2020“东方国信杯”高校大数据开发大赛最终榜第三名思路分享
2020“东方国信杯”高校大数据开发大赛刚刚结束,我所在的队伍“三人运动团”最后取得了3/453 这个还算不错的成绩。感谢两位大佬队友的一路相伴!!下面我将分享一下我们本次比赛的一点思路!
写在前面:大家好!我是练习时长半年的在读本科生数据小白JerryX,各位数据挖掘大佬有什么问题和建议多多指教!!欢迎大家多多点赞,多多评论,多多批评指正!!
0 赛题背景

随着信息化浪潮的发展,我们即将迎来5G时代的浪潮,而中国也是5G通信时代的引领者。
去年十月,三大电信运营商共同宣布5G商用服务启动,发布相应的5G套餐,席卷全球的5G浪潮正式走进中国的千家万户。
5G使云服务进一步往边缘发展,越来越多的边缘算力将促进基于边缘计算的AI应用,更低的网络延时,
也使得终端和云对AI计算的分工更为灵活。无人驾驶、智能家居、工业物联将快速发展。
而对于通信运营商来说,如何基于 一些用户侧的信息进行用户画像,
再进一步对于潜在的5G使用者进行精准的推销也是非常有帮助的。
而这个也正是本次东方国信杯的比赛目标。
本次竞赛提供已经转向5G的用户以及尚未转向5G用户的各种数据,要求通过建模识别5G潜在用户。参赛者通过构建预测模型,预测待测试数据中用户在下个月是否会转化为5G用户。可以初步将本次比赛建模为一个结构化列表数据的二分类预测问题。本次比赛的评价指标为F1-score,为了优化这个目标评价函数,我们在后续的模型训练过程中要同时考虑召回率和准确率的权衡,同时我们也要考虑到如何最低化F1score的敏感性的对于预测结果的影响。

