Redis主从配置和集群配置
文章目录
一、Redis主从配置
1.主从概念
- ⼀个master可以拥有多个slave,⼀个slave⼜可以拥有多个slave,如此下去,形成了强⼤的多级服务器集群架构
- master用来写数据,slave用来读数据,经统计:网站的读写比率是10:1
- 通过主从配置可以实现读写分离
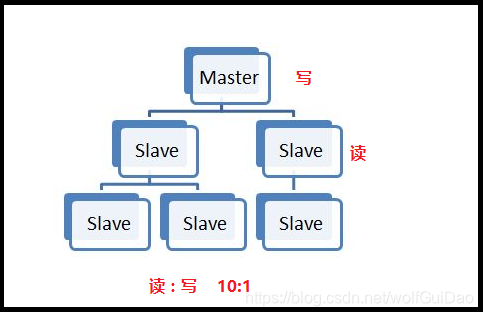
master和slave都是一个redis实例(redis服务)
2.主从配置
-
配置主 - 查看当前主机的ip地址
ifconfig
- 修改etc/redis/redis.conf文件
sudo vi redis.conf
bind 192.168.26.128
重启redis服务
sudo service redis stop
redis-server redis.conf
-
配置从 - 复制etc/redis/redis.conf文件
sudo cp redis.conf ./slave.conf
修改redis/slave.conf文件
sudo vi slave.conf
编辑内容
bind 192.168.26.128
slaveof 192.168.26.128 6379
port 6378
- redis服务
sudo redis-server slave.conf
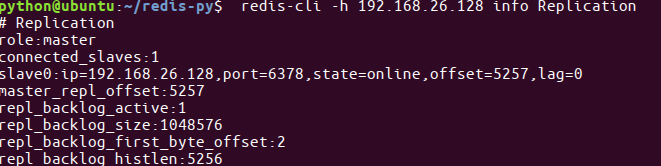
- 查看主从关系
redis-cli -h 192.168.26.128 info Replication
3.数据操作
- 在master和slave分别执⾏info命令,查看输出信息 进入主客户端
redis-cli -h 192.168.26.128 -p 6379
- 进入从的客户端
redis-cli -h 192.168.26.128 -p 6378
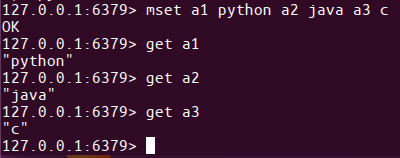
- 在master上写数据
set aa aa

- 在slave上读数据
get aa
二、Redis集群配置
1.简介
-
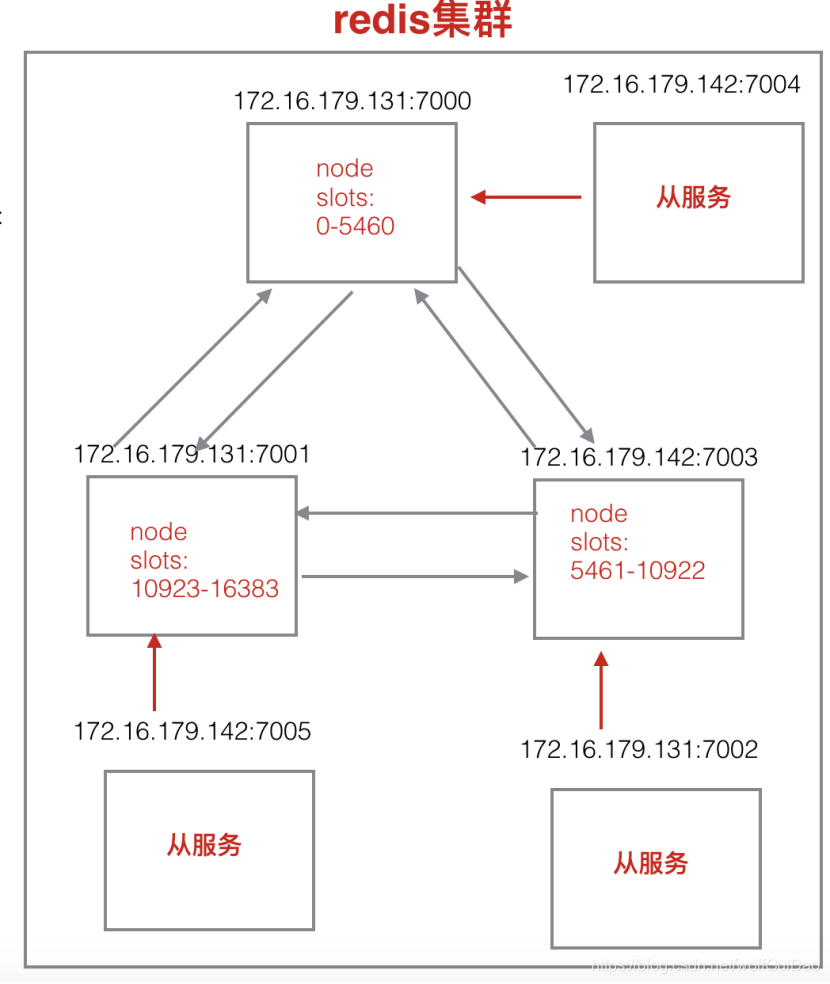
集群:一组通过网络连接的计算机,共同对外提供服务,像一个独立的服务器 - Redis集群是一个由多个节点组成的分布式服务器群,它具有复制、高可用和分片特性;
-
Redis集群没有中心节点,并且带有复制和故障转移特性,这可以避免单个节点成为性能瓶颈,或者因为某个节点下线而导致整个集群下线; -
