黑塞矩阵是由目标函数![]() 在点X处的二阶偏导数组成的
在点X处的二阶偏导数组成的 ![]() 阶对称矩阵
阶对称矩阵
数据科学家需要了解的45个回归问题测试题(附答案)
1.L1与L2区别?L1为啥具有稀疏性?
L1是向量各元素的绝对值之和,L2是向量各元素的平方和
l1求导(弱导数)后,在x=0附近其系数相比l2的导数2x大,导致l1罚产生了主导作用,而l2罚的导数在0附近依然很小。
2.sigmoid函数的导函数的取值范围是多少?
y取值[0,1]
求导后,一元二次方程的y值范围,[0,1/4]

xgboost的原理
介绍xgboost、gbdt、rf的区别
最小二乘与极大似然函数的关系?
最小二乘法以估计值与观测值的差的平方和作为损失函数,极大似然法则是以最大化目标值的似然概率函数为目标函数,从概率统计的角度处理线性回归并在似然概率函数为高斯函数的假设下同最小二乘建立了的联系。
最大似然法需要已知概率分布函数,一般假设其满足正态分布函数的特性,在这种情况下,最大似然估计和最小二乘估计是等价的,也就是说估计结果是相同的
分类的评价标准
准确度accuracy,AUC,精确率-召回率(Precision-Recall),对数损失函数,F1-score等等
欠拟合的解决方法?
模型简单,加深神经网络,svm用核函数等等
L2正则的本质?
限制解空间范围,缩小解空间,控制模型复杂度
SVM引入核函数本质?
提高维度,增加模型复杂度
树模型的特征选择中除了信息增益、信息增益比、基尼指数这三个外,还有哪些?
得看树的类型吧?回归树的话可以用均方差的减少量。xgboost里用到的是自定义函数的增益值。
ID3算法采用信息增益
C4.5算法采用信息增益比
CART采用Gini系数
XGBoost

为什么LR损失函数要求平均
PCA输出百分比还是值
PCA输出什么
Sklearn中树模型输出的特征重要程度是本身的还是百分比?
百分比
size = 10000 np.random.seed(seed=10) X_seed = np.random.normal(0, 1, size) X0 = X_seed + np.random.normal(0, .1, size) X1 = X_seed + np.random.normal(0, .1, size) X2 = X_seed + np.random.normal(0, .1, size) X = np.array([X0, X1, X2]).T Y = X0 + X1 + X2 rf = RandomForestRegressor(n_estimators=20, max_features=2) rf.fit(X, Y); print "Scores for X0, X1, X2:", map(lambda x:round (x,3), rf.feature_importances_)
Scores for X0, X1, X2: [0.278, 0.66, 0.062]
当计算特征重要性时,可以看到X1的重要度比X2的重要度要高出10倍,但实际上他们真正的重要度是一样的。尽管数据量已经很大且没有噪音,且用了20棵树来做随机选择,但这个问题还是会存在。
需要注意的一点是,关联特征的打分存在不稳定的现象,这不仅仅是随机森林特有的,大多数基于模型的特征选择方法都存在这个问题。
Notes—Random Forest-feature importance随机森林对特征排序
结合Scikit-learn介绍几种常用的特征选择方法
PCA 提取的是数据分布方差比较大的方向,隐藏层可以提取有预测能力的特征
测试集和验证集的区别
生成模型与判别模型
判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
生成方法:由数据学习联合概率密度分布函数P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场
常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
最大似然估计和最小二乘法怎么理解?
最大似然估计:现在已经拿到了很多个样本(你的数据集中所有因变量),这些样本值已经实现,最大似然估计就是去找到那个(组)参数估计值,使得前面已经实现的样本值发生概率最大。因为你手头上的样本已经实现了,其发生概率最大才符合逻辑。这时是求样本所有观测的联合概率最大化,是个连乘积,只要取对数,就变成了线性加总。此时通过对参数求导数,并令一阶导数为零,就可以通过解方程(组),得到最大似然估计值。(利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。)
最小二乘:找到一个(组)估计值,使得实际值与估计值的距离最小。本来用两者差的绝对值汇总并使之最小是最理想的,但绝对值在数学上求最小值比较麻烦,因而替代做法是,找一个(组)估计值,使得实际值与估计值之差的平方加总之后的值最小,称为最小二乘。“二乘”的英文为least square,其实英文的字面意思是“平方最小”。这时,将这个差的平方的和式对参数求导数,并取一阶导数为零,就是OLSE。
ErrorBar(误差棒图)
是统计学中常用的图形。ErrorBar图涉及到数据的“平均值”和“标准差”。
下面举例子理解误差棒图中涉及到的“平均值”和“标准差”。
某地降雨量的误差棒图[1]如图1所示,从横纵1月份的刻度值往正上查找时,可发现1月份的降雨量对应于一个“工”字型的图案。该“工”字型的图案的中间的点对应的纵轴的刻度值(大约12),表示该地1月份的降雨量的“平均值”,大约12cm。而“工”字型图案的上横线或下横线所对应的纵轴的刻度值到中间点(即均值)的差值大约为0.5,表示该地1月份的降雨量的“标准差”大约为0.5cm。