通过对于本次比赛数据集的简单探索性可视化分析,我们可以从左图中70W条的训练集数据的标签分布得知本次比赛的正负样本具有非常严重的不平衡问题,这是我们后续建模过程中需要考虑的问题。同时我们通过对于部分特征进行训练集测试集分布的可视化,可以发现训练集和测试集的分布一致性比较好,这就意味着在本次比赛中数据分布迁移并不是我们所要面临的问题。此外,我们通过对于训练集样本中的 正负样本的分布进行可视化,可以直观的看到其实正负样本在某些特征的分布上具有这一些显著的差异,这对于我们模型的准确分类奠定了良好的基础。
1 特征工程

我们在本次比赛中主要使用了以下的5类特征,包括原始的特征、我们基于人工经验构造的基于不同年龄和性别分组的组内行为的统计特征。一阶的统计特征:包括一些均值、百分位等特征。以及二阶的交叉特征和一些二阶的统计交叉特征。
在其中,一部分的特征我们是通过对于数据分布的观察分析、并结合实际业务和自己的经验进行构造;
另一部分的特征我们采用了Auto-ML的方法进行自动化的特征交叉构建与自动化的特征筛选。同时结合了人工构造特征的经验性和自动特征工程的高效便捷的特性。

在自动化特征构造部分,我们采用的部分特征的自动化构造方式如左图所示。 我们首先会将特征按照他们的属性:比如按照资费、APP软件资费使用量等类进行分组,这一点是考虑到一些特征的大类目间进行运算是不具有实际意义的,那么这样的特征即便在训练集上对于正负样本具有很好的区分意义,也会带来潜在很大的后续模型过拟合的风险。接着我们就会利用一些加减乘除的操作,对于特征对进行自动的特征构造,同时利用树模型对于每一轮构造出的特征的重要性进行排序,把前topK%的特征保留下来进一步作为我们的特征组。这个自动化构造的方法可以对于此类交叉特征的构造有着很好的帮助,兼具着普适性和高效性的特点。

这里所展示的是我们原始数据集上的特征重要性排名与我们构造完毕的特征集上的特征重要性排名,可以发现我们构造的很多新的交叉组合特征在新的模型中起到了比较重要的作用。
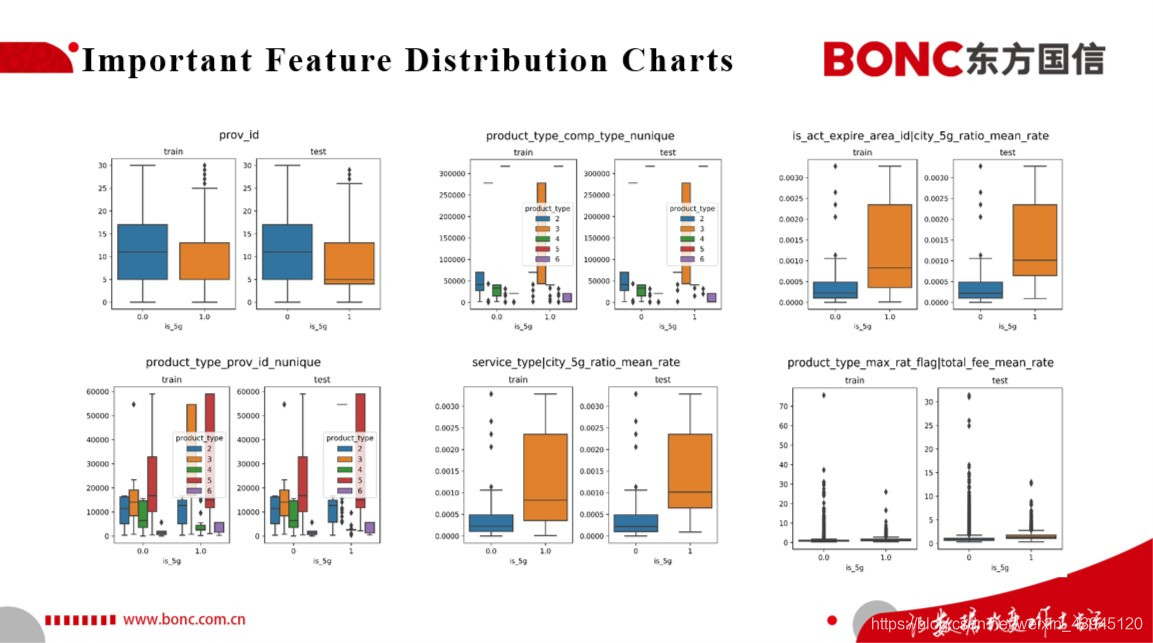
以上选取的是我们基于树模型进行特征重要性排序后得到的部分重要特征在正负样本上分布的箱式图, 可以看出我们基于树模型特征重要性排序得到的原始的重要特征与我们基于特征工程构造的高阶组合特征的正负样本分布都具有一定的差异性,这就表明我们可以基于这些我们构造的特征为后续潜在5G用户的识别从数据特征方面打下一个良好的基础。
2 模型策略
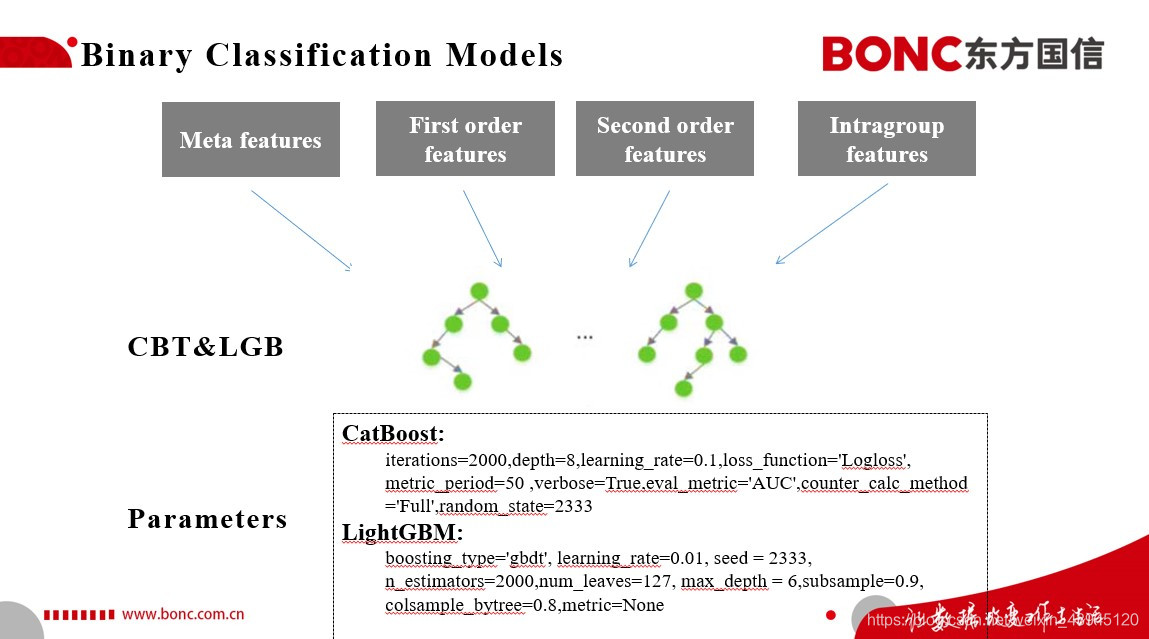
本次比赛我们考虑到实际业务对于可解释性的需求,便采用了一个非常简洁且高效的建模方法,就是结合Catboost和LightGBM来进行二分类的模型构建。 我们将我们前面特征工程构建的特征集喂给以上的两个模型,来对于测试集上的用户进行是否会在下个月转化为5G用户这个问题进行二分类。在模型参数上,我们并没有进行过多的调参,而是采用了5折的思路,尽可能地提高我们模型的鲁棒性。
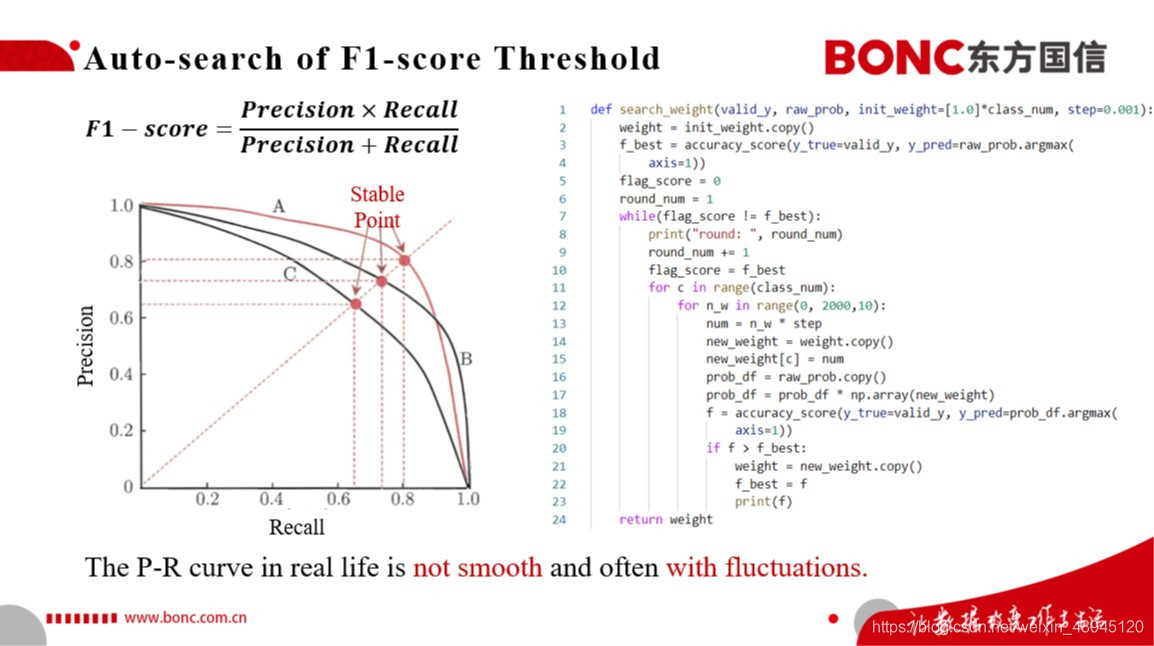
同时我们通过左图的Precision-Recall的P-R曲线中,可以得知这里的stable point便是我们所要求的F1-score的最大值所在点。但是实际模型P-R曲线的并不会像左图这样光滑,它是会带有很多的抖动的。那么我们就需要考虑结合训练集模型预测结果对于模型预测结果的阈值进行一定的阈值自动搜索,来得到一个好的阈值,以优化我们在测试集上的f1-score这一指标。
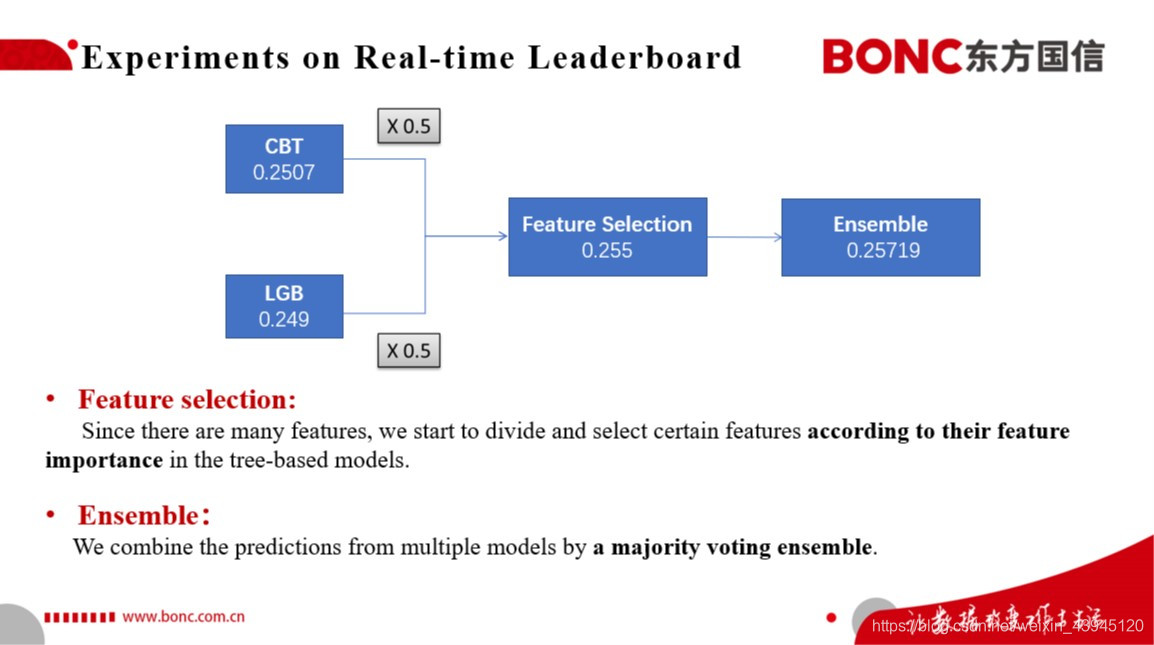
结合以上我们的建模思路,我们在实时榜上进行了一定的实验,我们最终考虑采用Catboost、LightGBM输出预测结果进行平均融合,并结合以上两个树模型进行特征的筛选和迭代训练。我们在实时榜上因而取得了0.255的最佳单模的成绩,同时在对于多个单模基于Majority Voting的Ensemble策略进行融合,得到了我们最终实时榜上的分数0.25719.

