置pos之前的一个节点,所以,插入示意图如下图所示。
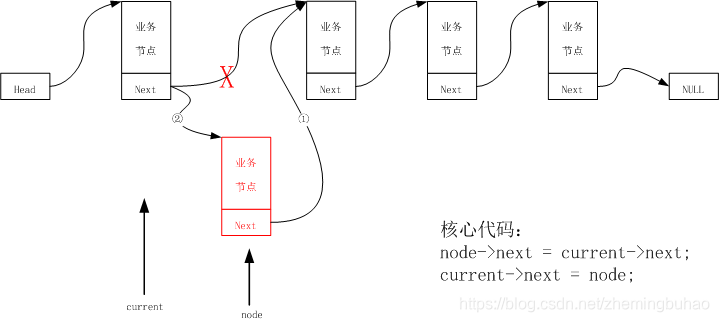
示例代码为:
int linklist_insert_pos(linknode_t *head, int pos, data_t value)
{
if (head == NULL || pos < 1)
{
puts("pos error");
return -1;
}
linknode_t *node = (linknode_t *)malloc(sizeof(linknode_t)); //开辟新节点的空间
node->data = value;
linknode_t *current = head;
int i;
for (i = 1; i < pos && current->next != NULL; i++) //如果pos过大直接插入到最后一个位置
{
current = current->next; //循环让指针向后移动
} //循环结束时,head指向前一个节点
node->next = current->next; //新节点与后一个节点相连
current->next = node; //前一个节点与新节点相连
return 0;
}
3.4、链表的元素删除
在此链表形式下,由于定义的结构形式,在删除节点之后,可以直接将节点指针进行释放并指向NULL。
3.4.1、头删除
要删除节点,首先缓存一下要删除的节点,然后将头节点直接连接第二个节点,即可完成删除操作,所以,头删除的示意图入下图所示。
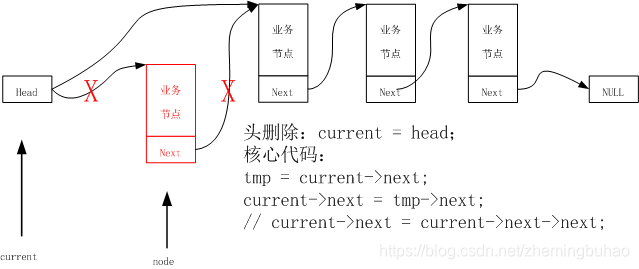
示例代码为:
int linklist_delete_head(linknode_t *head)
{
if (head == NULL)
return -1;
if (linklist_is_empty(head))
{
puts("empty");
return -1;
}
linknode_t *temp = head->next; //临记录要删除的节点(第一个节点)
head->next = temp->next; //head->next = head->next->next;
//头节点与第二个节点相连
free(temp); //释放temp所代表的第一个节点空间
temp = NULL; //防止野指针
return 0;
}
3.4.2、尾删除
要删除节点,首先缓存一下要删除的节点,然后将要删除的节点前一个节点的next域设置为NULL,即可完成删除操作。
要是用尾删除节点,最主要的是遍历链表查找尾节点,而尾节点的信息保存在尾节点前面的一个节点的next域,所以,对于引入的current节点,其判定与查找的条件应该是current->next->next == NULL,所以,头删除的示意图入下图所示。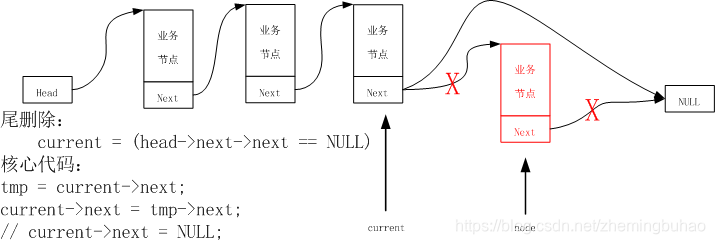
示例代码为:
int linklist_delete_tail(linknode_t *head)
{
if (head == NULL)
return -1;
if (linklist_is_empty(head))
{
puts("empty");
return -1;
}
linknode_t *current = head;
while (current->next->next != NULL)
{
current = current->next; //循环让指针向后移动
} //结束循环时head指向最后一个节点
linknode_t *temp = current->next; //临记录要删除的节点(最后一个节点)
current->next = temp->next; //head->next = head->next->next;
free(temp); //释放temp所代表的最后一个节点空间
temp = NULL; //防止野指针
return 0;
}
3.4.3、通用删除
要删除节点,首先缓存一下要删除的节点,然后遍历链表查找要删除的节点,而要删除的节点信息保存在前面的一个节点的next域,所以,对于引入的current节点,在pos为有效的值,其判定与查找的条件应该是循环计数变量 i 小于 要删除的节点的位置 pos,但是对于pos位置错误传入等情况,需要限定条件 current->next != NULL,,所以,头删除的示意图入下图所示。
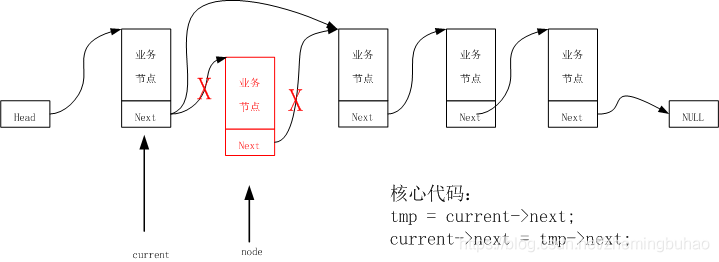
示例代码为:
int linklist_delete_pos(linknode_t *head, int pos)
{
int i = 1;
if (head == NULL)
return -1;
