文章目录
零、读前说明
- 本文中没有涉及到很多的相关理论知识,也没有做深入的了解,所以,您如果是想要系统的学习、想要多学习关于理论的知识等,那么本文可能并不合适您。
- 本文中所有设计的代码均通过测试,并且在功能性方面均实现应有的功能。
- 设计的代码并非全部公开,部分无关紧要代码并没有贴出来。
- 如果你也对此感兴趣、也想测试源码的话,可以私聊我,非常欢迎一起探讨学习。
- 由于时间、水平、精力有限,文中难免会出现不准确、甚至错误的地方,也很欢迎大佬看见的话批评指正。
- 嘻嘻。。。。 。。。。。。。。收!
一、循环链表的概述
循环链表的定义,是将单链表中的最后一个节点的next指针域指向第一个节点,将原本的单链表形成闭环。
二、循环链表的模型
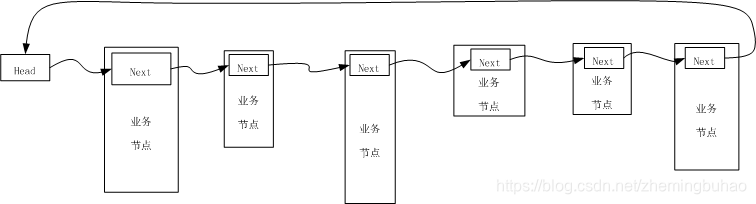
2.1、包含头节点模型
包含头结点的模型,其示意图如下图所示。
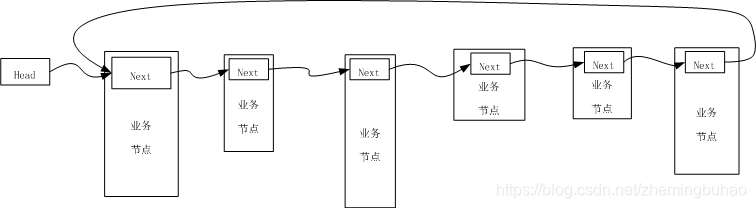
2.2、不包含头节点模型
不包含头结点的模型,其示意图如下图所示。
三、工程结构及简单测试案例
首先使用一个简单的从单链表修改过来的demo程序来直观感受一下循环链表的操作。
3.1、测试工程的目录结构
为了兼容unix和windows系统以及方便进行工程管理,特意使用Cmake工具进行编译等,目前测试工程的目录结构如下所示。
cyclelist/
├── CMakeLists.txt
├── README.md
├── build
├── main
│ └── main.c
├── runtime
└── src
├── cyclelist.c
└── cyclelist.h
4 directories, 5 files
如上图所示的目录结构,下面所有的测试的工程目录结构与上述一致,只是可能部分文件名称不一样。
3.2、循环链表示例源码
1、cyclelist.c文件内容如下:
#include "cyclelist.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//创建空的循环链表
linknode_t *Cyclelist_create(void)
{
linknode_t *head = (linknode_t *)malloc(sizeof(linknode_t)); //开辟头节点的空间
memset(head, 0, sizeof(linknode_t));
head->next = head;
return head;
}
//尾插入法
int Cyclelist_insert_tail(linknode_t *head, data_t value)
{
linknode_t *temp = head; //temp临时记录头节点
linknode_t *node = (linknode_t *)malloc(sizeof(linknode_t)); //开辟新节点的空间
node->data = value;
node->next = head;
while (head->next != temp)
head = head->next; //head向后移动一个节点
//结束循环时,head指向最后一个节点
head->next = node; //最后一个节点与新节点相连
return 0;
}
//遍历
int Cyclelist_show(linknode_t *head)
{
linknode_t *temp = head; //temp临时记录头节点
while (head->next != temp)
{
head = head->next;
printf("%d ", head->data);
}
putchar(10);
return 0;
}
//砍掉头节点
linknode_t *Cyclelist_cut_head(linknode_t *head)
{
linknode_t *temp = head;
while (head->next != temp)
head = head->next; //结束循环时head指向最后一个节点
head->next = temp->next; //最后一个节点与第一个节点相连,把头隔开
free(temp);
temp = NULL;
return head->next; //返回新的头(第一个节点的地址)
}
//无头的遍历
int Cyclelist_show_nohead(linknode_t *head)
{
linknode_t *temp = head;
while (head->next != temp)
