Redis有四种集群模式,第一个就是主从模式,第二种“哨兵”模式,第三种是 Cluster 集群模式,第四种是单例模式,但是基本上只适用于自己练习。
接下来我们重点聊一聊前三种模式。
一、主从模式
1、主从复制概述

当其中一台服务器更新之后,服务器会自动的将这台更新的数据同步到另外一台服务器上。
通过持久化的功能,redis可以保证就算是服务宕机重启了,也只有少量的数据会丢失。但是在真实的使用场景当中,如果真的只有一台服务器,并且恰好宕机了,那么就会导致整个服务都不可用,因此redis提供了集群的方式来部署,可以避免这种问题。
在主从复制这种集群部署模式中,我们会将数据库分为两类,第一种称为主数据库(master),另一种称为从数据库(slave)。
主数据库会负责我们整个系统中的读写操作,从数据库会负责我们整个数据库中的读操作。
其中在职场开发中的真实情况是,我们会让主数据库只负责写操作,让从数据库只负责读操作,就是为了读写分离,减轻服务器的压力。
但是我在实际开发中会遇到一种情况,该数据是个热点数据,我们知道,数据同步一定是会耗时的,那么当一个热点数据进入master中,而slave没有来得及更新,再去读这个数据就会造成数据不一致现象,所以当时我的方案就是直接去读master节点,这个逻辑同样适用于mysql主从中出现的问题。
2、主从复制作用
1. 数据冗余,用于实现数据的热备份,属于一种数据冗余的实现方式。
2. 故障恢复,主节点出现问题,从节点提供服务,快速实现故障恢复,属于服务角度的冗余。
3. 负载均衡,进行读取的时候,通过多个主节点,多个从节点,实现Redis服务器的并发量得以提高。
4. 高可用,主从复制是实现哨兵和集群的基础。
3、主从同步原理
当一个从数据库启动时,它会向主数据库发送一个SYNC命令。master收到后,在后台保存快照,也就是我们说的RDB持久化,当然保存快照是需要消耗时间的,并且redis是单线程的(redis后面也支持了多线程,这里我们先不讲),在保存快照期间redis收到的命令会缓存起来,快照完成后会将缓存的命令以及快照一起打包发给slave节点,从而保证主从数据库的一致性。
从数据库接受到快照以及缓存的命令后会将这部分数据写入到硬盘上的临时文件当中,写入完成后会用这份文件去替换掉RDB快照文件,当然,这个操作是不会阻塞的,可以继续接收命令执行,具体原因其实就是fork了一个子进程,用子进程去完成了这些功能。
因为不会阻塞,所以,这部分初始化完成后,当主数据库执行了改变数据的命令后,会异步的给slave,这也就是我们说的复制同步阶段,这个阶段会贯穿在整个主从同步的过程中,直到主从同步结束后,复制同步才会终止。
上文提到的数据不一致的现象又是怎么回事呢?
是因为redis采用了乐观复制的策略,容忍一定时间内主从数据库的数据是不一致的,但是会保证最终的结果一致。
所以当主从复制发生时,正常情况下的命令都会在主数据库完成,然后直接反回给客户端,这样我们的性能就不会受到影响了,因为这里是主数据库先完成命令,那么就会产生其他问题。
