1.为什么使用redis?
之前我们使用springBoot在做微服务的时候,我们发现了一个session共享问题,因为session是存在于服务端的,而服务器可能是集群的,那就意味着服务每次的调用,不一定在一个服务器上,那么session就无法保证存在于一个服务器上,从而导致session的丢失,为了处理这个问题,就可以使用redist来解决。
2.redis相关知识:
特性: redis存储的是nosql型数据,简单来说就是使用key-value的方式来储存数据。
客户端和服务端: redis的服务端启动后,就等待客户端连接,客户端有很多种类,比如java客户端
存储位置: redis存储数据的位置是在缓存上,这就意味着它的速度非常快,但是也有缺点,就是容量小。
数据格式: redis中的数据是用key-value的方式来储存的,value可以有如下格式:
string: 这个很简单,就不说了
hash: 双层map的结构,第一层存的是key-value,然后第一层的value中再存一个key-value格式的数据
双向list:数据结构中学过,key-value形式存储数据,其中value中存储l双向list,一个key对应一个双向list
set:key-value形式储存数据,一个key对应一个set,set中元素不重复,无序。
zst:和set相似,但是他是有序的,在元素的数据上绑定了一个
评分的数字(实际应用场景中,评分可以不同业务意义,例如点击次数,例如播放量,例如投票数量等)

3.使用java客户端连接redis
要使用Java客户端连接redis就需要引入依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
代码:
@Test
public void test(){
//第一个参数的redis服务器的ip地址,第二个是redis服务的端口号
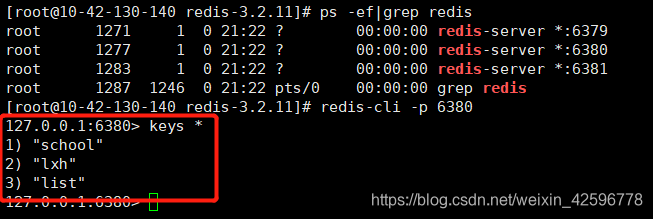
Jedis jedis=new Jedis("10.42.130.140",6380);
//调用set方法,再redis中添加一对key-value
jedis.set("lxh","23");
//hset方法,在hash中添加一个key为school,value为name-“河南工业大学”
jedis.hset("school","name","河南工业大学");
jedis.lpush("list","100","200");
}
问题的提出:java客户端可以连接上redis服务端,但是如果有多个redis服务端,我们只有保证用户每次访问的redis服务端都是同一个,才可以实现session那样的共享数据,那么如何保证用户每次访问的都是同一个redis?
4.分片计算——hash取余
当你的redis服务数量是确定的时候,可以使用此方法:
hash取余根据你的key值(redis中存储数据是以key-value形式),计算出一个值,把这个值映射到一个-21亿到+21亿的区间,接着把这个数取正,然后进行保真运算,最后%redis服务节点个数,得到的就是要使用第几个节点,代码如下:
@Test