{
printf("%d ", head->data); //结束循环时head指向最后一个节点
head = head->next;
}
printf("%d\n", head->data);
return 0;
}
// 证明我是循环链表
int Cyclelist_show_Prove(linknode_t *head, int cnt)
{
while (cnt)
{
printf("%d ", head->data);
head = head->next;
cnt--;
}
putchar(10);
return 0;
}
2、cyclelist.h文件内容如下:
#ifndef __LINKLIST_H__
#define __LINKLIST_H__
//数据类型
typedef int data_t;
//节点类型
typedef struct node
{
data_t data;
struct node *next;
} linknode_t;
//创建空的循环链表
linknode_t *Cyclelist_create(void);
//尾插入法
int Cyclelist_insert_tail(linknode_t *head, data_t value);
//遍历
int Cyclelist_show(linknode_t *head);
//砍掉头节点
linknode_t *Cyclelist_cut_head(linknode_t *head);
//无头的遍历
int Cyclelist_show_nohead(linknode_t *head);
// 证明我是循环链表
int Cyclelist_show_Prove(linknode_t *head, int cnt)
#endif
3.3、简单测试案例
main.c文件内容如下:
#include "../src/cyclelist.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, const char **argv)
{
linknode_t *list = Cyclelist_create();
Cyclelist_insert_tail(list, 10);
Cyclelist_insert_tail(list, 20);
Cyclelist_insert_tail(list, 30);
Cyclelist_insert_tail(list, 40);
Cyclelist_insert_tail(list, 50);
Cyclelist_insert_tail(list, 60);
printf("尾插入法:");
Cyclelist_show(list);
list = Cyclelist_cut_head(list);
printf("砍头函数:");
Cyclelist_show_nohead(list);
printf("证明测试:");
Cyclelist_show_Prove(list, 12);
return 0;
}
3.4、测试功能构建编译
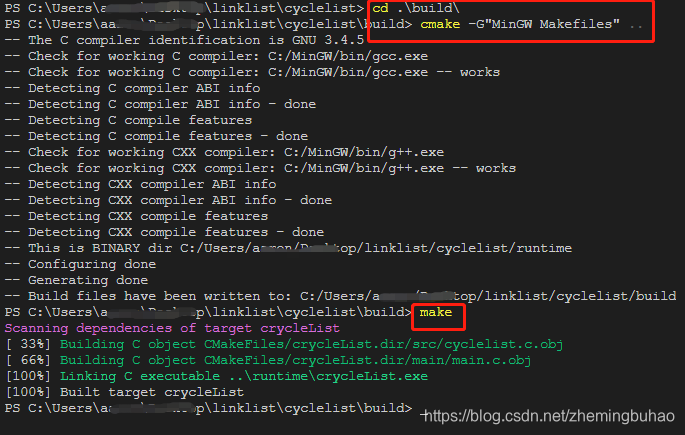
构建过程使用cmake工具进行编译,使用如下指令即可。 本次测试是在windows环境下进行,其他系统等详细说明在README.md中查看。
cd build
cmake -G"MinGW Makefiles" ..
make
使用的效果如下图所示。
3.5、测试结果
经过cmake编译之后,配置cmake将可执行文件放在固定目录runtime下,可以使用在当前目录下使用指令 ./../runtime/linkList.exe来运行可执行程序,也可以进入到目录runtime中,然后使用指令 ./linkList.exe ,即可运行测试程序。实际测试的结果如下图所示。

四、通用循环链表的操作
下面所有的操作,均是指在不包含头节点的循环链表的操作。
下面首先简单的说明一下简单的工程结构以及部分函数的简单的代码。
4.1、循环链表的操作概述
循环链表即是由单链表转换而来,所以,循环链表拥有单链表的所有操作,主要包括如下几个操作。
创建链表
销毁链表
获取链表的长度
清空链表
获取节点
插入节点
删除节点
同样,作为新形式的链表,也有自己的特有的操作,即在循环联众可以定义一个表示“当前”的指针,这个指针通常称为游标,可以通过这个游标来遍历链表中的所有元素。
循环链表中的新的操作。
// 重置游标
CycleListNode *CycleList_Reset(CycleList *list);
// 获取游标所指节点的数据元素