if (linklist_is_empty(head))
{
puts("empty");
return -1;
}
linknode_t *current = head;
while (i < pos && current->next != NULL) // i < pos && head->next != NULL
{
current = current->next; //循环让指针向后移动
i++;
} //结束循环时head指向最后一个节点
linknode_t *temp = current->next; //临记录要删除的节点(最后一个节点)
current->next = temp->next; //head->next = head->next->next;
free(temp); //释放temp所代表的最后一个节点空间
temp = NULL; //防止野指针
return 0;
}
3.5、链表的元素获取
因为在获取元素之前,并不清楚当前链表的长度,所以,要获取链表第pos个数据,则:
1、定义当前指针变量current,指向头结点,并且初始化计数变量i为1
2、开始循环查找第pos个数据元素,如果i<pos,就需要遍历链表,让current指针向后移动,并且让计数变量累加1
3、若在i<pos的情况下链表末尾currnet->next = NULL,则说明第pos个数据元素不存在,当然,原则上是不允许出现i>pos的情况。
4、否则查找成功,返回节点的的大数据。
示例代码为:
data_t linklist_get(linknode_t *head, int pos)
{
int i = 0;
if (head == NULL || pos < 0)
return -1;
linknode_t *current = head;
while (current->next != NULL && i < pos)
{
current = current->next;
i++;
}
return current->data;
}
3.6、整体工程代码结构
为了兼容unix和windows系统以及方便进行工程管理,特意使用Cmake工具进行编译等,目前测试工程的目录结构如下所示。
linklist
├── CMakeLists.txt
├── README.md
├── build
├── src
│ ├── linklist.c
│ └── linklist.h
└── test.c
2 directories, 5 files
3.7、调用测试用例
前面已经说明整体工程的结构,以及需要的文件,下面是测试底层功能函数的测试demo,详细代码如下。
/**
* test.c
**/
#include "./src/linklist.h"
int main(int argc, const char *argv[])
{
int i = 0;
linknode_t *h = linklist_create();
for (i = 0; i < 8; i++)
{
linklist_insert_head(h, 10 * (i + 1));
}
printf("头插入法:");
linklist_show(h);
linklist_insert_tail(h, 17);
printf("尾插入法:");
linklist_show(h);
linklist_delete_head(h);
printf("头删除法:");
linklist_show(h);
linklist_change(h, 50, 15);
printf("数据修改:");
linklist_show(h);
linklist_insert_pos(h, 15, 32);
printf("按位置插:");
linklist_show(h);
putchar(10);
linknode_t *w = linklist_create();
linklist_insert_sort(w, 17);
linklist_insert_sort(w, 32);
linklist_insert_sort(w, 61);
linklist_insert_sort(w, 19);
linklist_insert_sort(w, 10);
linklist_insert_sort(w, 12);
linklist_insert_sort(w, 10);
printf("按顺序插:");
linklist_show(w);
linklist_delete_head(w);
printf("按头删除:");
linklist_show(w);
linklist_delete_tail(w);
printf("按尾删除:");
linklist_show(w);
linklist_delete_pos(w, 3);