这里展示的是我们本次比赛的实时榜和最终榜上的得分和排名。我们在实时榜上取得了第五名的成绩,同时在最终榜上取得了第三名的好成绩。可以看出来我们的模型成绩在AB榜单上的表现是非常稳定的。进一步说明了我们整个特征选取和建模思路的鲁棒性。
3 结论&展望

我们最终的比赛解决方案总结如下:
首先,我们的特征工程充分利用了手工构造特征和自动化特征构造的优点。
其次,我们基于树模型对于特征重要性的排名,设计了一种鲁棒且高效的自动特征筛选策略,这使得我们后续模型的过拟合风险降到最低。
然后,就是在建模阶段,我们基于Catboost和LightGBM进行了二分类模型的构建,同时进行了majority voting ensemble,实现了一种简单而有效的方法。
最后,我们基于自动化的F1-score的搜索策略,尽可能地降低该指标敏感性对于模型预测结果的影响。
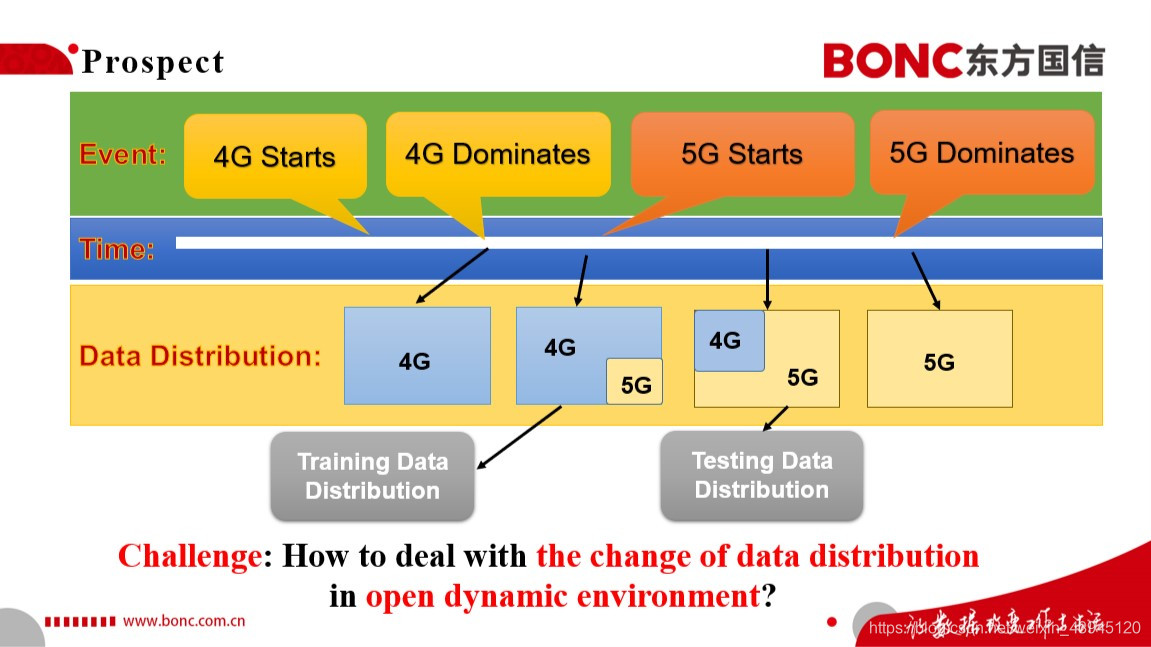
结合这次比赛和通讯技术的发展规律,我来讲讲对于5G潜在用户识别这一比赛的一点思考和展望。我们结合过去2G/3G/4G的发展,我们可以推断在经历了过去几年4G技术从兴起到主宰了,到现在5G技术的兴起,在不久的将来我们的社会也会经历从5G的兴起到5G主宰移动通讯方式的发展阶段。因此,我们可以想见的是,我们的潜在的5G用户的识别建模问题也会随着时间的演变,面临着训练集与测试集分布不一致的问题,也就是特征迁移与模型老化的问题。那么,如何去解决这样真实世界中开放动态的环境中数据分布变化的问题,就是我们要进一步思考的问题了,我想这对于实际的5G用户识别的线上实际部署将是一个非常大的挑战。

最后,我代表我们的团队,对于本次比赛的主办方东方国信公司的老师和图灵联邦竞赛平台的工作人员表达诚挚的感谢。感谢老师们过去培训阶段充满干货的课程,也感谢能够提供这样一次比赛机会,让我们深入去思考电信运营商所需要面临和解决的实际问题,同时更进一步的去思考在我们不久的未来,5G浪潮将给我们的生活方方面面所将带来的深远影响!