CycleListNode *CycleList_Current(CycleList *list);
// 将游标指向链表中下一个节点
CycleListNode *CycleList_Next(CycleList *list);
// 删除链表中指定的节点
CycleListNode *CycleList_DelectNode(CycleList *list, CycleList *node);
4.2、循环链表的结构定义
在单项链表的基础上,循环链表内部结构定义中,在其内部定义一个游标指针。
在本例程中使用的结构体的定义如下所示。
typedef void Cyclelist;
#define null NULL
typedef struct _tag_cyclelistNode
{
struct _tag_cyclelistNode *next;
} CyclelistNode;
typedef struct _tag_Cyclelist
{
CyclelistNode header;
CyclelistNode *slider;
int length;
} TCyclelist;
4.3、循环链表的操作函数申明
在本例中,使用的循环链表的操作函数如下所示。
#ifndef __LINKLIST_H__
#define __LINKLIST_H__
typedef void Cyclelist;
#define null NULL
typedef struct _tag_cyclelistNode
{
struct _tag_cyclelistNode *next;
} CyclelistNode;
typedef struct _tag_Cyclelist
{
CyclelistNode header;
CyclelistNode *slider;
int length;
} TCyclelist;
typedef struct __func_cyclelist
{
Cyclelist *(*create)(void);
int (*destory)(Cyclelist **list);
int (*clear)(Cyclelist *list);
int (*length)(Cyclelist *list);
int (*insert)(Cyclelist *list, CyclelistNode *node, int pos);
CyclelistNode *(*get)(Cyclelist *list, int pos);
CyclelistNode *(*delete)(Cyclelist *list, int pos);
CyclelistNode *(*deleteNode)(Cyclelist *list, CyclelistNode *node);
CyclelistNode *(*reset)(Cyclelist *list);
CyclelistNode *(*current)(Cyclelist *list);
CyclelistNode *(*next)(Cyclelist *list);
} func_cyclelist;
#endif
4.4、循环链表的插入操作
循环链表需要仔细考虑是头插法,还是尾插法,引进辅助指针变量current,指向链表的头部,然后让当前指针向后移动,直到pos或者current==NULL;此时,
- 普通位置插入节点,所有的操作还是和单链表的操作一致。
- 如果是第一次插入节点,需要让游标指针指向零号节点,
- 如果是进行头插法,此时current还是指向头部,还需要知道最后一个元素,然后让最后一个元素的next域指向当前要插入的新节点。
- 如果是尾插法,则还是和单链表的没有一样。辅助指针向后移动length次,指向最后那个节点。
所以,下面将详细说明各种插入方式以及示意图。
4.4.1、普通位置插入
如下图所示,其插入法与单链表完全一致。此处不再详细说明。详情可参考 数据结构(三) – C语言版 – 线性表的链式存储 - 单链表

4.4.2、尾部插入
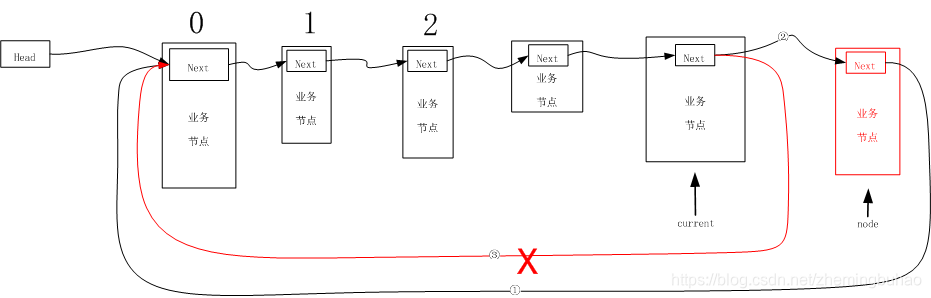
让辅助指针变量current向后移动链表长度次,此时,辅助指针变量current又指向链表尾部,那么尾插入法需要做的是:
①让要插入的节点node链接后续节点,即0号位置的节点,存在于current->next中
②让原先尾部节点current的next链接新插入的节点node
③在执行②的过程中,连接线③自动断开,即可完成尾插入法
所以,示意图可以如下图所示。
4.4.3、头部插入
首先,应该如何去判断是头插入法呢?