printf("按位删除:");
linklist_show(w);
linklist_revers(w);
printf("数据翻转:");
linklist_show(w);
printf("数去获取:%d\n", linklist_get(w, 3));
return 0;
}
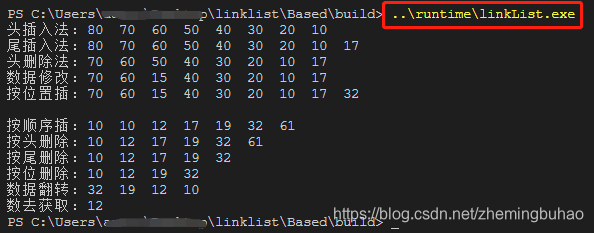
3.8、测试编译运行结果
本次测试是在windows环境下进行,其他系统等详细说明在README.md中查看。
1、使用Cmake编译,使用下面指令
cd build
cmake -G"MinGW Makefiles" .. # 注意 .. ,表示上级目录
make
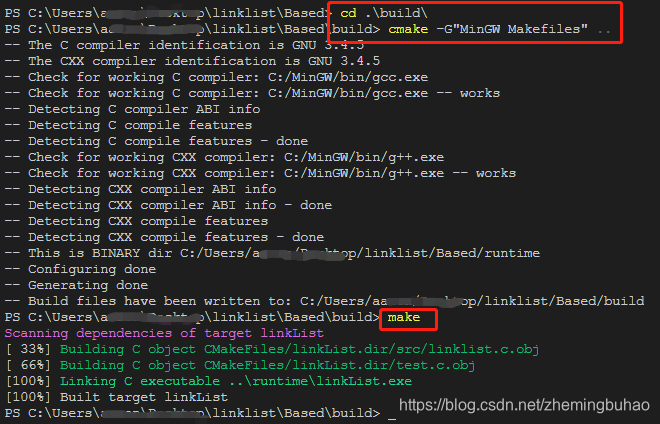
2、经过cmake编译之后,配置cmake将可执行文件放在固定目录runtime下,可以使用在当前目录下使用指令 ./../runtime/linkList.exe来运行可执行程序,也可以进入到目录runtime中,然后使用指令 ./linkList.exe ,即可运行测试程序。实际测试的结果如下图所示。
四、线性表链式存储的代码实现 - 通用链表
4.1、链表的存储结构
在底层库中,需要知道目前已经加入了多少节点、也需要让业务节点具有头部节点,方便后续的节点的查找,并且作为链表,还需要记录下一个节点的首地址,所以,其存储结构在C语言中可以使用结构体来表示为:
typedef void Linklist;
#define null NULL
typedef struct _tag_linklistNode
{
struct _tag_linklistNode *next;
} LinkListNode;
typedef struct _tag_Linklist
{
LinkListNode header;
int length;
} TLinklist;
4.2、操作函数定义
对于通用链表,由上面的说明,不再重复说明头插入、头删除、尾插入、尾删除等方法,本文设计的操作函数定义如下:
typedef struct __func_linklist
{
Linklist *(*create)(void);
int (*destory)(Linklist **list);
int (*clear)(Linklist *list);
int (*length)(Linklist *list);
int (*insert)(Linklist *list, LinkListNode *node, int pos); // 在链表的某个位置插入节点
LinkListNode *(*getNode)(Linklist *list, int pos); //获取某一个位置的节点
LinkListNode *(*delete)(Linklist *list, int pos); // 删除某个位置的节点
} func_linklist;
4.3、链表的元素插入
在3号位置插入新节点,也就是让原先的3号位置变成4号位置,4号位置变成5号位置。。那么插入的步骤应该是这样的。
1)让新节点(红色表示)链接尾部节点、作为新节点的后续节点,用蓝色线表示,也就是让3号位置的节点的地址赋值给新节点,而3号位置的地址保存在2号位置next域中,设置当前指针current指向2号位置节点,新插入的节点为node,那么,此时的代码可以为:
node->next = current->next;
2)让2号位置的节点连接新节点,用紫红色表示,也就是让2号位置的next域连接新的节点,代码可以为:
current->next = node;
3)、在执行第二步的时候,其实已经断开了原本第二个节点与第三个节点的连接,黑色表示,至此,新节点的插入完成。示例代码可以为:
/**
* 功 能:
* 在指定的位置插入一个元素
* 参 数:
* list:要操作的链表
* node:要插入的节点
* pos :要插入的位置
* 返回值:
* 成功:0
* 失败:-1
**/
int Linklist_insert(Linklist *list, LinkListNode *node, int pos)
{
int i = 0;
TLinklist *tlist = NULL;
LinkListNode *current = NULL;
if (list == NULL || node == NULL || pos < 0)
return -1;
tlist = (TLinklist *)list;
if (pos > tlist->length)
pos = tlist->length;
current = &(tlist->header);
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