举个例子,假如现在有1个master,6个slave,现在只有两个slave完成了同步,master写了新命令,在master准备将此命令传输给其他slave时,此刻其他的slave断电了,那么就会造成数据不一致的现象发生。
所以redis针对这种情况作了两个配置:
min-slaves-to-write 2 (只有2个及以上的从数据库连接到了主数据库时,master库才是可写的)min-slaves-max-lag 10 (10秒slave没有和master进行交互就认为丢失链接)4、无硬盘复制
我们刚刚说了主从之间是通过RDB快照来交互的,虽然看来逻辑很简单,但是还是会存在一些问题:
1. master禁用了RDB快照时,发生了主从同步(复制初始化)操作,也会生成RDB快照,但是之后如果master发成了重启,就会用RDB快照去恢复数据,这份数据可能已经很久了,中间就会丢失数据。
2. 在这种一主多从的结构中,master每次和slave同步数据都要进行一次快照,从而在硬盘中生成RDB文件,会影响性能。
为了解决这种问题,redis在后续的更新中也加入了无硬盘复制功能,也就是说直接通过网络发送给slave,避免了和硬盘交互,但是也是有io消耗的。
5、增量复制
刚刚我们说了复制的原理,但是他的缺点是很明显的,就是在断开主从链接后,即使你只发生了一条数据变化,也需要将所有的数据通过SYNC命令用RDB将所有的数据同步给slave,但是其实并不需要同步所有的数据,只需要将改变的这小部分数据同步给slave就好了。
所以为了解决这个问题,redis就有了增量复制。
这个原理其实是很简单的,学过kafka 的小伙伴应该知道,kafka消费是通过偏移量来计算的,redis的增量复制也是如此。
master会记下每个slave的id,在复制期间,如果有新消息,会将新消息(其实是新的命令,当然只包括让数据放生变动的命令,如 set 这种 )存放在一个固定大小的循环队列中,这个大小是可以配置的,当然这时候发送的就是PSYNC命令了,然后master会在复制完成后将这部分数据发送给slave,这样就在很大程度上保证了数据一致性。
二、哨兵模式
上文咱们说主从复制,在这种一主多从的结构中,我们让主从数据库做到了读写分离,也让从数据库能够完成数据备份的功能,可是也留下了一个比较严重的问题,当master挂了之后,只能由运维人员重新选择一个slave升级成master,然后继续提供服务。
想想一下,你国庆正放假,躺在三亚的海边沐浴着阳光,享受着香槟,突然你们boss给你来了个电话,说线上的master挂了,是不是会心里一句mmp???,所以,redis为了你考虑,在redis2.6版本中,他来了他来了--------哨兵模式。
1、哨兵
顾名思义,哨兵其实就是放哨的,它主要会有完成两个功能。
1. 监控整个主数据库和从数据库,观察它们是否正常运行
2. 当主数据库发生异常时,自动的将从数据库升级为主数据库,继续保证整个服务的稳定
哨兵其实是一个独立的进程,如下图:

当然,上图只是一个哨兵存在时的情况,但在现实中还会有两个,甚至更多哨兵存在的情况。

2、实现原理
当一个哨兵进程启动时,它会先通过配置文件,找我们的主数据库,当然,我们这里也只需要配置其监控的主数据库就好,之后哨兵会自动发现所有复制该主数据库的从数据库,当然一个哨兵是可以监控多个redis系统的,同时,多个哨兵也可以同时监控一个redis系统的。
哨兵进程启动后后会和master建立两条链接:
1. 用来获取其他同样在监控着此redis系统的哨兵信息;
2. 发送一个info命令来获取此redis系统master本身的信息;
当和master完成链接建立后,该哨兵就会定时的做以下三件事情:
1. 每10秒会向master和slave发送info命令;
2. 每2秒会向master和slave发送自己的信息;
3. 每1秒会向master,slave以及其他同样在监控着此redis系统的哨兵发送ping命令;
以上三个操作可是说是哨兵的核心了,下面就着重介绍一下这三个命令。
首先,info命令可以让哨兵获取到当前数据库的信息,比如运行id,复制信息等等,从而实现新节点的自动发现,从数据库的信息正是从info命令中获取的,获取从数据库信息后,就会和从数据库建立两条链接,和主数据库建立的链接是完全一样的,之后就会每10s向主从数据库发送info命令,当有新的从数据库加入时,就会从info命令中发现了,从而将这个新的slave加入自己的监控列表中。
当然如果有新的哨兵加入到了监控中,其他哨兵也是从这个info命令中获取的。
于此,就完成了对数据库以及其他哨兵的自动发现和监控,是不是很easy呢??
以上讲了自动发现数据库和其他的哨兵节点,之后哨兵就开始了它的工作,就是去监控这些数据库和节点有没有停止,哨兵就会每隔一段时间向这些节点发送PING命令,如果一段时间没有收到回复后,那么这个哨兵就会认为该节点已经挂了,我们将其称为主观下线。
如果该节点是master,哨兵就会向其他节点询问,看其他节点时候也认为该master挂了,我们可以认为他们在投票,当票数达到了一定的次数,那么哨兵就认为该节点真的挂了,我们成为客观下线,然后哨兵之间就会选举,选出一个领头的哨兵对主从数据库发起故障的修复。
3、哨兵选举过程
1. 第一个发现该master挂了的哨兵,向每个哨兵发送命令,让对方选举自己成为领头哨兵;
2. 其他哨兵如果没有选举过他人,就会将这一票投给第一个发现该master挂了的哨兵;
3. 第一个发现该master挂了的哨兵如果发现由超过一半哨兵投给自己,并且其数量也超过了设定的quoram参数,那么该哨兵就成了领头哨兵;
4. 如果多个哨兵同时参与这个选举,那么就会重复该过程,知道选出一个领头哨兵;
选出领头哨兵后,就开始了故障修复,会从选出一个从数据库作为新的master。
4、master选举过程
1. 从所有在线的从数据库中,选择优先级最高的从数据库;
2. 如果有多个优先级高的从数据库,那么就会判断其偏移量,选择偏移量最小的从数据库,这里的偏移量就是增量复制的;
3. 如果还是有相同条件的从数据库,就会选择运行id较小的从数据库升级为master;
三、cluster集群模式
在redis3.0版本中支持了cluster集群部署的方式,这种集群部署的方式能自动将数据进行分片,每个master上放一部分数据,提供了内置的高可用服务,即使某个master挂了,服务还可以正常地提供,我们先来看张图:
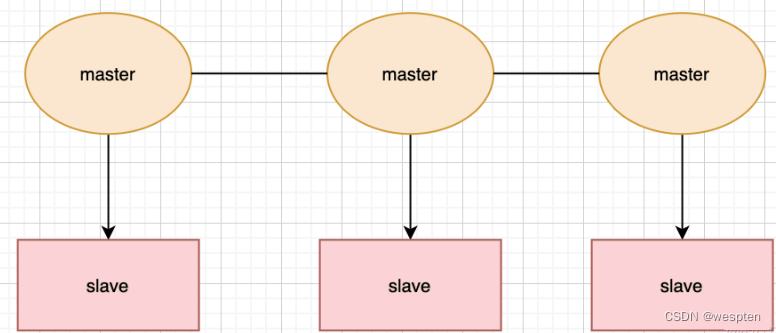
使用cluster集群模式,只需要将每个数据库节点的cluster-enabled配置选项打开即可,但是每个cluster集群至少要保证有3个主数据库才能正常运行。
1、cluster集群模式怎么存放数据的
一个cluster集群中总共有16384个节点,集群会将这16384个节点平均分配给每个节点,当然,我这里的节点指的是每个主节点,就如同下图:

2、键是如何和16384个插槽做关联的
redis将每个redis的键的键名有效部分使用CRC16算法计算出散列值,然后与16384取余数,这样的就可以使每个键能够尽量的均匀分布在16384个插槽中。
3、插槽是如何和节点做关联的
1. 插槽之前没有被分配过,现在想分配给指定节点;
2. 插槽之前被分配过,现在想移动指定节点;
第一种情况可以通过cluster add slot s 命令来实现。
第二种情况的原理相对麻烦一点,但是redis也提供的便捷的方式去操作,我们可以使用redis-trib.rb去实现。
4、如何获取与插槽对应的节点
当客户端向redis集群中的任意一个节点发送命令后,该节点都会判断当前键的信息是否存在于当前节点:
1. 如果存在,那么就会像单机的reids一样执行命令。
2. 如果不存在,就会返回一个move重定向请求,告诉客户端负责该数据的节点是哪一个,然后客户端会向该节点发送命令再次请求获取数据。
5、新节点的加入
需要通过cluster meet命令来实现:
cluster meet ip portip port 是我们已运行的redis集群中任意一个节点的地址和端口号,新节点在客户端输入命令后,会与命令中的节点进行握手,握手后,命令中的集群节点会将这个新节点的信息分享给集群中的每一个节点。
6、故障恢复
判断故障的逻辑其实与哨兵模式有点类似,在集群中,每个节点都会定期的向其他节点发送ping命令,通过有没有收到回复来判断其他节点是否已经下线。
如果长时间没有回复,那么发起ping命令的节点就会认为目标节点疑似下线,也可以和哨兵一样称作主观下线,当然也需要集群中一定数量的节点都认为该节点下线才可以,我们来说说具体过程:
1. 当A节点发现目标节点疑似下线,就会向集群中的其他节点散播消息,其他节点就会向目标节点发送命令,判断目标节点是否下线。
2. 如果集群中半数以上的节点都认为目标节点下线,就会对目标节点标记为下线,从而告诉其他节点,让目标节点在整个集群中都下线。
7、如何提高redis的读写能力
这个问题也是我们之前抛出来的问题,我们放一张图大家就会很容易明白了:

提高写能力只需要横向扩容master。
提高读能力只需要横向扩容slave。
四、Redis主从,单例,集群,哨兵配置
1、Redis主从配置
主从复制,是指把一台Redis服务器上的数据,复制到其余Redis服务器上。前者为主节点,后者为从节点。
1. 启动两个节点
这里通过更改配置文件的方式,修改监听的端口号,一个为6379,一个为6380,用于监听两个端口号。

启动两个节点,分别是6379和6380.默认启动都是主节点。
2. 建立复制
这里在6380节点执行复制命令,让其变成从节点。
![]()
3. 观察
这里主节点数据会复制到从节点中。
从节点查询一个不存在的key:
![]()
主节点增加这个key:
![]()
从节点再次查询,发现已经完成同步:
![]()
4. 断开复制
这里使用slaveof no one 进行复制的断开:

2、Redis单例配置
这里的单例,指的是Redis连接池的单例,这里举例的语言为Java,使用的连接池为JedisPool 通过 JedisPool 实现连接池的单例。
1)双锁机制
通过双重锁机制,实现redis的单例:
/**
* 双锁机制,安全且在多线程情况下能保持高性能
*/
public class JedisPoolDoubleCheck {
private static volatile JedisPool jedisPool = null;
private JedisPoolDoubleCheck(){}
public static JedisPool getRedisPoolUtil() {
if(null == jedisPool ){
synchronized (JedisPoolDoubleCheck.class){
if(null == jedisPool){
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(10);
poolConfig.setMaxWaitMillis(100*1000);
poolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool(poolConfig,"192.168.10.151",6379);
}
}
}
return jedisPool;
}
}2)classloader
通过类加载器,实现单例连接Redis:
/**
* 登记式/静态内部类
*
*/
public class JedisPoolInnerClass {
private JedisPoolInnerClass(){}
private static GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
static {
poolConfig.setMaxTotal(100);
poolConfig.setMaxIdle(10);
poolConfig.setMaxWaitMillis(100*1000);
poolConfig.setTestOnBorrow(true);
}
private static class JedisPoolHolder{
private static final JedisPool INSTANCE = new JedisPool(poolConfig,"192.168.10.151",6379);
}
public final static JedisPool getInstance(){
return JedisPoolHolder.INSTANCE;
}
}3、Redis集群配置
这里使用redis 提供的命令行,实现redis集群的搭建。
1. redis.conf 文件准备
redis server集群模式需要一些特殊的配置,下为参考:
port 7000 # server端口,6台server对应7000-7005。
# bind 127.0.0.1 //这一行要注释,否则无法远程连接
cluster-enabled yes
cluster-config-file nodes.conf //node.conf文件不用管。
cluster-node-timeout 5000
appendonly yes //aof
daemonize yes
protected-mode no准备六台sever的配置文件:
mkdir redis-cluster
cd redis-cluster
mkdir 7000 7001 7002 7003 7004 7005然后将redis.conf文件拷贝到 7000 到 7005 目录里面(每个redis.conf的只有端口不同)。
2. 启动服务器
对应每一个目录,启动一个服务器:
redis-server redis.conf到这里我们就有以集群模式启动的6台(端口7000-7005)redis server,但是每台服务器还没有进行slot指派,此时是不能对外提供服务的。
3. 搭建集群(slot指派)
下面的命令将7000-7005的六台服务器组成一个集群,其中复制因子为1所,以会有3台master,另外3台为slave。
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
16384个slot会尽可能均匀的指派给3台master,而3台slave异步的从其master进行复制。
4. 密码设置
通过redis-cli连接每一台server,然后设置密码:
config set masterauth [password]
config set requirepass [password]4、Redis哨兵配置
这里基于哨兵,实现redis的高可用。