应该是让current指针移动,当移动0次之后,current还是和head一致,此时则说明是头部插入法。
对于头插入法,也就是在插入完成后,将0号位置节点变成1号位置节点。而此时,current即为head,所以步骤可以为:
①让新节点node链接0号位置,让0号位置变成1号位置
②让头结点链接新插入的节点node。
③此时,执行②之后,连接线③会自动断开
④完场上述步骤之后,头插入法已经成功将新节点插入,但是,此时的链表并没有形成闭环的形式,因为原来形成闭环的是连接在原先的0号位置(现在的1号位置),所以,此时还需要求出尾部节点,让尾部指针连接到新节点node,此时,才真正形成一个完整的闭环。
所以,头插入法的示意图可以如下图所示。
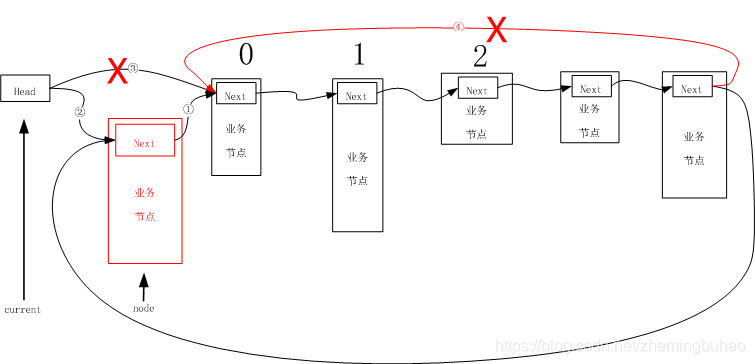
4.4.4、第一次插入
第一次插入节点,此时即是尾插法,也是头插法。
刚开始头结点指向NULL,如果要插入新节点,那么应该是如下图所示状态。

如果要进行尾插入法进行插入一个新节点,那么可以是
①新节点的next域指向后驱节点,即NULL
②让头结点链接新插入节点node
③在执行②的过程中,head指向NULL的连接线③链接自动断开
所以,其简单示意图可以如下图所示。
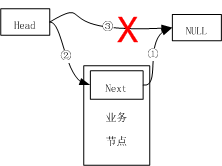
如果是单向链表,那么现在应该可以算是完成,但是现在说的是循环链表,所以还需要的是
①需要将新插入节点node的next域指向自己才能形成闭环
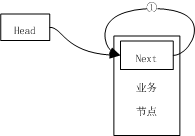
综上所述,循环链表的插入的代码可以为:
/**
* 功 能:
* 在指定的位置插入一个元素
* 参 数:
* list:要操作的链表
* node:要插入的节点
* pos :要插入的位置
* 返回值:
* 成功:0
* 失败:-1
**/
int Cyclelist_insert(Cyclelist *list, CyclelistNode *node, int pos)
{
int i = 0;
TCyclelist *slist = NULL;
/* 参数判断 */
if (list == NULL || node == NULL || pos < 0)
return -1;
/* 参数判断并矫正 */
slist = (TCyclelist *)list;
if (pos > slist->length)
pos = slist->length;
/* 下面两个个语句实现的效果一致 */
// CyclelistNode *current = &(slist->header);
CyclelistNode *current = (CyclelistNode *)slist;
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
// 让node链接后续的节点
node->next = current->next;
// 让前面的链表链接新的node节点
current->next = node;
// 如果是第一次插入元素
if (slist->length == 0)
{
slist->slider = node;
node->next = node;
}
// 如果是头插法,则current还是指向头部
// 如果链表是初始的状态,即只有头节点,没有其他的任何业务节点,那么
// 最后一个节点也是第一个节点,还需要下面的操作吗,你品,你细品。
if (current == (CyclelistNode *)slist && slist->length > 0)
{
// 获取最后一个节点
CyclelistNode *last = Cyclelist_Get(slist, slist->length );
last->next = current->next;
}
// 让长度自加一
slist->length++;
return 0;
}
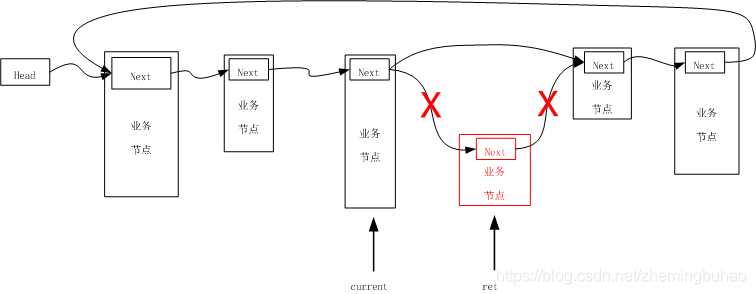
4.5、删除节点
4.5.1、删除普通节点
要删除节点,需要缓存业务节点,然后将删除的节点返回让调用者进行处理,所以定义辅助指针变量ret缓存要删除的 节点,引进辅助指针变量current,并且指向链表的头部。
①让当前指针current向后移动pos次,找到要删除节点的位置
②直接进行连线即可完成节点的删除
③由此可见,普通位置的节点删除和单向链表的操作是一样的。
并且,如果要进行尾部节点的删除,其操作与此一样。
所以,其示意图可以如下图所示。
4.5.2、删除头节点
判断是否为头删除的方法,与上面插入的判断条件是一样的。
①首先按照单向链表的形式删除头节点,直接连线③,此时连接线①和连接线②断开
②此时,连接线④并没有改变,还连接在要删除的头节点上,并且链接⑤暂时不存在
③为了使得删除完头节点还能形成闭环的形式,所以删除0号位置的节点,需要求出尾节点。所以引出辅助指针变量last,将尾节点last的next域连接到1号位置节点,此时连接线④自动断开。
至此,头删除链表才算正式完成。
所以,其示意图可以如下图所示。

综上所述,循环链表的删除的代码可以为:
/**
* 功 能:
* 从指定的位置删除一个元素
* 参 数:
* list:要操作的链表
* pos :要删除元素的位置
* 返回值:
* 成功:删除节点的首地址
* 失败:NULL