// 让node链接后续的节点
node->next = current->next;
// 让前面的链表链接新的node节点
current->next = node;
// 让长度自加一
tlist->length++;
return 0;
}
4.4、链表的元素删除
假设要删除3号位置的节点,也就是让原先的4号位置变成3号位置,5号位置变成4号位置。所以:
1)要删除3号节点,那么需要先将3号位置节点的信息缓存,因为3号节点记录了4号位置节点的信息。所以设置当前指针current为2号位置节点,要删除的3号位置的节点为tmp,所以代码可以为:
tmp = current->next;
2)将2号位置的节点的Next域连接到4号节点,而4号节点的地址正好在要删除的3号节点next域中,所以代码可以为:
current->next = tmp->next;
3)至此,删除节点完成。
示例代码代码可以为:
/**
* 功 能:
* 从指定的位置删除一个元素
* 参 数:
* list:要操作的链表
* pos :要删除元素的位置
* 返回值:
* 成功:删除节点的首地址
* 失败:NULL
**/
LinkListNode *Linklist_delete(Linklist *list, int pos)
{
int i = 0;
TLinklist *tlist = NULL;
LinkListNode *current = NULL, *ret = NULL;
if (list == NULL || pos < 0)
return NULL;
tlist = (TLinklist *)list;
if (tlist->length < 1)
return NULL;
if (pos > tlist->length)
pos = tlist->length;
current = &(tlist->header);
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
// 缓存被删除的节点位置
ret = current->next;
// 连线,跳过要删除的节点
current->next = ret->next;
// 长度自减一
tlist->length--;
return ret; //将删除的节点的地址返回,让调用者析构这个内存
}
4.5、链表的元素获取
此通用链表的节点的获取,在原理上与传统链表一致,只是,此链表因为不知道业务节点中存在什么样的数据,什么样的结构,在设计的库函数中也无从对业务节点进行处理,所以,底层链表的操作库只能将业务节点的首地址传送出去,由上层调用者去处理具体的业务逻辑。
示例代码可以为
/**
* 功 能:
* 获取指定位置的元素
* 参 数:
* list:要操作的链表
* pos :要获取元素的位置
* 返回值:
* 成功:节点的首地址
* 失败:NULL
**/
LinkListNode *Linklist_Get(Linklist *list, int pos)
{
int i = 0;
TLinklist *tlist = NULL;
LinkListNode *current = NULL;
if (pos < 0 || list == NULL)
return NULL;
tlist = (TLinklist *)list;
if (pos > tlist->length)
pos = tlist->length;
// 让辅助指针变量指向链表的头部
current = &(tlist->header);
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
return current->next;
}
4.6、整体工程代码结构
为了兼容unix和windows系统以及方便进行工程管理,特意使用Cmake工具进行编译等,目前测试工程的目录结构如下所示。
linkList/
├── CMakeLists.txt
├── README.md
├── build
├── main
│ └── main.c
└── src
├── linklist.c
└── linklist.h
3 directories, 5 files
4.7、调用测试用例
前面已经说明整体工程的结构,以及需要的文件,与上面提到的传统链表的结构略有不同,实际没有区别。
4.7.1、业务节点定义
由上面的已经说明,通用链表并不关心业务节点是什么样式的,为了测试底层功能函数的功能、及明显的测试效果,并测试例程中定义两种不同结构的业务节点进行测试。
1)简单的教师的信息节点
typedef struct _tag_Teacher // 老师节点
{
LinkListNode Header; // 链表逻辑节点
