day05【迭代器,数据结构,List,Set ,TreeSet集合,Collections工具类】
主要内容
- Collection集合的遍历方式:
- 迭代器。
- foreach(增强for循环)
- JDK 1.8开始的新技术Lambda表达式。
- 数据结构
- 是集合的底层,研究数据结构是为了选择使用某种集合。
- List接口
- 元素是有序可重复有索引的。
- Set接口
- 元素是无序不重复无索引的。
- Collections是操作集合的工具类。
- 把学的集合用起来:斗地主的游戏。
教学目标
-
能够使用迭代器对集合进行取元素
-
java Iterator<String> it = names.iterator(); while(it.hasNext()){ String rs = it.next(); System.out.println(rs); } - 能够说出List集合特点
- 元素是有序,可重复的,有索引的,底层是基于数组存储元素的,查询快,增删慢!
-
-
能够说出常见的数据结构
- 队列: 先进先出
- 栈:先进后出,后进先出
- 数组:底层是连续内存区域,查询快,增删慢!
- 链表:元素是游离存储的,查询慢,首尾操作快!
- 红黑树 (HastSet ):增删改查都很好,可以排序,可以提高检索数据的性能!
-
能够说出数组结构特点
- 内存中的连续区域,每个区间大小固定,查询快,增删慢!
-
能够说出栈结构特点
- 先进后出。
-
能够说出队列结构特点
- 先进先出
-
能够说出单向链表结构特点
- 元素是游离存储的,查询慢, 一端的增删操作快!
-
能够说出Set集合的特点
- 元素是无序,不重复,无索引,底层是基于哈希表存储元素的,曾删查的性能都很好!!
-
能够说出哈希表的特点
- JDK 1.8之前是:链表+数组
- JDK 1.8之后是:链表+数组+红黑树
-
使用HashSet集合存储自定义元素
- Set sets = new HashSet<>();
第一章 Iterator迭代器
1.1 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
- 迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
接下来我们通过案例学习如何使用Iterator迭代集合中元素:
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
tips:
- 在进行集合元素获取时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会抛出java.util.NoSuchElementException没有集合元素异常。
- 在进行集合元素获取时,如果添加或移除集合中的元素 , 将无法继续迭代 , 将会抛出ConcurrentModificationException并发修改异常.
总结
迭代器的类型和集合的类型一致
可以理解成迭代器是集合的游标,每次next都会取集合的下一个位置
目标:Collection集合的遍历方式。
什么是遍历? 为什么开发中要遍历?
遍历就是一个一个的把容器中的元素访问一遍。
开发中经常要统计元素的总和,找最值,找出某个数据然后干掉等等业务都需要遍历。
Collection集合的遍历方式是全部集合都可以直接使用的,所以我们学习它。
Collection集合的遍历方式有三种:
(1)迭代器。
(2)foreach(增强for循环)。
(3)JDK 1.8开始之后的新技术Lambda表达式(了解)
a.迭代器遍历集合。
-- 方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的
E next():获取下一个元素值!
boolean hasNext():判断是否有下一个元素,有返回true ,反之。
--流程:
1.先获取当前集合的迭代器
Iterator<String> it = lists.iterator();
2.定义一个while循环,问一次取一次。
通过it.hasNext()询问是否有下一个元素,有就通过
it.next()取出下一个元素。
小结:
记住!
快速生成foreach变量的方法:数组或者集合对象.for 然后回车 就能快速生成

集合不能用for循环遍历,因为没有索引
目标:Collection集合的遍历方式。
什么是遍历? 为什么开发中要遍历?
遍历就是一个一个的把容器中的元素访问一遍。
开发中经常要统计元素的总和,找最值,找出某个数据然后干掉等等业务都需要遍历。
Collection集合的遍历方式是全部集合都可以直接使用的,所以我们学习它。
Collection集合的遍历方式有三种:
(1)迭代器。
(2)foreach(增强for循环)。
(3)JDK 1.8开始之后的新技术Lambda表达式。
b.foreach(增强for循环)遍历集合。
foreach是一种遍历形式,可以遍历集合或者数组。
foreach遍历集合实际上是迭代器遍历的简化写法。
foreach遍历的关键是记住格式:
for(被遍历集合或者数组中元素的类型 变量名称 : 被遍历集合或者数组){
}
小结:
foreach遍历集合或者数组很方便。
缺点:foreach遍历无法知道遍历到了哪个元素了,因为没有索引。
Collection集合的遍历方式有三种:
(1)迭代器。
(2)foreach(增强for循环)。
(3)JDK 1.8开始之后的新技术Lambda表达式。
c.JDK 1.8开始之后的新技术Lambda表达式。(暂时了解)
Collection<String> lists = new ArrayList<>();
lists.add("赵敏");
lists.add("小昭");
lists.add("殷素素");
lists.add("周芷若");
System.out.println(lists);
// [赵敏, 小昭, 殷素素, 周芷若]
// s
lists.forEach(s -> {//箭头语法 lambda表达式,可以简化代码
System.out.println(s);
});
// lists.forEach(s -> System.out.println(s));//可以简化代码
// lists.forEach(System.out::println);//更加简化代码
1.2 迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用t集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,为了让初学者能更好地理解迭代器的工作原理,接下来通过一个图例来演示Iterator对象迭代元素的过程:

在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
第二章 数据结构
2.1 数据结构介绍
数据结构 : 数据用什么样的方式组合在一起。
总结
数据结构:数据存储的常用结构
2.2 常见数据结构
数据存储的常用结构有:栈、队列、数组、链表和红黑树。我们分别来了解一下:
栈
- 栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
- 先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的子弹。
- 栈的入口、出口的都是栈的顶端位置。
这里两个名词需要注意:
- 压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
总结
栈就好比是瓶子里面装东西,瓶子满了,先出来的肯定是最后放进去的

队列
- 队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
- 先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
- 队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口。

数组
- 数组:Array,是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
查找元素快:通过索引,可以快速访问指定位置的元素

-
增删元素慢
-
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图

-
**指定索引位置删除元素:**需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图

总结
数组:
数组从0开始计数的原因可能是能够快速定位第n个位置的开头

数组增删慢,因为要扩容迁移元素,或者删除也要迁移元素
链表
-
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。

简单的说,采用该结构的集合,对元素的存取有如下的特点:
-
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
-
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
-
增删元素快:

总结

增删不用迁移元素,只要改变元素地址的指向就好
改动的地方多,速度就慢,改动的地方少,速度就快
目标:常见的数据结构种类。 集合是基于数据结构做出来的,不同的集合底层会采用不同的数据结构。 不同的数据结构,功能和作用是不一样的。 什么是数据结构? 数据结构指的是数据以什么方式组织在一起。 不同的数据结构,增删查的性能是不一样的。 不同的集合底层会采用不同的数据结构,我们要知道集合的底层是基于哪种数据结构存储和操作数据的。 这样才能知道具体场景用哪种集合。 Java常见的数据结构有哪些? 数据存储的常用结构有:栈、队列、数组、链表和红黑树 a.队列(queue) -- 先进先出,后进后出。 -- 场景:各种排队。叫号系统。 -- 有很多集合可以实现队列。 b.栈(stack) -- 后进先出,先进后出 -- 压栈 == 入栈 -- 弹栈 == 出栈 -- 场景:手枪的弹夹。 c.数组 -- 数组是内存中的连续存储区域。 -- 分成若干等分的小区域(每个区域大小是一样的) -- 元素存在索引 -- 特点:查询元素快(根据索引快速计算出元素的地址,然后立即去定位) 增删元素慢(创建新数组,迁移元素) d.链表 -- 元素不是内存中的连续区域存储。 -- 元素是游离存储的。每个元素会记录下个元素的地址。 -- 特点:查询元素慢 增删元素快(针对于首尾元素,速度极快,一般是双链表)
2.3. 树基本结构介绍
树具有的特点:
- 每一个节点有零个或者多个子节点
- 没有父节点的节点称之为根节点,一个树最多有一个根节点。
- 每一个非根节点有且只有一个父节点

| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素 |
| 节点的度 | 节点拥有的子树的个数,二叉树的度不大于2 |
| 叶子节点 | 度为0的节点,也称之为终端结点 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高 |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
二叉树
如果树中的每个节点的子节点的个数不超过2,那么该树就是一个二叉树。

二叉查找树/二叉排序树
二叉查找树的特点:
- 左子树上所有的节点的值均小于等于他的根节点的值
- 右子树上所有的节点值均大于或者等于他的根节点的值
- 每一个子节点最多有两个子树
案例演示(20,18,23,22,17,24,19)数据的存储过程;

增删改查的性能都很高!!!
遍历获取元素的时候可以按照"左中右"的顺序进行遍历;
注意:二叉查找树存在的问题:会出现"瘸子"的现象,影响查询效率。

总结
树的进化史

二叉查找树:如果数据是已经排序好,用二叉排序树会形成单边的情况,变成链表,使查找变得麻烦,使树变高
树是展示数据存储和数据获取的一种结构
平衡二叉树
(基于查找二叉树,但是让树不要太高,尽量让树的元素均衡分布。这样综合性能就高了)
概述
为了避免出现"瘸子"的现象,减少树的高度,提高我们的搜素效率,又存在一种树的结构:“平衡二叉树”
规则:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如下图所示:

如下图所示,左图是一棵平衡二叉树,根节点10,左右两子树的高度差是1,而右图,虽然根节点左右两子树高度差是0,但是右子树15的左右子树高度差为2,不符合定义,
所以右图不是一棵平衡二叉树。
总结
平衡二叉树就是对二叉排序树的瘸腿特性进行优化
左右两个子树的高度差的绝对值不超过1:

1与2的高度差不大于1(可以等于1),3与4的高度相等
旋转
在构建一棵平衡二叉树的过程中,当有新的节点要插入时,检查是否因插入后而破坏了树的平衡,如果是,则需要做旋转去改变树的结构。
左旋:
左旋就是将节点的右支往左拉,右子节点变成父节点,并把晋升之后多余的左子节点出让给降级节点的右子节点;

右旋:
将节点的左支往右拉,左子节点变成了父节点,并把晋升之后多余的右子节点出让给降级节点的左子节点

举个例子,像上图是否平衡二叉树的图里面,左图在没插入前"19"节点前,该树还是平衡二叉树,但是在插入"19"后,导致了"15"的左右子树失去了"平衡",
所以此时可以将"15"节点进行左旋,让"15"自身把节点出让给"17"作为"17"的左树,使得"17"节点左右子树平衡,而"15"节点没有子树,左右也平衡了。如下图,

由于在构建平衡二叉树的时候,当有新节点插入时,都会判断插入后时候平衡,这说明了插入新节点前,都是平衡的,也即高度差绝对值不会超过1。当新节点插入后,
有可能会有导致树不平衡,这时候就需要进行调整,而可能出现的情况就有4种,分别称作左左,左右,右左,右右。
左左
左左即为在原来平衡的二叉树上,在节点的左子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"10"节点的左子树"7",的左子树"4",插入了节点"5"或"3"导致失衡。

左左调整其实比较简单,只需要对节点进行右旋即可,如下图,对节点"10"进行右旋,


左右
左右即为在原来平衡的二叉树上,在节点的左子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的左子树"7",的右子树"9",
插入了节点"10"或"8"导致失衡。

左右的调整就不能像左左一样,进行一次旋转就完成调整。我们不妨先试着让左右像左左一样对"11"节点进行右旋,结果图如下,右图的二叉树依然不平衡,而右图就是接下来要
讲的右左,即左右跟右左互为镜像,左左跟右右也互为镜像。

左右这种情况,进行一次旋转是不能满足我们的条件的,正确的调整方式是,将左右进行第一次旋转,将左右先调整成左左,然后再对左左进行调整,从而使得二叉树平衡。
即先对上图的节点"7"进行左旋,使得二叉树变成了左左,之后再对"11"节点进行右旋,此时二叉树就调整完成,如下图:

右左
右左即为在原来平衡的二叉树上,在节点的右子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的右子树"15",的左子树"13",
插入了节点"12"或"14"导致失衡。

前面也说了,右左跟左右其实互为镜像,所以调整过程就反过来,先对节点"15"进行右旋,使得二叉树变成右右,之后再对"11"节点进行左旋,此时二叉树就调整完成,如下图:

右右
右右即为在原来平衡的二叉树上,在节点的右子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"11"节点的右子树"13",的左子树"15",插入了节点
"14"或"19"导致失衡。

右右只需对节点进行一次左旋即可调整平衡,如下图,对"11"节点进行左旋。

总结
右高(右树)往左旋,左高(左树)往右旋,把中间的节点提上去
不熟悉的东西先转为熟悉的东西,再用熟悉的东西的方法来进行解决
如果左高进行右旋,还是不平衡,就放弃右旋,改为左旋,然后不平衡再用右高往左旋,左高往右旋,把中间的节点提上去
要提的是,不平衡的父节点,谁高就往矮的地方旋
红黑树
就是平衡的二叉查找树!!
概述
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构,它是在1972年由Rudolf Bayer发明的,当时被称之为平衡二叉B树,后来,在1978年被
Leoj.Guibas和Robert Sedgewick修改为如今的"红黑树"。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,可以是红或者黑;
红黑树不是高度平衡的,它的平衡是通过"红黑树的特性"进行实现的;
红黑树的特性:
- 每一个节点或是红色的,或者是黑色的。
- 根节点必须是黑色
- 每个叶节点(Nil)是黑色的;(如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点)
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点;
如下图所示就是一个