**/
CyclelistNode *Cyclelist_delete(Cyclelist *list, int pos)
{
int i = 0;
TCyclelist *slist = (TCyclelist *)list;
CyclelistNode *current = NULL, *ret = NULL;
CyclelistNode *last = NULL;
if (list == NULL || pos < 0 || slist->length < 1)
return NULL;
if (pos > slist->length) pos = slist->length;
// current = &(slist->header);
current = (CyclelistNode *)slist;
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
// 若删除头节点
if (current == (CyclelistNode *)slist)
{
last = (CyclelistNode *)Cyclelist_Get(slist, slist->length - 1);
}
// 缓存被删除的节点位置
ret = current->next;
// 连线,跳过要删除的节点
current->next = ret->next;
// 长度自减一
slist->length--;
// 判断链表是否为空
if (last != NULL)
{
slist->header.next = ret->next;
last->next = ret->next;
}
// 若删除元素为游标所指的元素
if (slist->slider == ret) slist->slider = ret->next;
// 如果删除元素后,链表长度为0
if (slist->length == 0)
{
slist->header.next = NULL;
slist->slider = NULL;
}
return ret; //将删除的节点的地址返回,让调用者析构这个内存
}
4.6、其他新增操作函数
4.6.1、获取节点
循环链表的获取节点的代码可以为:
/**
* 功 能:
* 获取指定位置的元素
* 参 数:
* list:要操作的链表
* pos :要获取元素的位置
* 返回值:
* 成功:节点的首地址
* 失败:NULL
**/
CyclelistNode *Cyclelist_Get(Cyclelist *list, int pos)
{
int i = 0;
TCyclelist *slist = NULL;
CyclelistNode *current = NULL;
if (pos < 0 || list == NULL)
return NULL;
slist = (TCyclelist *)list;
// 从循环链表的角度来说,pos的值只要是大于0的应该都是合法的
// 你品,你细品
// if (pos > slist->length)
// pos = slist->length;
// 让辅助指针变量指向链表的头部
// current = &(slist->header);
current = (CyclelistNode *)slist;
while (i < pos && current->next != NULL)
{
i++;
current = current->next;
}
return current->next;
}
4.6.2、删除指定的节点
循环链表的删除指定的节点的代码可以为:
/**
* 功 能:
* 删除一个指定的元素
* 参 数:
* list:要操作的链表
* node:要删除元素
* 返回值:
* 成功:删除节点的首地址
* 失败:NULL
**/
CyclelistNode *Cyclelist_deleteNode(Cyclelist *list, CyclelistNode *node)
{
TCyclelist *slist = (TCyclelist *)list;
CyclelistNode *ret = NULL;
int i = 0;
if (slist == NULL || node == NULL)
return NULL;
CyclelistNode *current = (CyclelistNode *)slist;
// 查找node在链表中的位置
for (i = 0; i < slist->length; i++)
{
if (current->next == node)
{
ret = current->next;
break;
}
current = current->next;
}
// 如果ret 找到,根据 循环变量 i 去删除节点
if (ret != NULL)
{
Cyclelist_delete(slist, i);
}
return ret;
}
4.6.3、游标复位
循环链表的游标复位的代码可以为:
/**
* 功 能:
* 将游标复位
* 参 数:
* list:要操作的链表
* 返回值:
* 成功:复位之后的游标的值
* 失败:NULL
**/
CyclelistNode *Cyclelist_Reset(Cyclelist *list)
{
TCyclelist *slist = (TCyclelist *)list;
if (slist == NULL)
return NULL;
slist->slider = slist->header.next;
