引入:
之前学习到了redis,我们学到了redis中的主从结构,哨兵集群,cluster结构,实现了redis的高可用和分布、集群。那么数据库的主从结构怎么实现高可用(一个不行了另外一个上),数据分片计算,读写分离?这就可以使用mycat来完成。
特点:
读写分离: 读写分离是建立在主从结构之上,让主节点去承载写操作,从节点承载读操作,这样做的目的就是可以分担主节点的压力,提升主从结构的整体效率。
垂直拆分: 简单来说就是mycat中的表(不同的表)可以来自于多个不同的服务器。
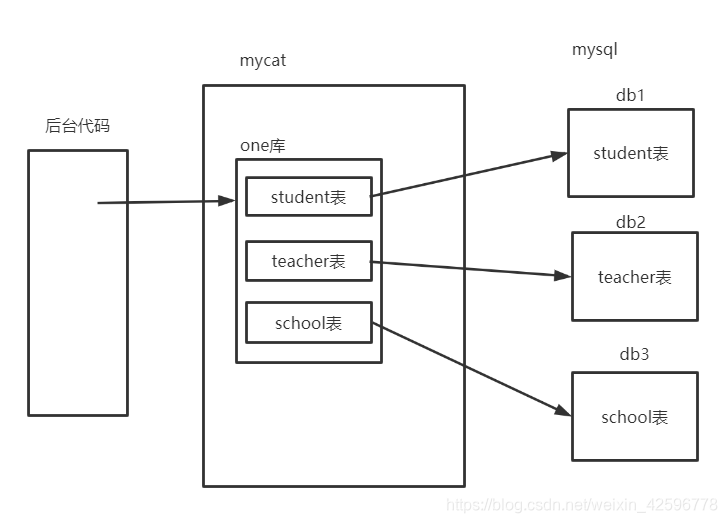
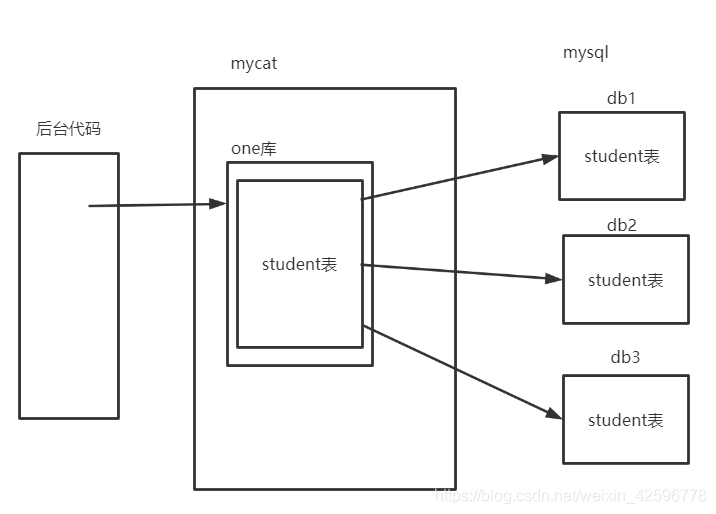
水平拆分: mycat中的表(一张表)来自于不同的服务器。
运行过程:
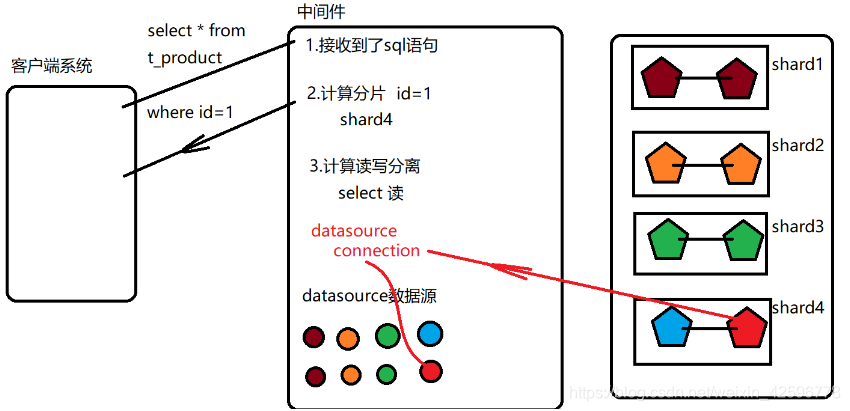
第一步:mycat启动时,就生成了管理连接后端真实数据库的所有datasource
第二步:客户端系统只能连接mycat发送sql语句
第三步:mycat接收到sql语句,执行各种计算,计算分片sql语句对应数据在哪个分片,计算读写分离,从这个分片主从结构中到哪个节点读/写,拿到了具体的数据源,获取连接发送sql语句
第四步:数据库拿到mycat执行的sql开始执行
第五步:mycat将数据库返回结果返回给客户端.
假死:
mycat中几乎没有这个问题,但是还是需要提醒一下,中间件的线程资源,在运行时占用满了,导致新的请求无法连接后端数据库(原因没有新的线程连接),中间件错误的判断是数据库宕机导致的。
mycat 的使用:
登录mycat:
第一种:是在linux下 执行mysql命令(mycat支持默认环境mysql)
添加一批完整的选项参数 用户名 密码 端口 mycat服务器ip地址
[root@10-9-48-69 ~]# mysql -utest -ptest -P8066 -h10.9.48.69。
第二种:sqlYog登录mycat ,只要在连接属性配置 ip username password port
mycat中的配置文件:
要想在mycat中使用真实的数据库,就需要使用配置文件,配置文件是server.xml(左)和schema.xml(右)

server.xml:
-
system:内容与mycat进程启动时占用的资源,内部配置属性有关
-
user:mycat登录的用户配置。权限配置等
name:用户名
password:用户密码
schemas:该用户可以访问的mycat中的数据库。可以访问多个数据库以
,隔开,必须是mycat中存在的库,如果有任何一个库不存在,将会报错。
quarantine:防火墙配置 -
whitehost:ip白名单
只有客户端ip地址在白名单范围内,才被允许访问mycat
只有客户端是从127.0.0.1的ip来访问mycat,并且使用mycat用户登录才能登录成功 -
blacklist:sql黑名单
在黑名单中列出的sql规则,都不可以使用。例如:drop不允许执行,没有where条件的delete不能执行。
schema.xml:
schema标签: 声明了server.xml中的数据库,其中使用的是table标签指明该数据库中的表(该表名真实库中必须存在)。
1.name:客户端可以看到和使用的数据库名称。sehema.xml中配置的多个schema标签,对应server.xml用户互配置标签中schemas属性。
2.checkSQLschema:可以配置true和false,表示所有sql语句是否需要添加表格的数据库名称。例如:表格 student,所在库 db1.配置fasle,sql发送到mycat,select * from student.不会拼接db1,但是如果是true,编程select * from db1.student.在mycat中存在多个库,多个表格,可以唯一定位表格的名称。
3.sqlMaxLimit:整数值,当sql语句做批量查询,mycat防止性能浪费,在判断sql语句语句中没有limit关键字自动拼接limit 0,100 查询前100条。
dataNode标签: 让table标签来使用,主要是起到一个桥梁作用,用来嫁接真实数据库和这个逻辑库,因为一个table标签中可以使用多个dataNode。
1.name:分片名称,按照配置顺序每个dataNode还有一个下标从0开始,可以做一致性hash计算。
2.dataHose: 一个分片不负责数据库集群的管理,只是绑定数据库集群管理对象dataHost,dataHost使用名字来绑定。
3.database:当前分片绑定真实数据库集群使用,真实数据库中database可能有多个,当前分片用的是哪个库(垂直划分),指定真实库名称
table标签:
1.name:表格名称,所有表格数据都一定来自真实库,表格名称要和真实库对应,并且同一个schema标签中只能存在唯一一个名称table
2.primaryKey:主键名称,对应表格的真实数据中的主键名字,默认是id,当不是id时,需要配置这个属性
3.dataNode:table表格数据,可以根据数据量大小,实现水平切分,对应的数据分片计算绑定dataNode标签,这里可以设置当前表格被切分到了几个数据分片中,可以对应一个分片,可以对应多个分片。
4.rule:当表格需要进行对应多个分片数据切分时,指定切分数据数据分片计算逻辑,可以给配置rule规则,例如:auto-sharding-long 整数范围约束,表示以主键某个字段的整数做分片计算,0-500万对应第一个分片,500万-1000万对应第二个分片,1000万-1500万对应第三个分片。字符串可以使用一致性hash sharding-by-murmur.
dataHost标签: 主要控制链接真实数据库,读写分离,故障转移。
1.name:当前dataHost的名字,绑定dataNode时使用
2.maxCon:当前dataHost管理的数据主从集群每个节点的连接池中最大连接
3.minCon:最小连接
4.balance:读写分离的读逻辑
单独控制一个主从结构的读写分离的读逻辑,想让balance值生效,writeType不能是1
0:默认值,不开启读的分离,只会在index=0的writeHost进行读
1:读的操作,除了index=0的writeHost,其他的所有Host都随机读.当读并发超级高时,所有后端是数据库读都承受很大压力时,第一个writeHost才会参与一部分读的分离.
2:随机在所有**Host进行读 3:随机在所有的ReadHost进行读,没有readHost时,只会在第一个writeHost进行读
5.writeType:读写分离的写逻辑
0:默认值,在index下标为0的writeHost数据库中写数据
1:1.5以上的mycat已经不推荐使用了,随机的在所有的writeHost进行写操作,覆盖balance的读逻辑,在所有**Host进行随机的读
6.dbType:默认mysql,数据库软件类型
7.dbDriver:默认mysql叫做native,如果是其他数据库给定driver全路径值
8.switchType:故障转移有关
1:默认值,当正在通过写功能的host(index=0的writeHost)故障,开启故障转移,将index=1的writeHost顶替(替换index下标).
-1:不开启故障转移
9.slaveThreshold:100是毫秒数,表示当前主从集群,从节点sql延迟100毫秒以上时,将不会使用该节点处理读数据逻辑
一个分片表案例:
server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<user name="root">
<property name="password">root</property>
<property name="schemas">TESTDB</property>
</user>
</mycat:server>
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/" >
<!--mycat only one logic database TESTDB-->
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!--tb_user-->
<table name="tb_student" primaryKey="id" dataNode="dn1,dn2"
rule="auto-sharding-long"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="mstest"/>
<dataNode name="dn2" dataHost="localhost2" database="mstest"/>
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="M1" url="10.9.48.69:3306"
user="root" password="root">
</writeHost>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="M1" url="10.9.151.60:3306"
user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>