int flag; // 业务节点的类型标识
int wages; // 哈哈,不知道写什么信息,就写个工资吧
char name[32]; // 姓名
} Teacher_t;
2)简单的学生的信息节点
typedef struct _tag_Student // 学生节点
{
LinkListNode Header; // 链表逻辑节点
int flag; // 业务节点的类型标识
int age; // 学生的年龄
char name[32]; // 姓名
struct score //学生的成绩结构体
{
int english;
int chinese;
int math;
} score;
} Student_t;
4.7.2、声明外部底层库函数对象
/* 声明底层链表的函数库 */
extern func_linklist fun_linklist;
4.7.3、测试代码demo
下面是测试底层功能函数的测试demo,主函数代码可以如下。
int main(int argc, char const **argv)
{
int Length = 0, i = 0;
Teacher_t t1, t2, t3, t4;
Student_t s1, s2, s3;
/* 初始化老师节点的信息 */
t1.flag = 0; // 以 flag = 0 标识为老师节点
t1.wages = 10;
strcpy(t1.name, "张三");
t2.flag = 0; // 以 flag = 0 标识为老师节点
t2.wages = 11;
strcpy(t2.name, "李四");
t3.flag = 0; // 以 flag = 0 标识为老师节点
t3.wages = 12;
strcpy(t3.name, "王五");
t4.flag = 0; // 以 flag = 0 标识为老师节点
t4.wages = 13;
strcpy(t4.name, "赵六");
/* 初始化学生节点的信息 */
s1.flag = 1; // 以 flag = 1 标识为老师节点
s1.age = 20;
strcpy(s1.name, "佩奇");
s1.score.english = 40;
s1.score.chinese = 41;
s1.score.math = 42;
s2.flag = 1; // 以 flag = 1 标识为老师节点
s2.age = 21;
strcpy(s2.name, "乔治");
s2.score.english = 50;
s2.score.chinese = 51;
s2.score.math = 52;
s3.flag = 1; // 以 flag = 1 标识为老师节点
s3.age = 22;
strcpy(s3.name, "社会人");
s3.score.english = 60;
s3.score.chinese = 61;
s3.score.math = 62;
/* 创建新的链表 */
Linklist *list = fun_linklist.create();
/* 插入老师节点和学生节点,头插入法 */
fun_linklist.insert(list, (LinkListNode *)&(t1), 0); //老师节点
fun_linklist.insert(list, (LinkListNode *)&(s1), 0); //学生节点
fun_linklist.insert(list, (LinkListNode *)&(t2), 0); //老师节点
fun_linklist.insert(list, (LinkListNode *)&(s2), 0); //学生节点
fun_linklist.insert(list, (LinkListNode *)&(t3), 0); //老师节点
fun_linklist.insert(list, (LinkListNode *)&(s3), 0); //学生节点
fun_linklist.insert(list, (LinkListNode *)&(t4), 0); //老师节点
/* 获取当前链表的长度 */
Length = fun_linklist.length(list);
printf("line = %3d, linklist length = %d\n", __LINE__, Length);
putchar(10);
for (i = 0; i < Length; i++)
{
/* 获取节点,此处采用最简单的办法,默认为老师节点,然后判断flag来最终确定节点类型 */
Teacher_t *tlist = (Teacher_t *)fun_linklist.getNode(list, i);
if (tlist != NULL)
{