return slist->slider;
}
4.6.4、获取当前游标
循环链表的获取当前游标的代码可以为:
/**
* 功 能:
* 获取当前游标的值
* 参 数:
* list:要操作的链表
* 返回值:
* 成功:当前游标的值
* 失败:NULL
**/
CyclelistNode *Cyclelist_Current(Cyclelist *list)
{
TCyclelist *slist = (TCyclelist *)list;
if (slist == NULL)
return NULL;
return slist->slider;
}
4.6.5、游标后移
循环链表的游标后移的代码可以为:
/**
* 功 能:
* 将游标后移,指向链表中下一个节点
* 参 数:
* list:要操作的链表
* 返回值:
* 成功:移动后游标的值
* 失败:NULL
**/
CyclelistNode *Cyclelist_Next(Cyclelist *list)
{
TCyclelist *slist = (TCyclelist *)list;
CyclelistNode *ret = NULL;
if (slist == NULL || slist->slider == NULL)
return NULL;
ret = slist->slider;
slist->slider = ret->next;
return ret;
}
4.7、简单的测试案例
4.7.1、循环链表的证明
是的,既然是循环链表,光从代码的层面是不能证明你就是对的,所以,一定要自己证明自己就是自己,就像你想要给别人点颜色看看,那么首先你要知道是什么颜色的一样,当然,你看我就是知道:
这是红色
这是绿色
这是黄色
想要证明自己自己就是循环链表,那么,最简单、最直观的方法就是直接连续不间断获取两次节点并打印出来,如果不是循环链表,那么在进行第二次获取节点的时候中断。
所以,证明自己就是自己的示例代码可以为:
for(i = 0; i < 2 * cyclelist.length; i++)
{
cyclelist_t* node = cyclelist.get(list, 0);
printf("node->data = %d\n", node->data);
}
本测试案例中,使用的证明的方法也是这样,详细请往下看。
4.7.2、调用测试案例
前面用实力证明了自己,那么可以光明正大的办事情了。
此处调用的测试案例的代码与单链表的测试案例是一样的,只是修改了链表的逻辑节点为 cyclelist 类型。其他的均为改变。所以,此处不再贴出详细的代码,详细代码可以查看文章:
数据结构(三) – C语言版 – 线性表的链式存储 - 单链表
此处只贴证明是循环链表的部分代码,如下所示。
/* 获取当前链表的长度 */
Length = fun_cyclelist.length(list);
printf("line = %3d, linklist length = %d\n", __LINE__, Length);
putchar(10);
for (i = 0; i < 2 * Length; i++)
{
/* 获取节点,此处采用笨办法,默认为老师节点,然后判断flag来最终确定节点类型 */
Teacher_t *tlist = (Teacher_t *)fun_cyclelist.get(list, i);
if (tlist != NULL)
{
if (tlist->flag == 0) // 为老师的节点
{
printf("line = %3d, Teacher, name = %8s, wages = %d\n",
__LINE__, tlist->name, tlist->wages);
}
else if (tlist->flag == 1) // 为学生节点
{
Student_t *temp = (Student_t *)tlist;
printf("line = %3d, Student, name = %8s, age = %d, english = %3d, chinese = %3d, math = %3d\n",
__LINE__, temp->name, temp->age, temp->score.english,
temp->score.chinese, temp->score.math);
}
}
}
4.7.3、测试编译运行结果
为了兼容unix和windows系统以及方便进行工程管理,特意使用Cmake工具进行编译等,目前测试工程的目录结构如下所示。
cyclelist/
├── CMakeLists.txt
├── README.md
├── build
├── main
│ └── main.c
├── runtime
└── src
├── cyclelist.c
└── cyclelist.h
4 directories, 5 files
如上图所示的目录结构。并且通过简单的几个指令即可完成编译工作,分别如下:
cmake -G"MinGW Makefiles" ../
make
./../runtime/crycleList.exe
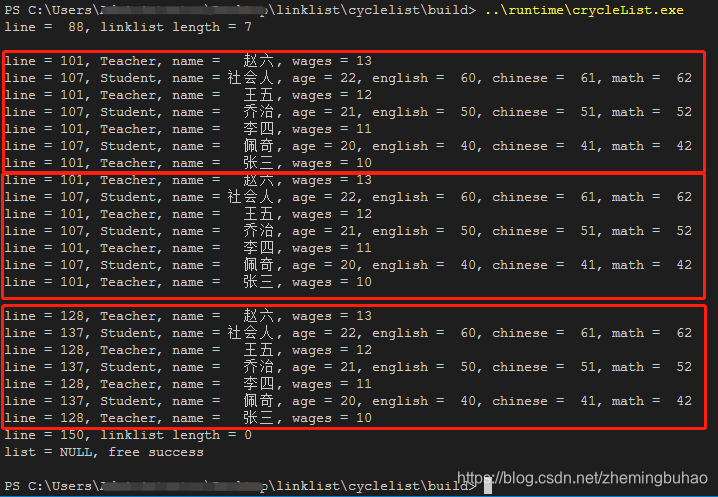
实际编译的效果如下所示。

实际运行的效果如下所示。
五、优点和缺点
5.1、优点
- 循环链表只是在单链表的基础上做了一个加强
- 循环链表可以完全取代单链表
- 循环链表中的next和current操作可以高效的遍历链表中所有元素
5.2、缺点
- 相对单链表,代码的复杂度增加了
六、典型应用 - 约瑟夫问题
6.1、约瑟夫问题概述
约瑟夫问题(有时也称为约瑟夫斯置换,是一个出现在计算机科学和数学中的问题。在计算机编程的算法中,类似问题又称为约瑟夫环。又称“丢手绢问题”。)(来自《百度百科》)
约瑟夫环(约瑟夫问题)是一个有名的数学的应用问题:已知有N个人(以编号1,2,3…N分别表示)围坐成一个圈。从编号为1的人开始报数,数到m的那个人出列,而他的下一个人又从1开始报数,数到m的那个人又出列;依此规律重复下去,直到所有人全部出列。
6.2、解决思路与方法
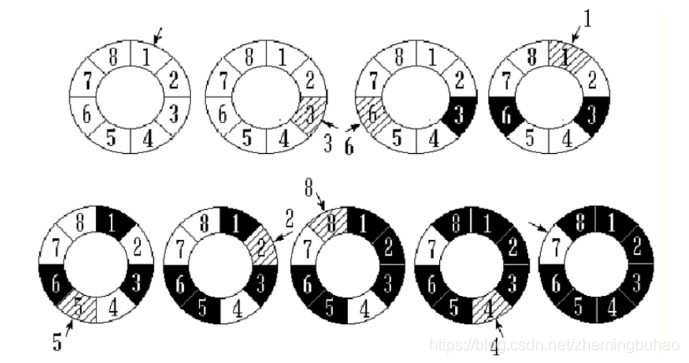
有上面的叙述,可以想到,约瑟夫问题的可以用循环链表来表示。可以用下面这个图说的明明白白的。(图片来源于网络)
此图中表示的也是一个经典的 8-3 的示意图。
6.3、代码实现
假设团队中总共有 8 个人, 报数报道 NUM 的人出列,那么,整个约瑟夫问题的创建以及解决的过程代码可以为如下:
本代码中意报道数为3的人出列,所以,定义 NUM=3; 如果有兴趣,可自行进行修改并验证其他数值。
#include "../src/cyclelist.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* 声明底层链表的函数库 */
extern func_cyclelist fun_cyclelist;
typedef struct _tag_value //
{
CyclelistNode Header; // 链表逻辑节点
int value; // 业务节点的类型标识
} value_t;
#define NUM 3
int main(int argc, char const **argv)
{
int Length = 0, i = 0;
value_t d1, d2, d3, d4, d5, d6, d7, d8;
d1.value = 1;
d2.value = 2;
d3.value = 3;
d4.value = 4;
d5.value = 5;
d6.value = 6;
d7.value = 7;
d8.value = 8;
/* 创建新的链表 */
Cyclelist *list = fun_cyclelist.create();
/* 插入节点,尾插入法 */
fun_cyclelist.insert(list, (CyclelistNode *)&(d1), fun_cyclelist.length(list)); // 1
fun_cyclelist.insert(list, (CyclelistNode *)&(d2), fun_cyclelist.length(list)); // 2
fun_cyclelist.insert(list, (CyclelistNode *)&(d3), fun_cyclelist.length(list)); // 3
fun_cyclelist.insert(list, (CyclelistNode *)&(d4), fun_cyclelist.length(list)); // 4
fun_cyclelist.insert(list, (CyclelistNode *)&(d5), fun_cyclelist.length(list)); // 5
fun_cyclelist.insert(list, (CyclelistNode *)&(d6), fun_cyclelist.length(list)); // 6
fun_cyclelist.insert(list, (CyclelistNode *)&(d7), fun_cyclelist.length(list)); // 7
fun_cyclelist.insert(list, (CyclelistNode *)&(d8), fun_cyclelist.length(list)); // 8
/* 打印当前链表的长度 */
printf("\nlinklist length = %d, ", fun_cyclelist.length(list));
/* 按顺序输出当前链表中的节点 */
for (i = 0; i < fun_cyclelist.length(list); i++)
{
value_t *t1 = (value_t *)fun_cyclelist.current(list);
printf("%d ", t1->value);
fun_cyclelist.next(list);
}
putchar(10);
putchar(10);
/* 复位游标 */
fun_cyclelist.reset(list);
/* 开始进行约瑟夫的问题解决 */
printf("Josephus's order is : ");
while (fun_cyclelist.length(list) > 0)
{
value_t *temp = NULL;
for(i = 1; i < NUM; i++) fun_cyclelist.next(list);
temp = (value_t *)fun_cyclelist.current(list);
printf("%d ", temp->value);
fun_cyclelist.deleteNode(list, (CyclelistNode *)temp);
}
/* 清空链表 */
fun_cyclelist.clear(list);