集群中的主节点负责处理槽(存储数据),从节点则是主节点的复制品; - Redis集群将整个数据库分成16384个槽,数据库中的每个键都属于16384个槽中的其中一个;
- 集群中的每个主节点都可以负责0到16384个槽,当16384个槽都有节点在负责时,集群进入上线状态,可以执行客户端发送的数据命令;
-
主节点只会执行和自己负责的槽相关的命令,当节点接收到不属于自己处理的槽的命令时,它会将处理指定槽的节点的地址返回给客户端,而客户端会向正确的节点重新发送命令,这个过程称为“转向”; - Redis 集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
2.Redis 集群好处
Redis 集群提供了以下两个好处:
-
将数据自动切分(split)到多个节点的能力。 -
当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
为什么要有集群
之前我们已经讲了主从的概念,一主可以多从,如果同时的访问量过大(1000w),主服务肯定就会挂掉,数据服务就挂掉了或者发生自然灾难
大公司都会有很多的服务器(华东地区、华南地区、华中地区、华北地区、西北地区、西南地区、东北地区、台港澳地区机房)

3.redis集群
- 分类
- 软件层面
- 硬件层面
-
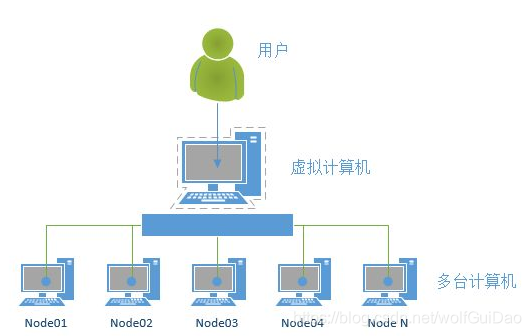
软件层面:只有一台电脑,在这一台电脑上启动了多个redis服务。

-
硬件层面:存在多台实体的电脑,每台电脑上都启动了一个redis或者多个redis服务。
4.实现机制
-
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。 -
集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。 -
一个Key到底属于哪个Slot由crc16(key)% 16384 决定。 -
关于集群成员管理,集群的节点(Redis Instance)和节点之间两两定期交换集群内节点信息并且更新,从发送节点的角度看,这些信息包括:集群内有哪些节点,IP和PORT是什么,节点名字是什么,节点的状态(比如OK,PFAIL,FAIL)是什么,包括节点角色(master或者 slave)等。 -
关于可用性,集群由N组主从Redis Instance组成。 - 主可以没有从,但是没有从 意味着主宕机后主负责的Slot读写服务不可用。
- 一个主可以有多个从,主宕机时,某个从会被提升为主,具体哪个从被提升为主,协议类似于Raft,参见这里。
- 如何检测主宕机?