在进行元素插入的时候,和之前一样; 每一次插入完毕以后,使用黑色规则进行校验,如果不满足红黑规则,就需要通过变色,左旋和右旋来调整树,使其满足红黑规则;
总结
红黑树就是红黑交替
e.红黑树
二叉树:binary tree 永远只有一个根节点,是每个结点不超过2个节点的树(tree) 。
查找二叉树,排序二叉树:小的左边,大的右边,但是可能树很高,性能变差。
为了做排序和搜索会进行左旋和右旋实现平衡查找二叉树,让树的高度差不大于1
红黑树(就是基于红黑规则实现了自平衡的排序二叉树):
树尽量的保证到了很矮小,但是又排好序了,性能最高的树。
红黑树的增删查改性能都好!!!
这些结构,其实Java早就通过代码实现了,我们要知道有这些结构即可!
第三章 List接口
我们掌握了Collection接口的使用后,再来看看Collection接口中的子类,他们都具备那些特性呢?
接下来,我们一起学习Collection中的常用几个子类(java.util.List集合、java.util.Set集合)。
3.1 List接口介绍
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。在List集合中允许出现重复的元素,所有的元素是以一种线性方式进行存储的,在程序中可以通过索引来访问集合中的指定元素。另外,List集合还有一个特点就是元素有序,即元素的存入顺序和取出顺序一致。
看完API,我们总结一下:
List接口特点:
- 它是一个元素存取有序的集合。例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
tips:我们在基础班的时候已经学习过List接口的子类java.util.ArrayList类,该类中的方法都是来自List中定义。
3.2 List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。public E get(int index):返回集合中指定位置的元素。public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
List集合特有的方法都是跟索引相关,我们在基础班都学习过。
tips:我们之前学习Colletion体系的时候,发现List集合下有很多集合,它们的存储结构不同,这样就导致了这些集合它们有各自的特点,供我们在不同的环境下使用,那么常见的数据结构有哪些呢?在下一章我们来介绍:
3.3 ArrayList集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意地使用ArrayList完成任何需求,并不严谨,这种用法是不提倡的。
总结
目标:ArrayList集合。
Collection集合的体系:
Collection<E>(接口)
/ \
Set<E>(接口) List<E>(接口)
/ \ / \ \
HashSet<E>(实现类) TreeSet<E>(实现类) LinkedList<E>(实现类) Vector(线程安全) ArrayList<E>(实现类)
/
LinkedHashSet<E>(实现类)
Collection集合体系的特点:
Set系列集合: 添加的元素,是无序,不重复,无索引的。
-- HashSet:添加的元素,是无序,不重复,无索引的。
-- LinkedHashSet:添加的元素,是有序,不重复,无索引的。
List系列集合:添加的元素,是有序,可重复,有索引的。
-- LinkedList: 添加的元素,是有序,可重复,有索引的。
-- ArrayList: 添加的元素,是有序,可重复,有索引的。
-- Vector 是线程安全的,速度慢,工作中很少使用。
List集合继承了Collection集合的全部功能,同时因为List系列集合有索引,
因为List集合多了索引,所以多了很多按照索引操作元素的功能:
ArrayList实现类集合底层基于数组存储数据的,查询快,增删慢!
- public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。
- public E get(int index):返回集合中指定位置的元素。
- public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。
- public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回更新前的元素值。
小结:
List系列集合有序,可重复,有索引的。
ArrayList实现类集合底层基于数组存储数据的,查询快,增删慢!!
开发中ArrayList集合用的最多!!
List集合的遍历方式扩展
总结
for循环是根据索引来进行遍历的
集合的长度为size
集合对象.get(索引)//可以用来去集合对象
快速创建迭代器对象:因为字符串变量无法接收迭代器,所以ide会报错,利用alt+enter,可以快速修复错误,从而快速创建迭代器对象