public void test2(){
Jedis jedis1=new Jedis("10.42.130.140",6380);
Jedis jedis2=new Jedis("10.42.130.140",6381);
List<Jedis> list=new ArrayList<Jedis>();
list.add(jedis1);
list.add(jedis2);
for (int i=0;i<100;i++){
String key= UUID.randomUUID().toString();
String value=i+"";
//hash取余算法,得到一个下标,通过该下标去list中寻找需要的redis
int index=(key.hashCode()&Integer.MAX_VALUE)%list.size();
Jedis jedis=list.get(index);
jedis.set(key,value);
}
}
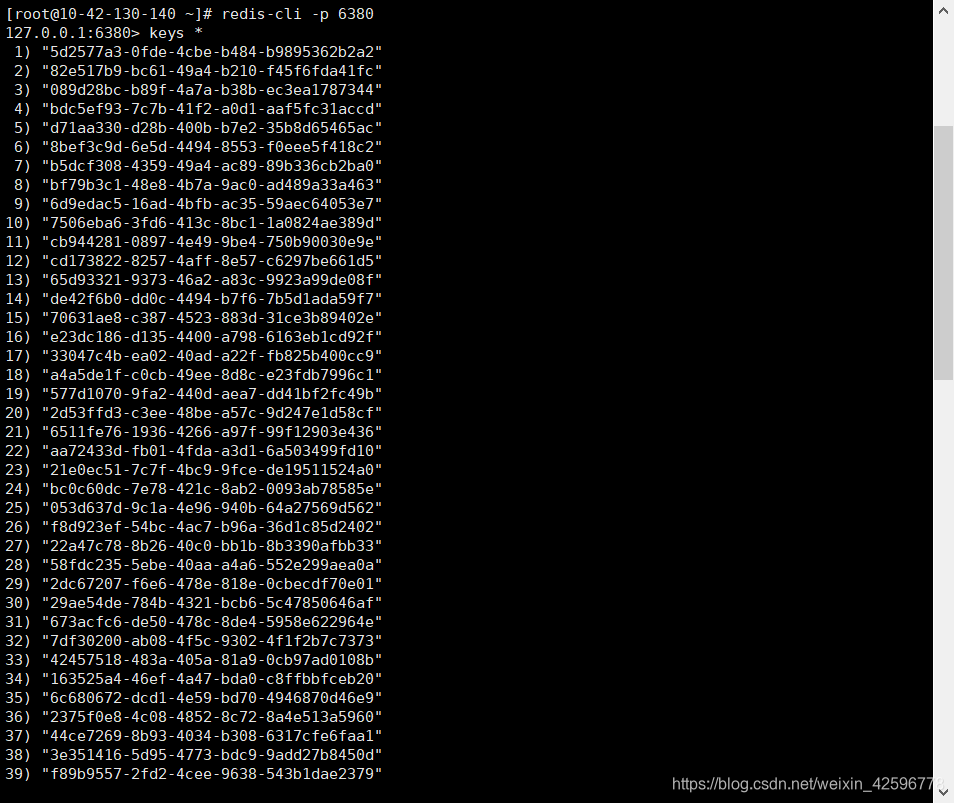
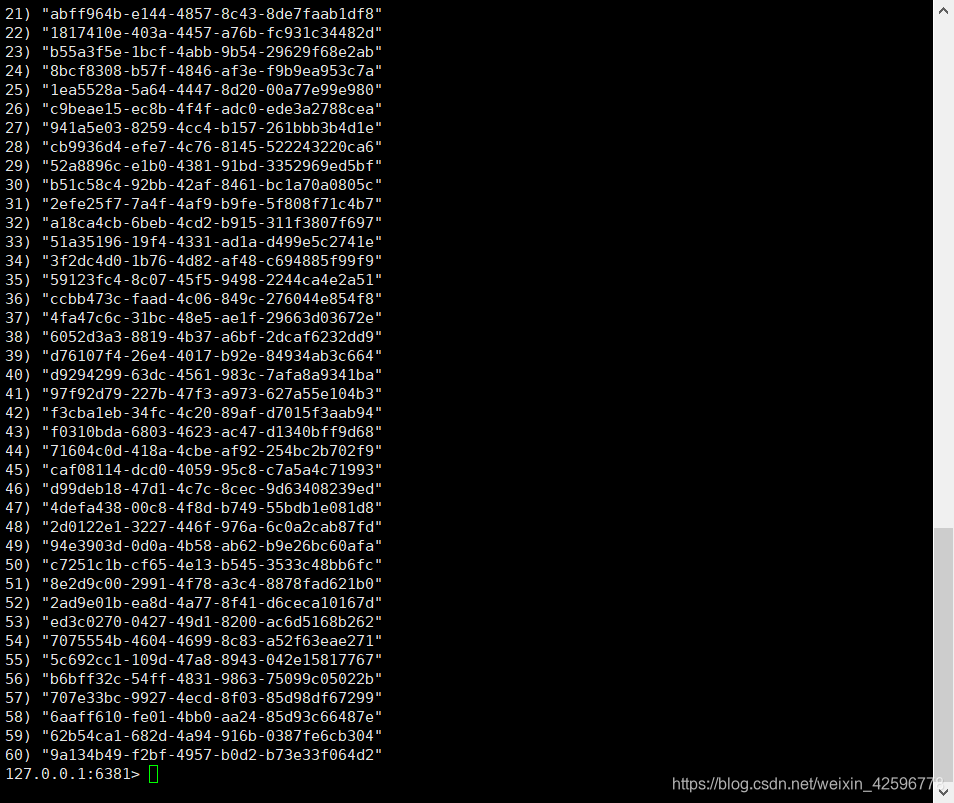
可以看到两个redis服务端中储存的数据分别是60条和40条。
5.分片计算—— 一致性hash
上面所说的hash取余算法,只能解决定长的redis服务问题,但是redis服务数量总是在变化的,一但数量发生了变化最后取余的误差就会非常大,导致java客户端通过key去寻找对应的redis服务时发生错误,所以为了解决这个问题,就出现了一致性hash。
算法思路:
首先需要一个hash环,0~43亿。
然后对节点做散列计算,让各个节点分散到这个环上。
再对key值做散列计算,把key也分散到这个环上。
接着就开始寻找,这些key会寻找离他们最近的节点,然后和这些节点对应上。
数据平衡性:
就比如刚刚上面那个案例,我启动了两个redis服务,把他们两个分散到这个hash环上,如果按照散列算法,必然会有一个节点承载的数据多于另外一个,那么如何解决这个问题?
jedis使用了虚拟节点技术,默认每个节点自带160个虚拟节点,这些虚拟节点和真实节点功能一样,为的就是去揽收那些离他们近的key散列。
代码如下:
@Test
public void test3(){
List<JedisShardInfo> list=new ArrayList<JedisShardInfo>();
list.add(new JedisShardInfo("10.42.130.140",6380));
list.add(new JedisShardInfo("10.42.130.140",6381));
//声明一个ShardedJedis的对象,把redis节点的链表传递进去,
//然后他就会把节点散列给安排好,key再进去的时候,就去找最近的节点即可
ShardedJedis jedis=new ShardedJedis(list);
for(int i=0;i<10;i++){
String key=UUID.randomUUID().toString();
String value=i+"";
jedis.set(key,value);
}
}