数据挖掘和机器学习中如何在高维空间上观察模型的效果?
1) 每次可以选择每两三个维度,然后做plot.
2) 把数据映射到低维度再做观察 (PCA,LDA,MDS..etc)
KNN维度灾难
knn的基础是距离。维度灾难在使用距离的比较时问题尤甚。
会导致这个问题是因为,当维度增大时,距离某个样本点单位距离内的其他样本点数量的比值会减少,这会导致我们寻找更远的距离才能找到临近的值。
注意,虽然看起来对于knn选择的k个样本点并没有影响,但问题是选择的样本点随着维度的增高,距离该样本是越来越远的,因此没有那么有参考价值了。
这是维度灾难对于knn影响特别大的地方。
假设有一个特征,它的取值范围D在0到1之间均匀分布,并且对狗和猫来说其值都是唯一的,我们现在利用这个特征来设计分类器。如果我们的训练数据覆盖了取值范围的20%(e.g 0到0.2),那么所使用的训练数据就占总样本量的20%。上升到二维情况下,覆盖二维特征空间20%的面积,则需要在每个维度上取得45%的取值范围。在三维情况下,要覆盖特征空间20%的体积,则需要在每个维度上取得58%的取值范围...在维度接近一定程度时,要取得同样的训练样本数量,则几乎要在每个维度上取得接近100%的取值范围,或者增加总样本数量,但样本数量也总是有限的。
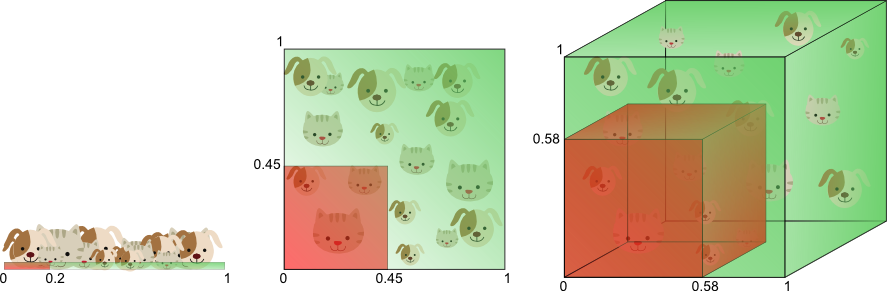
在分类中我们使用的特征数量越多,那么由于高维下数据的稀疏性我们不得不需要更多的训练数据来对分类器的参数进行估计(高维数下分类器参数的估计将变得更加困难)。维数灾难造成的另外一个影响是:数据的稀疏性致使数据的分布在空间上是不同(实际上,数据在高维空间的中心比在边缘区域具备更大的稀疏性,数据更倾向于分布在空间的边缘区域)。
能不能用简明的语言解释什么是非参数(nonparametric)模型?
简单来说就是不对样本的总体分布做假设,直接分析样本的一类统计分析方法。
通常对样本进行统计分析的时候,首先要假设他们来自某个分布,然后用样本中的数据去estimate这个分布对应的参数,之后再做一些test之类。比如你假设某个样本来自同一个正态分布,然后用样本数据估算和
,再用估算出来的这两个值做test。
non-pararmetric则不然,不对总体分布做假设,自然也就不必estimate相应的参数。
不同初值对算法有影响
感知机由于采用不同的初值或选取不同的误分类点,解可以不同。
kmeans的K值和K个初始类簇中心点对于聚类效果的好坏有很大的影响,不同的初始类簇中心点或不同的k值聚类的结果不同。
EM算法对初值敏感
Precision 和Recall
Min-Max Normalization和Z-score使用场景
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。
在不涉及距离度量、协方差计算、数据不符合正态分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
归一化与标准化本质是使得目标函数的Hessian矩阵的条件数变小,有更好的收敛性质了。
对条件数来个一句话总结:条件数 是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的 条件数在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是 ill-conditioned 的,如果一个系统是 ill-conditioned 的,它的输出结果就不要太相信了。
关于升维和降维
1、升维和降维有什么区别
降维是为了降低特征的复杂度,
升维是因为在低维空间无法有效分类,当映射到高维时却是可以进行好的分类
eg: 打个比方,你在两张纸上随机的画点,如果以纸的二维平面要把两张平面上的点分开,这个是很难分的
但是如果你增加一维,那么你直接就从两张纸的中间分开就行了
2、升维是不是也要考虑复杂度啊
是的,比如纸的这个问题,你升到四维就是多余的