/**
拓展:List系列集合的遍历方式有:4种。
List系列集合多了索引,所以多了一种按照索引遍历集合的for循环。
List遍历方式:
(1)for循环。
(2)迭代器。
(3)foreach。
(4)JDK 1.8新技术。
*/
public class ListDemo02 {
public static void main(String[] args) {
List<String> lists = new ArrayList<>();
lists.add("java1");
lists.add("java2");
lists.add("java3");
/** (1)for循环。 */
for(int i = 0 ; i < lists.size() ; i++ ) {
String ele = lists.get(i);
System.out.println(ele);
}
System.out.println("-----------------------");
/** (2)迭代器。 */
Iterator<String> it = lists.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println("-----------------------");
/** (3)foreach。 */
for(String ele : lists){
System.out.println(ele);
}
System.out.println("-----------------------");
/** (4)JDK 1.8开始之后的Lambda表达式*/
lists.forEach(s -> {
System.out.println(s);
});
}
}
3.4 LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下
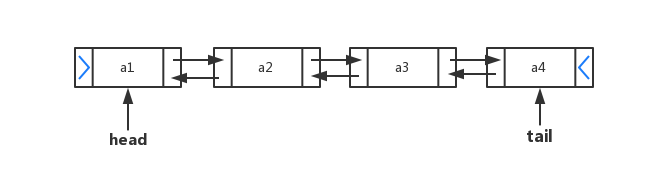
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
public void addFirst(E e):将指定元素插入此列表的开头。public void addLast(E e):将指定元素添加到此列表的结尾。public E getFirst():返回此列表的第一个元素。public E getLast():返回此列表的最后一个元素。public E removeFirst():移除并返回此列表的第一个元素。public E removeLast():移除并返回此列表的最后一个元素。public E pop():从此列表所表示的堆栈处弹出一个元素。public void push(E e):将元素推入此列表所表示的堆栈。public boolean isEmpty():如果列表不包含元素,则返回true。
LinkedList是List的子类,List中的方法LinkedList都是可以使用,这里就不做详细介绍,我们只需要了解LinkedList的特有方法即可。在开发时,LinkedList集合也可以作为堆栈,队列的结构使用。
public class Demo04LinkedList {
public static void main(String[] args) {
method4();
}
/*
* void push(E e): 压入。把元素添加到集合的第一个位置。
* E pop(): 弹出。把第一个元素删除,然后返回这个元素。
*/
public static void method4() {
//创建LinkedList对象
LinkedList<String> list = new LinkedList<>();
//添加元素
list.add("达尔文");
list.add("达芬奇");
list.add("达尔优");
System.out.println("list:" + list);
//调用push在集合的第一个位置添加元素
//list.push("爱迪生");
//System.out.println("list:" + list);//[爱迪生, 达尔文, 达芬奇, 达尔优]
//E pop(): 弹出。把第一个元素删除,然后返回这个元素。
String value = list.pop();
System.out.println("value:" + value);//达尔文
System.out.println("list:" + list);//[达芬奇,达尔优]
}
/*
* E removeFirst():删除第一个元素
* E removeLast():删除最后一个元素。
*/
public static void method3() {
//创建LinkedList对象
LinkedList<String> list = new LinkedList<>();
//添加元素
list.add("达尔文");
list.add("达芬奇");
list.add("达尔优");
//删除集合的第一个元素
// String value = list.removeFirst();
// System.out.println("value:" + value);//达尔文
// System.out.println("list:" + list);//[达芬奇,达尔优]
//删除最后一个元素
String value = list.removeLast();
System.out.println("value:" + value);//达尔优
System.out.println("list:" + list);//[达尔文, 达芬奇]
}
/*
* E getFirst(): 获取集合中的第一个元素
* E getLast(): 获取集合中的最后一个元素
*/
public static void method2() {
//创建LinkedList对象
LinkedList<String> list = new LinkedList<>();
//添加元素
list.add("达尔文");
list.add("达芬奇");
list.add("达尔优");
System.out.println("list:" + list);
//获取集合中的第一个元素
System.out.println("第一个元素是:" + list.getFirst());
//获取集合中的最后一个元素怒
System.out.println("最后一个元素是:" + list.getLast());
}
/*
* void addFirst(E e): 在集合的开头位置添加元素。
* void addLast(E e): 在集合的尾部添加元素。
*/
public static void method1() {
//创建LinkedList对象
LinkedList<String> list = new LinkedList<>();
//添加元素
list.add("达尔文");
list.add("达芬奇");
list.add("达尔优");
//打印这个集合
System.out.println("list:" + list);//[达尔文, 达芬奇, 达尔优]
//调用addFirst添加元素
list.addFirst("曹操");
System.out.println("list:" + list);//[曹操, 达尔文, 达芬奇, 达尔优]
//调用addLast方法添加元素
list.addLast("大乔");
System.out.println("list:" + list);//[曹操, 达尔文, 达芬奇, 达尔优, 大乔]
}
}
总结
如果要用子类的特殊功能就不能用多态来进行定义,因为用多态来进行定义,变量是父类类型的,就不能调用子类的特殊功能
队列是先进先出,后进后出
栈是先进后出,后进先出
LinkedList的push方法等同于addFirst方法
LinkedList的pop方法等同于removeFirst方法
目标:LinkedList集合。
Collection集合的体系:
Collection<E>(接口)
/ \
Set<E>(接口) List<E>(接口)
/ / \ \
HashSet<E>(实现类) LinkedList<E>(实现类) Vector(实现类) ArrayList<E>(实现类)
/
LinkedHashSet<E>(实现类)
Collection集合体系的特点:
Set系列集合: 添加的元素,是无序,不重复,无索引的。
-- HashSet:添加的元素,是无序,不重复,无索引的。
-- LinkedHashSet:添加的元素,是有序,不重复,无索引的。
List系列集合:添加的元素,是有序,可重复,有索引的。
-- LinkedList: 添加的元素,是有序,可重复,有索引的。
-- ArrayList: 添加的元素,是有序,可重复,有索引的。
LinkedList也是List的实现类:底层是基于链表的,增删比较快,查询慢!!
LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的
所以LinkedList除了拥有List集合的全部功能还多了很多操作首尾元素的特殊功能:
- public void addFirst(E e):将指定元素插入此列表的开头。
- public void addLast(E e):将指定元素添加到此列表的结尾。
- public E getFirst():返回此列表的第一个元素。
- public E getLast():返回此列表的最后一个元素。
- public E removeFirst():移除并返回此列表的第一个元素。
- public E removeLast():移除并返回此列表的最后一个元素。
- public E pop():从此列表所表示的堆栈处弹出一个元素。
- public void push(E e):将元素推入此列表所表示的堆栈。
小结:
LinkedList是支持双链表,定位前后的元素是非常快的,增删首尾的元素也是最快的。
所以提供了很多操作首尾元素的特殊API可以做栈和队列的实现。
如果查询多而增删少用ArrayList集合。(用的最多的)
如果查询少而增删首尾较多用LinkedList集合。
第四章 Set接口
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口都会以某种规则保证存入的元素不出现重复。
Set集合有多个子类,这里我们介绍其中的java.util.HashSet、java.util.LinkedHashSet、java.util.TreeSet这两个集合。
tips:Set集合取出元素的方式可以采用:迭代器、增强for。
4.1 HashSet集合介绍
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不能保证不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持,由于我们暂时还未学习,先做了解。
HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存储和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。
我们先来使用一下Set集合存储,看下现象,再进行原理的讲解:
public class HashSetDemo {
public static void main(String[] args) {
//创建 Set集合
HashSet<String> set = new HashSet<String>();
//添加元素
set.add(new String("cba"));
set.add("abc");
set.add("bac");
set.add("cba");
//遍历
for (String name : set) {
System.out.println(name);
}
}
}
输出结果如下,说明集合中不能存储重复元素:
cba
abc
bac
tips:根据结果我们发现字符串"cba"只存储了一个,也就是说重复的元素set集合不存储。
总结
目标:HashSet集合
Collection集合的体系:
Collection<E>(接口)
/ \
Set<E>(接口) List<E>(接口)
/ \ / \ \
HashSet<E>(实现类) TreeSet<E>(实现类) LinkedList<E>(实现类) Vector(线程安全) ArrayList<E>(实现类)
/
LinkedHashSet<E>(实现类)
Collection集合体系的特点:
Set系列集合: 添加的元素,是无序,不重复,无索引的。
-- HashSet:添加的元素,是无序,不重复,无索引的。
-- LinkedHashSet:添加的元素,是有序,不重复,无索引的。
-- TreeSet: 不重复,无索引,按照大小默认升序排序!! ( 可排序集合 )
List系列集合:添加的元素,是有序,可重复,有索引的。
-- LinkedList: 添加的元素,是有序,可重复,有索引的。底层是基于链表存储数据的,查询慢,增删快
-- ArrayList: 添加的元素,是有序,可重复,有索引的。底层基于数组存储数据的,查询快,增删慢
研究两个问题(面试热点):
1)Set集合添加的元素是不重复的,是如何去重复的?
2)Set集合元素无序的原因是什么?
4.2 HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用数组处理冲突,同一hash值的链表都存储在一个数组里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
看到这张图就有人要问了,这个是怎么存储的呢?
为了方便大家的理解我们结合一个存储流程图来说明一下:

总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
总结
引用数据类型就是自定义类型
泛型中包括引用数据类型
即便是对象中值相同,不同对象new出来的地址自然不同
4.3 HashSet存储自定义类型元素
给HashSet中存放自定义类型元素时,需要重写对象中的hashCode和equals方法,建立自己的比较方式,才能保证HashSet集合中的对象唯一.
创建自定义Student类:
public class Student {
private String name;
private int age;
//get/set
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
创建测试类:
public class HashSetDemo2 {
public static void main(String[] args) {
//创建集合对象 该集合中存储 Student类型对象
HashSet<Student> stuSet = new HashSet<Student>();
//存储
Student stu = new Student("于谦", 43);
stuSet.add(stu);
stuSet.add(new Student("郭德纲", 44));
stuSet.add(new Student("于谦", 43));
stuSet.add(new Student("郭麒麟", 23));
stuSet.add(stu);
for (Student stu2 : stuSet) {
System.out.println(stu2);
}
}
}
执行结果:
Student [name=郭德纲, age=44]
Student [name=于谦, age=43]
Student [name=郭麒麟, age=23]
总结
对象.hashCode() 可以获取对象的哈希值,相当于是内存地址
equals可以比较内容,返回true代表重复,如果返回false代表不重复
在空白处 右键 Generate 选择equals() and hashCode()就可以自定义判断list集合是否重复的方法

一直next 最后finish 即可
只要两个对象的内容一样,equals比较的结果一定为true
如果要认为内容一样,就代表重复,让list自动筛选重复元素,就选择equals() and hashCode(),重写hashCode()方法,令两个对象的内容一样返回的哈希值也要一样!true
两个对象内容一样,返回的入参就一样,哈希值就一样

目标:Set系列集合元素去重复的流程。
集合和泛型都只能支持引用数据类型。
1.对于有值特性的,Set集合可以直接判断进行去重复。
2.对于引用数据类型的类对象,Set集合是按照如下流程进行是否重复的判断。
Set集合会让两两对象,先调用自己的hashCode()方法得到彼此的哈希值(所谓的内存地址)
然后比较两个对象的哈希值是否相同,如果不相同则直接认为两个对象不重复。
如果哈希值相同,会继续让两个对象进行equals比较内容是否相同,如果相同认为真的重复了
如果不相同认为不重复。
Set集合会先让对象调用hashCode()方法获取两个对象的哈希值比较
/
false true
/
不重复 继续让两个对象进行equals比较
/
false true
/
不重复 重复了
需求:只要对象内容一样,就希望集合认为它们重复了。重写hashCode和equals方法。
小结:
如果希望Set集合认为两个对象只要内容一样就重复了,必须重写对象的hashCode和equals方法。
set集合无序的原因
总结
因为哈希值是随机的,所以取余的结果也是随机的
数组都是存对象地址