/* 重新获取链表的长度 */
Length = fun_cyclelist.length(list);
printf("\n\nlinklist length = %d\n", Length);
/* 销毁链表*/
fun_cyclelist.destory(&list);
if (list == NULL)
{
printf("list = NULL, free success\n");
}
else
{
printf("list = %p, free failed\n", list);
free(list);
}
return 0;
}
6.4、运行效果
如之前所述,本次采用的结构也是如上面一样,也是使用camke 进行整体生成和管理,所以,上述代码的实际运行的效果如下图所示。

6.5、简单的解决代码
当然,如果只是想简简单单的验证并尝试一下约瑟夫问题,那么可以使用下面的简单的代码进行测试,那么,代码来了:
#include <stdio.h>
#include <stdlib.h>
//数据类型
typedef int data_t;
//节点类型
typedef struct node
{
data_t data;
struct node *next;
} linknode_t;
//创建空的循环链表
linknode_t *linkloop_create()
{
linknode_t *head = (linknode_t *)malloc(sizeof(linknode_t)); //开辟头节点的空间
head->next = head;
return head;
}
//尾插入法
int linkloop_insert_tail(linknode_t *head, data_t value)
{
linknode_t *temp = head; //temp临时记录头节点
linknode_t *node = (linknode_t *)malloc(sizeof(linknode_t)); //开辟新节点的空间
node->data = value;
node->next = head;
while (head->next != temp)
head = head->next; //head向后移动一个节点
//结束循环时,head指向最后一个节点
head->next = node; //最后一个节点与新节点相连
return 0;
}
//遍历
int linkloop_show(linknode_t *head)
{
linknode_t *temp = head; //temp临时记录头节点
while (head->next != temp)
{
head = head->next;
printf("%d ", head->data);
}
putchar(10);
return 0;
}
//砍掉头节点
linknode_t *linkloop_cut_head(linknode_t *head)
{
linknode_t *temp = head;
while (head->next != temp)
head = head->next; //结束循环时head指向最后一个节点
head->next = temp->next; //最后一个节点与第一个节点相连,把头隔开
free(temp);
temp = NULL;
return head->next; //返回新的头(第一个节点的地址)
}
//无头的遍历
int linkloop_show_nohead(linknode_t *head)
{
linknode_t *temp = head;
while (head->next != temp)
{
printf("%d ", head->data); //结束循环时head指向最后一个节点
head = head->next;
}
printf("%d\n", head->data);
return 0;
}
int linkloop_joseph(linknode_t *head, int k, int m)
{
int i;
for (i = 1; i < k; i++)
head = head->next; //循环结束时指针指向第k个人
while (head->next != head)
{
for (i = 1; i < m; i++)
head = head->next;
printf("%d ", head->data);
head = linkloop_cut_head(head);
}
printf("%d\n", head->data);
return 0;
}
int main(int argc, const char *argv[])
{
int i;
int n = 8, k = 0, m = 3;
linknode_t *l = linkloop_create(); //创建空的循环链表
for (i = 1; i <= n; i++)
{
linkloop_insert_tail(l, i); //尾插入8个数据
}
l = linkloop_cut_head(l); //砍头
linkloop_show_nohead(l); //遍历
linkloop_joseph(l, k, m);
return 0;
}
好啦,就弄到这儿吧。。。。
上一篇:数据结构(三) – C语言版 – 线性表的链式存储 - 单链表
下一篇:数据结构(五) – C语言版 – 线性表的链式存储 - 双向链表、双向循环链表