if (tlist->flag == 0) // 为老师的节点
{
printf("line = %3d, Teacher, name = %8s, wages = %d\n",
__LINE__, tlist->name, tlist->wages);
}
else if (tlist->flag == 1) // 为学生节点
{
Student_t *temp = (Student_t *)tlist;
printf("line = %3d, Student, name = %8s, age = %d, english = %3d, chinese = %3d, math = %3d\n",
__LINE__, temp->name, temp->age, temp->score.english,
temp->score.chinese, temp->score.math);
}
}
}
putchar(10);
for (i = 0; i < Length; i++)
{
/* 删除节点,头删除法 */
Teacher_t *tlist = (Teacher_t *)fun_linklist.delete(list, 0);
if (tlist != NULL)
{
if (tlist->flag == 0) // 为老师的节点
{
printf("line = %3d, Teacher, name = %8s, wages = %d\n",
__LINE__, tlist->name, tlist->wages);
/* 释放要删除的节点,并将临时指针指向NULL */
free(tlist);
tlist = NULL;
}
else if (tlist->flag == 1) // 为学生节点
{
Student_t *temp = (Student_t *)tlist;
printf("line = %3d, Student, name = %8s, age = %d, english = %3d, chinese = %3d, math = %3d\n",
__LINE__, temp->name, temp->age, temp->score.english,
temp->score.chinese, temp->score.math);
/* 释放要删除的节点,并将临时指针指向NULL */
free(temp);
temp = NULL;
}
}
}
/* 清空链表 */
fun_linklist.clear(list);
/* 重新获取链表的长度 */
Length = fun_linklist.length(list);
printf("line = %3d, linklist length = %d\n", __LINE__, Length);
/* 销毁链表*/
fun_linklist.destory(&list);
if (list == NULL)
{
printf("list = NULL, free success\n");
}
else
{
printf("list = %p, free failed\n", list);
free(list);
}
return 0;
}
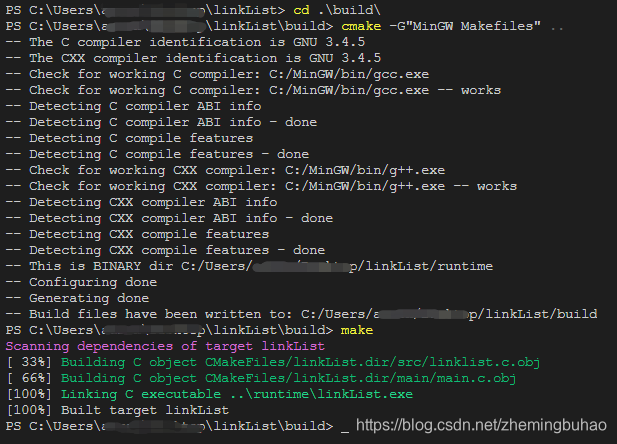
4.8、测试编译运行结果
本次测试是在windows环境下进行,详细说明在README.md中查看。
1)使用Cmake编译,使用下面指令
cd build
cmake -G"MinGW Makefiles" .. # 注意 .. ,表示上级目录
make
实际在运行指令过程效果如下图所示。
2)经过cmake编译之后,配置cmake将可执行文件放在固定目录runtime下,可以使用在当前目录下使用指令 ./../runtime/linkList.exe来运行可执行程序,也可以进入到目录runtime中,然后使用指令 ./linkList.exe ,即可运行测试程序。实际测试的结果如下图所示。
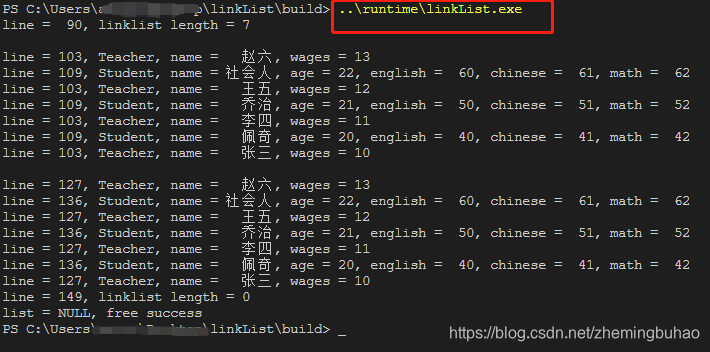
至此,代码全部运行完成。
五、优点和缺点
5.1、优点
- 无需一次性定制链表的容量
- 插入和删除操作无需移动数据元素
5.2、缺点
- 数据元素必须保存后继元素的位置信息
- 获取指定的数据元素操作需要顺序访问之前的元素
六、后记
有上描述以及代码测试,可以看出来,链表的应用比较适合场合基本为:
1、对于线性表的规模或者长度难以确定
2、会频繁的进行插入或者删除操作
3、构建动态性比较强的应用
如果你也对此感兴趣、也想测试源码的话,可以私聊我,非常欢迎一起探讨学习。嘻嘻。。。。

上一篇:数据结构(二) – C语言版 – 线性表的顺序存储
下一篇:数据结构(四) – C语言版 – 线性表的链式存储 - 循环链表、双链表