如果取余的结果相同,就设置链,让相同的位置的值指向这个值(就是链表)

为什么要用这种方法进行存储:因为哈希表的增删改查性能都很好
如果在取余的值的位置上的数组找不到目标值,就会找该位置的链表,一个一个查找
因为链表可能会略长,查询速度会比较慢,所以就引入红黑树机制,将链表转为红黑树,红黑树是以数值的大小进行排列,集合就用哈希值作为数值来匹配红黑树
哈希表的底层是基于Node数组,每个元素都是一个节点;每一个节点会存自己的哈希值,自己的元素值,存自己指向的下一个元素的地址

看底层源码可得,如果链表的长度大于等于8(从0开始,大于等于7),就转为红黑树
目标:Set系列集合元素无序的根本原因。(面试必考)
Set系列集合添加元素无序的根本原因是因为底层采用了哈希表存储元素。
JDK 1.8之前:哈希表 = 数组 + 链表 + (哈希算法)
JDK 1.8之后:哈希表 = 数组 + 链表 + 红黑树 + (哈希算法)
当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
小结:
Set系列集合是基于哈希表存储数据的
它的增删改查的性能都很好!!但是它是无序不重复的!如果不在意当然可以使用!
4.4 LinkedHashSet
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。
演示代码如下:
public class LinkedHashSetDemo {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<String>();
set.add("bbb");
set.add("aaa");
set.add("abc");
set.add("bbc");
Iterator<String> it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
结果:
bbb
aaa
abc
bbc
总结
有序指的是添加顺序
LinkedHashSet顾名思义就是在HashSet的基础上添加Linked(链)来记录添加的顺序

存数据依旧是按照set无序的方法存储,但是取元素的时候,是根据链表开始取
目标:LinkedHashSet
是HashSet的子类,元素是“有序” 不重复,无索引.
LinkedHashSet底层依然是使用哈希表存储元素的,
但是每个元素都额外带一个链来维护添加顺序!!
不光增删查快,还有序。缺点是多了一个存储顺序的链会占内存空间!!而且不允许重复,无索引。
总结:
如果希望元素可以重复,又有索引,查询要快用ArrayList集合。(用的最多)
如果希望元素可以重复,又有索引,增删要快要用LinkedList集合。(适合查询元素比较少的情况,经常要首尾操作元素的情况)
如果希望增删改查都很快,但是元素不重复以及无序无索引,那么用HashSet集合。
如果希望增删改查都很快且有序,但是元素不重复以及无索引,那么用LinkedHashSet集合。
4.5 TreeSet集合
1. 特点
TreeSet集合是Set接口的一个实现类,底层依赖于TreeMap,是一种基于红黑树的实现,其特点为:
- 元素唯一
- 元素没有索引
- 使用元素的自然顺序对元素进行排序,或者根据创建 TreeSet 时提供的
Comparator比较器
进行排序,具体取决于使用的构造方法:
public TreeSet(): 根据其元素的自然排序进行排序
public TreeSet(Comparator<E> comparator): 根据指定的比较器进行排序
2. 演示
案例演示自然排序(20,18,23,22,17,24,19):
public static void main(String[] args) {
//无参构造,默认使用元素的自然顺序进行排序
TreeSet<Integer> set = new TreeSet<Integer>();
set.add(20);
set.add(18);
set.add(23);
set.add(22);
set.add(17);
set.add(24);
set.add(19);
System.out.println(set);
}
控制台的输出结果为:
[17, 18, 19, 20, 22, 23, 24]
案例演示比较器排序(20,18,23,22,17,24,19):
public static void main(String[] args) {
//有参构造,传入比较器,使用比较器对元素进行排序
TreeSet<Integer> set = new TreeSet<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//元素前 - 元素后 : 升序
//元素后 - 元素前 : 降序
return o2 - o1;
}
});
set.add(20);
set.add(18);
set.add(23);
set.add(22);
set.add(17);
set.add(24);
set.add(19);
System.out.println(set);
}
控制台的输出结果为:
[24, 23, 22, 20, 19, 18, 17]
总结
多态的优点就是右边的实现类可以多样变化
有序是添加顺序,排序是大小顺序
目标:TreeSet集合。
TreeSet: 不重复,无索引,按照大小默认升序排序!!
TreeSet集合称为排序不重复集合,可以对元素进行默认的升序排序。
TreeSet集合自自排序的方式:
1.有值特性的元素直接可以升序排序。(浮点型,整型)
2.字符串类型的元素会按照首字符的编号排序。
3.对于自定义的引用数据类型,TreeSet默认无法排序,执行的时候直接报错,因为人家不知道排序规则。
自定义的引用数据类型的排序实现:
对于自定义的引用数据类型,TreeSet默认无法排序
所以我们需要定制排序的大小规则,程序员定义大小规则的方案有2种:
a.直接为对象的类实现比较器规则接口Comparable,重写比较方法(拓展方式)

