- bigkey是指key对应的value所占的内存空间比较大
- 如果按照数据结构来细分的话,一般分为字符串类型和非字符串类型:
- 字符串类型:体现在单个value值很大,一般认为超过10KB就是bigkey,但这个值和具体的OPS相关。例如一个字符串类型的value可以最大存到512MB
- 非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。例如一个列表类型的value最多可以存储
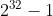 个元素
个元素
- bigkey无论是空间复杂度和时间复杂度都不太友好,下面我们将介绍它的危害
- 注意:因为非字符串数据结构中,每个元素实际上也是一个字符串,但这里只讨论元素个数过多的情况
一、bigkey的危害
- bigkey的危害体现在三个方面:
- 内存空间不均匀(平衡):例如在Redis Cluster中,bigkey会造成节点的内存空间使用不均匀
- 超时阻塞:由于Redis单线程的特性,操作bigkey比较耗时,也就意味着阻塞Redis可能性增大
- 网络拥塞:每次获取bigkey产生的网络流量较大,假设一个bigkey为1MB,每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例造成影响,其后果不堪设想。下图演示了网络带宽被bigkey占用的瞬间

- bigkey的存在并不是完全致命的:
- 如果这个bigkey存在但是几乎不被访问,那么只有内存空间不均匀的问题存在,相对于另外两个问题没有那么重 要紧急
- 但是如果bigkey是一个热点key(频繁访问),那么其带来的危害不可想象,所以在实际开发和运维时一定要密切关注bigkey的存在
二、bigkey的发现
redis-cli --bigkeys
- redis-cli--bigkeys可以命令统计bigkey的分布

debug object
- 但是在生产环境中,开发 和运维人员更希望自己可以定义bigkey的大小,而且更希望找到真正的bigkey都有哪些,这样才可以去定位、解决、优化问题
- 判断一个key是否为bigkey,只需要执行debug object key查看serializedlength属性即可,它表示key对应的value序列化之后的字节数
- 例如我们执行如下操作,可以发现serializedlength=11686193字节,约为1M,同时可以看到encoding是raw,也就是字符串类型

- 同时通过strlen来看一下字符串的字节数为2247394字节,约为2MB:

- serializedlength不代表真实的字节大小,它返回对象使用RDB编码序列化后的长度,值会偏小,但是对于排查bigkey有一定辅助作用,因为不是每种数据结构都有类似strlen这样的方法
- 在实际生产环境中发现bigkey的两种方式如下:
- 被动收集:许多开发人员确实可能对bigkey不了解或重视程度不够,但是这种bigkey一旦大量访问,很可能就会带来命令慢查询和网卡跑满问题, 开发人员通过对异常的分析通常能找到异常原因可能是bigkey,这种方式不太推荐,但是在实际生产环境中却大量存在,建议修改Redis客户端,当抛出异常时打印出所操作的key,方便排查bigkey问题
- 主动检测:scan+debug object:如果怀疑存在bigkey,可以使用scan命令渐进的扫描出所有的key,分别计算每个key的serializedlength,找到对应bigkey进行相应的处理和报警,这种方式是比较推荐的方式
- 开发提示:
- 如果键值个数比较多,scan+debug object会比较慢,可以利用Pipeline机制完成
- 对于元素个数较多的数据结构,debug object执行速度比较慢,存在阻塞Redis的可能
- 如果有从节点,可以考虑在从节点上执行
三、如何删除
- 当发现Redis中有bigkey并且确认要删除时,如何优雅地删除bigkey?
del命令性能分析
- 无论是什么数据结构,del命令都将其删除。但是相信通过上面的分析后你一 定不会这么做,因为删除bigkey通常来说会阻塞Redis服务。下面给出一组测试数据分别对string、hash、list、set、sorted set五种数据结构的bigkey进行删除,bigkey的元素个数和每个元素的大小不尽相同
- 下图展示了删除512KB~10MB的字符串类型数据所花费的时间,总体 来说由于字符串类型结构相对简单,删除速度比较快,但是随着value值的 不断增大,删除速度也逐渐变慢

- 下图展示了非字符串类型的数据结构在不同数量级、不同元素大小下 对bigkey执行del命令的时间,总体上看元素个数越多、元素越大,删除时间 越长,相对于字符串类型,这种删除速度已经足够可以阻塞Redis


- 从上分析可见,除了string类型,其他四种数据结构删除的速度有可能很慢,这样增大了阻塞Redis的可能性。既然不能用del命令,那有没有比较优雅的方式进行删除呢,这时候就需要前面文章介绍的scan命令的若干类似 命令拿出来:sscan、hscan、zscan
string类型的删除
- 对于string类型使用del命令一般不会产生阻塞:
del bigkey
hash、list、set、sorted set类型的删除
- 下面以hash为例子,使用hscan命令,每次获取部分(例如100个)field-value,再利用hdel删除每个field(为了快速可以使用Pipeline):
public void delBigHash(String bigKey) {
Jedis jedis = new Jedis(“127.0.0.1”, 6379);
// 游标
String cursor = “0”;
while (true) {
ScanResult<Map.Entry<String, String>> scanResult = jedis.hscan(bigKey, cursor,new ScanParams().count(100));
// 每次扫描后获取新的游标
cursor = scanResult.getStringCursor();
// 获取扫描结果
List<Entry<String, String>> list = scanResult.getResult();
if (list == null || list.size() == 0) {
continue;
}
String[] fields = getFieldsFrom(list);
// 删除多个field
jedis.hdel(bigKey, fields);
// 游标为0时停止
if (cursor.equals(“0”)) {
break;
}
}
// 最终删除key
jedis.del(bigKey);
}
/**
* 获取field数组
* @param list
* @return
*/
private String[] getFieldsFrom(List<Entry<String, String>> list) {
List<String> fields = new ArrayList<String>();
for(Entry<String, String> entry : list) {
fields.add(entry.getKey());
}
return fields.toArray(new String[fields.size()]);
}
- 开发提示:请勿忘记每次执行到最后执行del key操作
四、最佳实践思路
- 由于开发人员对Redis的理解程度不同,在实际开发中出现bigkey在所难免,重要的是,能通过合理的检测机制及时找到它们,进行处理
- 作为开发 人员在业务开发时应注意不能将Redis简单暴力的使用,应该在数据结构的选择和设计上更加合理,例如出现了bigkey,要思考一下可不可以做一些优化(例如拆分数据结构)尽量让这些bigkey消失在业务中
- 如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall)。最后,可喜的是,Redis在4.0版本支持lazy delete free的模式,那时删除bigkey不会阻塞Redis