1. redis.conf 配置
Master(192.168.50.100)机器配置如下:
#后台启动
daemonize yes
pidfile "/home/redis/redis/redisRun/redis_6379.pid"
port 6379
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/home/redis/redislog/redis.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
dir "/home/redis/redisdb"
#如果做故障切换,不论主从节点都要填写密码且要保持一致
masterauth "123456"
slave-serve-stale-data yes
slave-read-only yes
repl-disable-tcp-nodelay no
slave-priority 98
#当前redis密码
requirepass "123456"
appendonly yes
# appendfsync always
appendfsync everysec
# appendfsync no
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
# Generated by CONFIG REWRITESlave(192.168.50.101-103)机器配置如下:
daemonize yes
pidfile "/home/redis/redis/redisRun/redis_6379.pid"
port 6379
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/home/redis/redislog/redis.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
dir "/home/redis/redisdb"
#主节点密码
masterauth "123456"
slave-serve-stale-data yes
slave-read-only yes
repl-disable-tcp-nodelay no
slave-priority 98
requirepass "123456"
appendonly yes
# appendfsync always
appendfsync everysec
# appendfsync no
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
# Generated by CONFIG REWRITE
#配置主节点信息
slaveof 192.168.50.100 63792. 哨兵配置如下
Master(192.168.50.100)机器配置如下:
port 26379
#1表示在sentinel集群中只要有两个节点检测到redis主节点出故障就进行切换,单sentinel节点无效(自己测试发现的)
#如果3s内mymaster无响应,则认为mymaster宕机了
#如果10秒后,mysater仍没活过来,则启动failover
sentinel monitor mymaster 192.168.50.100 6379 1
sentinel down-after-milliseconds mymaster 3000
sentinel failover-timeout mymaster 10000
daemonize yes
#指定工作目录
dir "/home/redis/sentinel-work"
protected-mode no
logfile "/home/redis/sentinellog/sentinel.log"
#redis主节点密码
sentinel auth-pass mymaster 123456
# Generated by CONFIG REWRITESlave(192.168.50.100-102)机器配置同上。
3. 启动集群
启动192.168.50.100-103各机器Redis节点命令如下:
redis-server /home/redis/redis/redis.conf在192.168.50.100启动Redis哨兵节点命令如下:
redis-sentinel /home/redis/redis/sentinel.conf4. 启动后效果
哨兵节点,单节点效果:

多节点:

5. 登录Master(192.168.50.100)的redis查看Master的情况
执行登录命令如下:
redis-cli -h 192.168.50.100 -p 6379 -a 123456列出Master的信息:
info Replication
6. 登录Slave(192.168.50.101)的redis查看Slave的情况
执行登录命令如下:
redis-cli -h 192.168.50.101 -p 6379 -a 123456列出Slave的信息:
info Replication
7. 登录Slave(192.168.50.102)的redis查看Slave的情况
执行登录命令如下:
redis-cli -h 192.168.50.102 -p 6379 -a 123456列出Slave的信息:
info Replication
8. 登录Slave(192.168.50.103)的redis查看Slave的情况
执行登录命令如下:
redis-cli -h 192.168.50.103 -p 6379 -a 123456列出Slave的信息:
info Replication效果如图:
