第八章 模块
1.模块(moduel)概览
模块的概念
每一个模块(moduel)就对应于一个python源程序文件(以.py结尾的文本文件)。每一个以.py结尾的文本文件把.py后缀去掉之后的部分就得到了文件的文件名。每一个文件名就是一个模块的名字,每一个源程序文件,或者说一个模块都可以通过一下三种方式在另外一个源程序文件里被使用
#1.
import <moduel-name>
#把moduel-name之下的所有函数名,变量名等一次性全部导入另外一个程序内
#2.
from <moduel-name>import <variable-name>
#不想把模块内的所有东西导入,只导入想要使用的部分
#3.
imp.reload(<moduel-name>)
#在不终止执行当前python程序的情况下重新载入模块
使用模块的好处
代码重用
系统命名空间划分
导入模块时会给导入的变量名前面都加上前缀,前缀是变量所属于的模块的名字。例如当你把模块a内部的变量和对象导入之后所有的变量会由python自动加上a.形式以区别表示它是属于模块a的。
实现共享数据和服务
比如有一些和系统配置有关的变量,比如要连接数据库需要用户名,密码,远程数据库的地址,端口号。这些东西显然应该作为全局变量。一般的做法是把这些全局变量写在一个模块也就是是一个python源程序里面(你可以取名叫settings.py)。然后在凡是需要使用这些全局变量的地方import settings把包含全局变量的模块导入进去。通过这种方式实现全局变量在多个函数或者多个文件之间的共享
import如何工作
在Python中导入是程序运行时的运算。Python程序第一次导入指定文件(模块)时会找到模块文件并编译成bytecode以提高运行速度(需要时才做)。最后执行模块内的代码以创建其所定义的对象
注:上述三个步骤只在模块第一次被导入时才会执行。在导入一次之后如果再导入相同的模块会跳过上述三个步骤而只提取内存中已加载的模块对象。
Python会把已被导入的模块存储到一个叫sys.modules 的字典中。在导入操作的开始检查这个字典,如果模块不存在就会进行导入。如果模块已经存在就不重新执行此模块的代码,而只是从sys.modules中取出已创建的模块对象
示例:
在C盘根目录下有一个名为 simple.py 的Python源文件。我们在C盘根目录下启动Python交互环境,然后导入simple模块看一看 sys.modules。simple.py内只有print(‘hello’),spam=1两行代码

所谓的import实际上是把simple.py文件里的每一行都执行一遍,执行第一行的时候把hello打印一遍,执行第二行的时候在内存中创建一个值为1的对象,把名为spam的变量指向这个对象。模块名.变量名simple.spam查看该导入变量的值。
为了看sys.moduel必须要先引入python自带的sys模块。然后交互环境打印出sys底下名为moduels的对象,看最后一行可以看到刚刚导入的simple模块(模块名加从哪里被导入的)
模块导入的搜索路径
刚刚举的例子里simple.py被放在C盘根目录底下然后又在C盘根目录底下启动python交互环境。他自然会在C盘根目录底下找到simple.py。但是在更多的情况下源程序和启动交互环境不在同一个路径下。这时python怎么找py文件。
Python按如下顺序搜索路径:
1.程序当前目录(交互环境所运行的当前目录,如上面的例子交互环境在C盘内运行,它就会搜索C盘根目录看是否存在simple.py)
2.pythonpath目录(如果已经设置了的话)
注:pythonpath是可以手动设置的,虽然一般来说安装的时候会自动帮你设置,不需要手动设置。而且一般来说你也不应该手动去编辑
3.标准链接库目录
注:这也是python自带的,不需要手动设置。你的操作也不应该触碰到标准连接库
4.任何.pth文件中的内容(如果存在的话)
通过编辑.pth文件来告诉python在.pth文件指定的路径里面再搜索一下看是否存在需要的模块
查看搜索路径:
import sys;print(sys.path)
示例:

这就是老师电脑上显示出来的python搜索路径。可以看到显示为一个列表,列表里的第一个元素是一个空字符串指代当前目录,'C:\ \Python36\ \DLLs’就是标准链接库,'C:\ \Python36\ \lib’是类,'C:\ \python36’是python安装环境,'C:\ \Python36\ \lib\ \site-packages’python里第三方的包
.pth文件
可以在后缀名为 .pth 的文本文件中一行一行地列出有效的目录名。当内含目录名的后缀为 .pth 的文本文件被放置在适当的目录中时也可以起到pythonpath环境变量相同的功能
示例:
在Windows的C:\Python27目录下放一个名为:the-name-of-this-file-does-not-matter-but-the-suffix-pth-really-matters.pth的文本文件。内容是两个需要添加到搜索路径里的目录
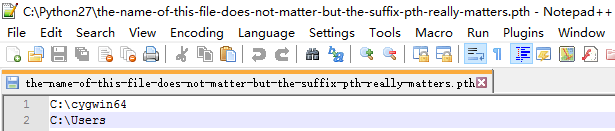
运行Python后就可以看到 sys.path 里增添了新内容

上文提到要把.pth文件放置在适当的目录中。不同的操作系统下.pth 文件的位置也不一样。可以在不同操作系统里运行如下代码让python来告诉你.pth应该被放置的位置
import site; site.getsitepackages()
比如以下示例在两种操作系统,三种不同python环境下运行这句话会得到不一样的结果

学用virtualenv
让你自己去官网上安装并学习使用
virtualenv是python的一个package,可以使用pip安装法安装。可以让你创建任意多个python的运行环境。多个不同运行环境可以装不同的package,同一个package的不同版本,而这是只有一个python运行环境无法做到的。在Docker容器技术出现之前,virtualenv是一个很常用的python工具,那时基本所有的python程序开发都不是在电脑上默认安装的python环境里做的,程序员对每一个python工程都至少创建一个virtualenv,然后把这个工程所依赖的全部package通过pip-install全部安装到它自己的vitualenv虚拟空间里。
它可以帮你把python的package管理好,最好为每一个python项目都维护一个独立的python开发环境,把每一个项目的package装到它们各自的virtualenv内。这样就不会出现package安装过多而显得杂乱的情况,主环境会整洁许多。
安装示例:

安装以后可以尝试去创建一个virtualenv,virtualenv这个虚拟环境里面有python完全的解释器。老师是在python3.8下安装的,这个虚拟环境内就有python3.8。当激活了虚拟环境之后就可以在里面装任意的python package而跟虚拟环境之外的package毫不冲突,这样就实现了在电脑中创建多个python环境
创建的过程自己去查官方文档,老师之前创建了一个名为pynenv的虚拟环境并放在pynenv文件夹内来演示用一用虚拟环境
为了使用虚拟环境你首先得进入它的目录底下,因为虚拟环境实质上也只不过是一个文件夹。dir命令用于显示当前文件夹下的目录文件

可以看到它有名为scripts的子文件夹,进入后使用activate命令创建的虚拟环境

激活后可以看到在windows的命令提示符前面出现虚拟环境的名字(或者说虚拟环境文件夹的名字,这两个实际上是一样的)

可以看见在虚拟环境中python是可以使用的,同时查看它底下已经安装的pip

对比虚拟环境之外安装的python3.8主环境(真实环境)内的安装的pip。可以发现二者不一样,通过这种方式把对于特定项目所需的package完全隔离起来而不会影响外部。这样也能实现在同一台电脑上安装不同版本的package。
虚拟环境删除也很方便,直接把文件夹删了就行
重新载入模块
前面已经提到过模块只会在第一次使用import或from … import时才被导入并执行。第二次以及其后的导入并不会重新执行此模块的代码而只是取出已创建的模块对象
示例:

要程序不终止运行的同时强制使模块代码重新载入并重新运行,就需要使用reload内置函数。 在Python 2.7中reload 是一个内置函数。在Python 3.6中它被移入了标准库模块imp中,使用要
from imp import reload
一般的用法是载入一个模块,再在文本编辑器内修改其源代码,然后使用 reload 将其重新载入。
示例:

注意示例中reload函数执行会返回一行东西,这是交互环境打印函数返回的对象信息提示这个函数为你返回了模块对象本身。也就是说reload函数是有返回值的,返回值为这个重新载入的名为simple的模块对象(moduel object)本身。这一行就是python默认的复杂对象的显示方式
模块包(package)
模块只不过是python的一个源程序文件,包则是包含源程序文件的目录。导入目录路径就被称作包导入
包导入
在 import 语句中列出路径名,不同层次间以点号相隔。使用点号把package的层次关系明确的告诉python,让python才能在层层相套的文件夹中找到你想要导入的moduel的位置,package的层次关系换句话说就是文件夹之间的包含关系。
import dir1.dir2.module
from … import … 语句也一样
from dir1.dir2.module import x
上面语句表明了机器上有个目录dir1,而dir1里有子目录dir2,dir2里包含一个名为module.py的文件。
此外,上面语句实际上还意味着目录dir1位于某个容器目录dir0中,这个容器目录 dir0 可以在Python模块搜索路径中找到,即:dir0/dir1/dir2/module.py
必不可少的__ init __.py 文件
如果要使用包导入,就必须多遵循一个规则:包导入语句的路径中的每个目录内都必须有一个名为
__ init __.py 的文件,否则包导入会失败
示例:
像这样的目录结构:dir0/dir1/dir2/module.py
以及这种形式的对应import语句:import dir1.dir2.module
其对应的目录结构应该是这样:

之所以要这样做,是因为:__ init __.py 文件可以防止有相同名称的目录不小心隐藏在模块搜索路径中,而之后才出现真正所需的模块文件。没有这种保护Python就有可能挑选出和程序代码无关的目录,只是因为有一个同名的目录刚好出现在搜索路径上位置较前的目录内
__ init __ .py 也是当导入一个包目录时所运行的代码所在的文件(当然__ init__.py 文件可以为空白,表示什么也不运行),它内部如果有python语句的话,当这个package第一次被导入的时候,它里面的语句就会被执行
示例:

左边是文件夹的组织形式,最外层的容器dir0可以保证被python找到,在python搜索路径内(在C盘的dir0目录底下打开交互环境,python导入的时候会先搜索当前路径,这样就能保证dir0能被python找到)。它下来有两层的package,每一层都有__ init __ .py。中间是各个__ init __.py的内容,包括你真正要导入的moduel内部也写有内容。观察输出,写入的东西都依次被执行了。然后在不中断程序的情况下再导入一次,什么都没有发生,因为仅仅在第一次导入的时候起作用。如果使用reload函数依次reload第一层,第二层以至第二层以下真正的模块文件,都返回对应模块的moduel。最后尝试访问x会报错,因为x也是在一个moduel里面,你要去访问x必须要把moduel的名字写在前面
__ init __ .py文件中的__ all __
第六章提到了以单个下划线开头(如 single_leading_underscore) 的变量名,在 from module import * 语句导入模块内变量时不会被导入
此外也可以在模块内的_ init __ .py文件中把变量名的字符串列表赋值给变量 __ all __ 。使用此功能时from module import * 语句只会把列在__ all__ 中的这些变量导入
示例:

利用 __ name __ 属性进行单元测试
在第一单元就详细介绍过,自己看课件和第一章笔记
模块设计理念
自己看课件
3.几点注意事项
使用as给载入的东西起个别名
import 语句和from … import …语句都可以通过在其末尾加上as …来重命名载入的东西。通过as起个别名在实践中经常遇到。例如numpy模块在使用时约定俗成地被写作 import numpy as np
示例:
#1.import语句
import modulename as name
#2.from … import …语句
from modulename import attrname as name
from … import … 复制变量,而不是连接到原模块
示例:
定义了模块 nested1.py。如果在另一个模块 nested2.py中使用from … import …导入两个变量x和printer,就会在导入者(nested2)中创建新变量,而不是到被导入模块中的两个变量的连接。所以在导入者nested2.py内修改变量,会改变该变量名在本地的绑定值,而不是nested1.py中的变量名。printer函数使用的是nested1.py里面的x
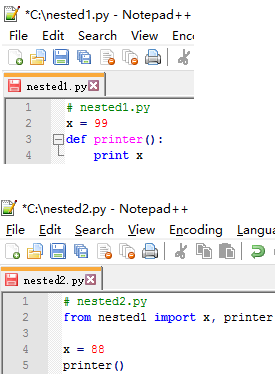

然而如果我们使用直接import导入从而获得了整个模块对象,然后赋值某个点号运算的变量就会修改 nested1.py 中的变量。可见点号运算定向到了被导入模块对象内的变量
示例:

当导入的是可变对象时情况变得有些微妙。可以对比以下两种情况

被导入的如果是列表这样的可变对象,无论是用from…import…还是import,通过下标索引的方式去该改变列表的值都会对原来被导入的nest1.py里的x产生影响
要解释这种现象就要考察from … import …语句的原理
from … import …究竟发生了什么?
示例:
from module import name1, name2 # copy these two names out only
实际上等价于
import module # fetch the module object
name1 = module.name1 # copy names out by ASSIGNMENT
name2 = module.name2
del module # get rid of the module object
现在来复习下之前讲的赋值操作对于不可变和可变对象的差别,就能理解上面几个示例的差异原理在于对不可变对象还是可变对象赋值。对于不可变对象,比如整数。让一个变量指向这个整数对象再对变量赋新值,会在内存中开辟新空间存储新值再把变量指向新值。如果是可变对象比如列表,以下面例子中a,b为例。a,b同样指向列表的首地址,通过下标索引方式改变列表第一个下标索引的值改为999并不会改变列表的首地址。a,b仍然指向同一个列表
>>>x=1
>>>y=x
>>>x=2
>>>y
1
>>>
>>>a=[0,1,2]
>>>b=a
>>>a[0]=999
>>>a
[999,1,2]
>>>b
[999,1,2]
通过 from … import … 导入的变量名就是对象的引用,而这个对象"恰巧"在被导入模块内由相同的变量名所引用。导入之后重新赋值,赋值就是再次的引用,而这个再次引用时python会故意把新的变量名取成和原来的变量名一样。这就给你一种假象好像把原来模块中的变量导入了,而实际上的情况是在被导入的空间内重新产生了变量,把新产生的变量赋上值导入模块内同名变量的值
慎用 from … import *
这是由上面的示例推出的技巧。具体内容自己看课件
顶层代码语句的次序问题
当模块被首次导入(或重新载入)时,Python会从头到尾执行模块文件里的语句。这时就有所谓前向引用(forward reference)的概念:
在导入时对于模块文件里顶层的程序代码(不在函数定义内和函数定义平级的代码),一旦运行到那一行就会被立刻执行。因此该语句是无法引用在文件后面位置才赋值的变量名的,因为执行的时候后面的代码还没有被生成
位于函数体内的代码直到函数被调用时才会被执行。由于函数内的变量名在函数实际执行前都不会被解析,通常可以引用文件内任意位置的变量
示例:

执行第一行的时候就会出错,因为func1()还没有被定义。第三行里面调用func2(),python执行到第四行的时候虽然func2()还没有被定义也没有问题。因为三四行现在仅仅时执行函数的定义而不是函数的调用。第六行再次调用func1()仍然会出错,因为当它真正执行fun1()的时候会发现func2()还没有被定义。
因此在程序顶层把定义和调用混在一起不仅难懂,也造成了程序对语句顺序的依赖。更好的办法是把函数的定义全部写在源文件的前面,函数的定义写完之后再在源文件尾部写上对函数的调用。既把函数的定义和调用分开,定义在前调用在后
终章
*也没怎么讲,自己看课件
What does pythonic mean?(that matters to us)
代码不仅仅要语法正确,能正确运行。还应该去遵循python开发界所公认的一些好的习惯。这就是pythonic。
Zen of Python
PEP8
PEP 8是Python的代码风格指南。
*pycodestyle是根据PEP 8中的一些样式约定检查Python代码的工具。
此在程序顶层把定义和调用混在一起不仅难懂,也造成了程序对语句顺序的依赖。更好的办法是把函数的定义全部写在源文件的前面,函数的定义写完之后再在源文件尾部写上对函数的调用。既把函数的定义和调用分开,定义在前调用在后
终章
*也没怎么讲,自己看课件
What does pythonic mean?(that matters to us)
代码不仅仅要语法正确,能正确运行。还应该去遵循python开发界所公认的一些好的习惯。这就是pythonic。
Zen of Python
PEP8
PEP 8是Python的代码风格指南。
*pycodestyle是根据PEP 8中的一些样式约定检查Python代码的工具。
编辑于2020-5-29 18:13