Redis Cluster采用quorum+心跳的机制。 -
从节点的角度看,节点会定期给其他所有的节点发送Ping,cluster-node-timeout(可配置,秒级)时间内没有收到对方的回复,则单方面认为对端节点宕机,将该节点标为PFAIL状态。 - 通过节点之间交换信息收集到quorum个节点都认为这个节点为PFAIL,则将该节点标记为FAIL,并且将其发送给其他所有节点,其他所有节点收到后立即认为该节点宕机。
- 从这里可以看出,主宕机后,至少cluster-node-timeout时间内该主所负责的Slot的读写服务不可用。
5.依赖配置
Redis集群配置之前需要依赖一些相关库配置,因此需要先安装以下相关库;
- (1) 确保系统安装zlib,否则gem install会报(no such file to load – zlib)
# download:zlib-1.2.8.tar.gz
# tar –zxvfzlib-1.2. 8.tar.gz
# cd zlib-1.2.8
#./configure
# make
# makeinstall
- (2) 安装ruby:version(2.2.2)
# download:ruby-2.2.2.tar.gz
# tar –zxvf ruby-2.2.2.tar.gz
# cd /ruby-2.2.2
#./configure-prefix=/usr/local/ruby
# make
# makeinstall
# cp ruby/usr/local/bin
- 安装完成后可以查看相应的版本信息:
# ruby –v
- (3)安装rubygem:version(1.8.16)
# down rubygems-2.4.7.tar.gz
# tar –zxvf rubygems-2.4.7.tar.gz
# cd rubygems-2.4.7
# rubysetup.rb
# cp rubygems-2.4.7/bin/gem/usr/local/bin
- 安装完成后可以查看相应的版本信息:
# gem –v
- (4)安装redis与ruby接口gem-redis:version(3.0.6)
gem install -l /data/soft/redis-3.0.6.gem
6.集群配置
集群配置案例:
1.配置机器1
- 在演示中,172.16.179.130为当前ubuntu机器的ip
- 在172.16.179.130上进⼊Desktop⽬录,创建conf⽬录
- 在conf⽬录下创建⽂件7000.conf,编辑内容如下
port 7000
bind 172.16.179.130
daemonize yes
pidfile 7000.pid
cluster-enabled yes
cluster-config-file 7000_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7001.conf,编辑内容如下
port 7001
bind 172.16.179.130
daemonize yes
pidfile 7001.pid
cluster-enabled yes
cluster-config-file 7001_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7002.conf,编辑内容如下
port 7002
bind 172.16.179.130
daemonize yes
pidfile 7002.pid
cluster-enabled yes
cluster-config-file 7002_node.conf
cluster-node-timeout 15000
appendonly yes
总结:三个⽂件的配置区别在port、pidfile、cluster-config-file三项
-
使⽤配置⽂件启动redis服务
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf
查看进程如下图

2.配置机器2
- 在演示中,172.16.179.131为当前ubuntu机器的ip
- 在172.16.179.131上进⼊Desktop⽬录,创建conf⽬录
- 在conf⽬录下创建⽂件7003.conf,编辑内容如下
port 7003
bind 172.16.179.131
daemonize yes
pidfile 7003.pid
cluster-enabled yes
cluster-config-file 7003_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7004.conf,编辑内容如下
port 7004
bind 172.16.179.131
daemonize yes
pidfile 7004.pid
cluster-enabled yes
cluster-config-file 7004_node.conf
cluster-node-timeout 15000
appendonly yes
在conf⽬录下创建⽂件7005.conf,编辑内容如下
port 7005
bind 172.16.179.131
daemonize yes
pidfile 7005.pid
cluster-enabled yes
cluster-config-file 7005_node.conf
cluster-node-timeout 15000
appendonly yes
总结:三个⽂件的配置区别在port、pidfile、cluster-config-file三项
-
使⽤配置⽂件启动redis服务
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf
查看进程如下图

3.创建集群
- redis的安装包中包含了redis-trib.rb,⽤于创建集群
- 接下来的操作在172.16.179.130机器上进⾏
- 将命令复制,这样可以在任何⽬录下调⽤此命令
sudo cp /usr/share/doc/redis-tools/examples/redis-trib.rb /usr/local/bin/
- 安装ruby环境,因为redis-trib.rb是⽤ruby开发的
sudo apt-get install ruby
- 在提示信息处输⼊y,然后回⻋继续安装
- 运⾏如下命令创建集群
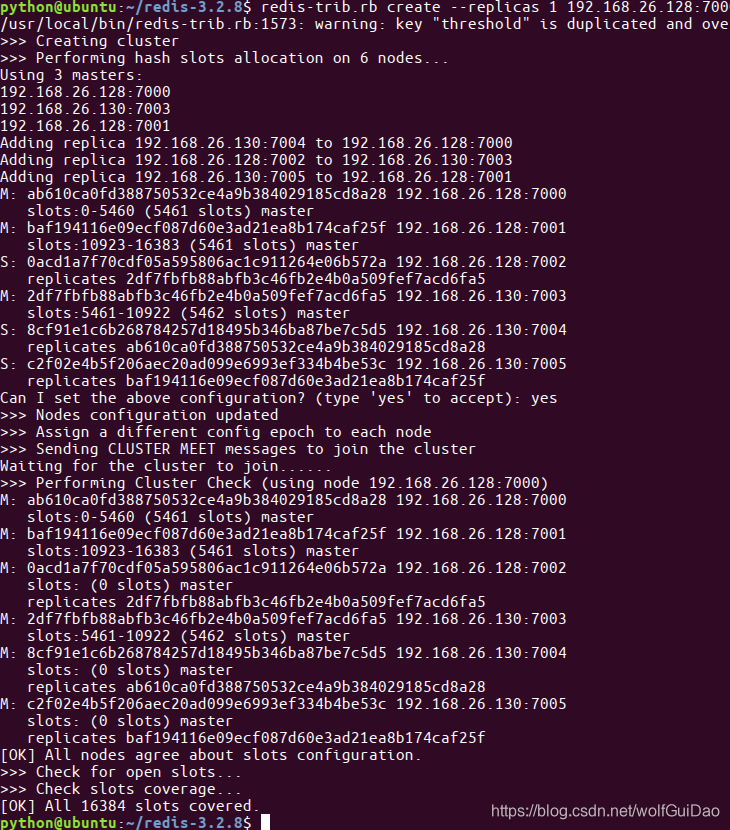
redis-trib.rb create --replicas 1 172.16.179.130:7000 172.16.179.130:7001 172.16.179.130:7002 172.16.179.131:7003 172.16.179.131:7004 172.16.179.131:7005
- 执⾏上⾯这个指令在某些机器上可能会报错,主要原因是由于安装的 ruby 不是最 新版本

- 天朝的防⽕墙导致⽆法下载最新版本,所以需要设置 gem 的源
解决办法如下
-- 先查看⾃⼰的 gem 源是什么地址
gem source -l -- 如果是https://rubygems.org/ 就需要更换
-- 更换指令为
gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
-- 通过 gem 安装 redis 的相关依赖
sudo gem install redis
-- 然后重新执⾏指令
redis-trib.rb create --replicas 1 172.16.179.130:7000 172.16.179.130:7001 172.16.179.130:7002 172.16.179.131:7003 172.16.179.131:7004 172.16.179.131:7005
- 提示如下主从信息,输⼊yes后回⻋
4.测试验证
[root@node01 src]# ./redis-cli -h 172.168.10.252 -p 7000
172.168.10.252:7000> get date
(nil)
172.168.10.252:7000> get aa
(nil)
172.168.10.252:7000> get name
(error) MOVED 5798 172.168.10.253:7000
172.168.10.252:7000>
-
目前主要的 Redis 集群客户端(或者说,支持集群功能的 Redis 客户端)有以下这些:
-
1、redis-rb-cluster:antirez 使用Ruby 编写的 Redis 集群客户端,集群客户端的官方实现;
-
2、predis:Redis的 PHP 客户端,支持集群功能;
-
3、jredis:Redis的 JAVA 客户端,支持集群功能;
-
4、StackExchange.Redis:Redis 的C# 客户端,支持集群功能;
-
5、内置的 redis-cli :在启动时给定 -c 参数即可进入集群模式,支持部分集群功能;
7.在哪个服务器上写数据:CRC16
- redis cluster在设计的时候,就考虑到了去中⼼化,去中间件,也就是说,
集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各⾃的数据和整个集 群的状态。 - 每个节点都和其他所有节点连接,⽽且这些连接保持活跃,这样就保 证了我们只需要连接集群中的任意⼀个节点,就可以获取到其他节点的数据
-
Redis集群没有并使⽤传统的⼀致性哈希来分配数据,⽽是采⽤另外⼀种叫做哈希 槽 (hash slot)的⽅式来分配的。 - redis cluster 默认分配了 16384 个slot,当我们 set⼀个key 时,会⽤CRC16算法来取模得到所属的slot,然后将这个key 分到哈 希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
- 所以我们在测试的 时候看到set 和 get 的时候,直接跳转到了7000端⼝的节点
Redis 集群会把数据存在⼀个 master 节点,然后在这个 master 和其对应的salve 之间进⾏数据同步。 - 当读取数据时,也根据⼀致性哈希算法到对应的 master 节 点获取数据。
-
只有当⼀个master 挂掉之后,才会启动⼀个对应的 salve 节点,充 当 master -
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存 活的主节点数⼩于总节点数的⼀半时,整个集群就⽆法提供服务了
8.Python交互
- 安装包如下
pip install redis-py-cluster
redis-py-cluster源码地址https://github.com/Grokzen/redis-py-cluster
- 创建⽂件redis_cluster.py,示例码如下
from rediscluster import *
if __name__ == '__main__':
try:
# 构建所有的节点,Redis会使⽤CRC16算法,将键和值写到某个节点上
startup_nodes = [
{'host': '192.168.26.128', 'port': '7000'},
{'host': '192.168.26.130', 'port': '7003'},
{'host': '192.168.26.128', 'port': '7001'},
]
# 构建StrictRedisCluster对象
src=StrictRedisCluster(startup_nodes=startup_nodes,decode_responses=True)
# 设置键为name、值为itheima的数据
result=src.set('name','itheima')
print(result)
# 获取键为name
name = src.get('name')
print(name)
except Exception as e:
print(e)
9.参考阅读
- redis集群搭建http://www.cnblogs.com/wuxl360/p/5920330.html
- [Python]搭建redis集群http://blog.5ibc.net/p/51020.html