public class Employee implements Comparable<Employee>{
private String name;
private double salary;
private int age;
// 重写了比较方法。
// e1.compareTo(o)
// 比较者:this
// 被比较者:o
// 需求:按照年龄比较
@Override
public int compareTo(Employee o) {
// 规则:Java规则
// 如果程序员认为比较者大于被比较者 返回正数!
// 如果程序员认为比较者小于被比较者 返回负数!
// 如果程序员认为比较者等于被比较者 返回0!
if(this.age > o.age){
return 1;
}else if(this.age < o.age){
return -1;
}
return 0;
上面比较也可简化成一行代码:return this.age - o.age;//升序,直接返回两者差的结果
顺着扣是升序,如果反着扣就是降序,例return o.age - this.age就是降序
b.直接为集合设置比较器Comparator对象,重写比较方法
Set<Employee> employees1 = new TreeSet<>(new Comparator<Employee>() {
@Override
public int compare(Employee o1, Employee o2) {
// o1比较者 o2被比较者
// 如果程序员认为比较者大于被比较者 返回正数!
// 如果程序员认为比较者小于被比较者 返回负数!
// 如果程序员认为比较者等于被比较者 返回0!
return o1.getAge() - o2.getAge();
}
});
employees1.add(new Employee("播仔",6500.0,21));
employees1.add(new Employee("播妞",7500.0,19));
employees1.add(new Employee("乔治",4500.0,23));
System.out.println(employees1);
}
}
在集合中创建匿名内部类来进行比较,比较规则相同
注意:如果类和集合都带有比较规则,优先使用集合自带的比较规则。
小结:
TreeSet集合对自定义引用数据类型排序,默认无法进行。
但是有两种方式可以让程序员定义大小规则:
a.直接为对象的类实现比较器规则接口Comparable,重写比较方法(拓展方式)
b.直接为集合设置比较器Comparator对象,重写比较方法
注意:如果类和集合都带有比较规则,优先使用集合自带的比较规则。
第五章 Collections类
5.1 Collections常用功能
-
java.utils.Collections是集合工具类,用来对集合进行操作。常用方法如下:
-
public static void shuffle(List<?> list):打乱集合顺序。 -
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。 -
public static <T> void sort(List<T> list,Comparator<? super T> ):将集合中元素按照指定规则排序。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(100);
list.add(300);
list.add(200);
list.add(50);
//排序方法
Collections.sort(list);
System.out.println(list);
}
}
结果:
[50,100, 200, 300]
我们的集合按照默认的自然顺序进行了排列,如果想要指定顺序那该怎么办呢?
总结
// 1.给集合批量添加元素
Collection<String> names = new ArrayList<>();
/**
* 参数一:被添加元素的集合
* 参数二:可变参数,一批元素
*/
Collections.addAll(names,"曹操","贾乃亮","王宝强","陈羽凡");
System.out.println(names);
5.2 Comparator比较器
创建一个学生类,存储到ArrayList集合中完成指定排序操作。
Student 类
public class Student{
private String name;
private int age;
//构造方法
//get/set
//toString
}
测试类:
public class Demo {
public static void main(String[] args) {
// 创建四个学生对象 存储到集合中
ArrayList<Student> list = new ArrayList<Student>();
list.add(new Student("rose",18));
list.add(new Student("jack",16));
list.add(new Student("abc",20));
Collections.sort(list, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge()-o2.getAge();//以学生的年龄升序
}
});
for (Student student : list) {
System.out.println(student);
}
}
}
Student{name='jack', age=16}
Student{name='rose', age=18}
Student{name='abc', age=20}
总结
b.直接为集合设置比较器Comparator对象,重写比较方法
// 如果程序员认为比较者大于被比较者 返回正数!
// 如果程序员认为比较者小于被比较者 返回负数!
// 如果程序员认为比较者等于被比较者 返回0!
注意:如果类和集合都带有比较规则,优先使用集合自带的比较规则。
5.3 可变参数
在JDK1.5之后,如果我们定义一个方法需要接受多个参数,并且多个参数类型一致,我们可以对其简化.
格式:
修饰符 返回值类型 方法名(参数类型... 形参名){ }
代码演示:
public class ChangeArgs {
public static void main(String[] args) {
int sum = getSum(6, 7, 2, 12, 2121);
System.out.println(sum);
}
public static int getSum(int... arr) {
int sum = 0;
for (int a : arr) {
sum += a;
}
return sum;
}
}
注意:
1.一个方法只能有一个可变参数
2.如果方法中有多个参数,可变参数要放到最后。
应用场景: Collections
在Collections中也提供了添加一些元素方法:
public static <T> boolean addAll(Collection<T> c, T... elements):往集合中添加一些元素。
代码演示:
public class CollectionsDemo {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
//原来写法
//list.add(12);
//list.add(14);
//list.add(15);
//list.add(1000);
//采用工具类 完成 往集合中添加元素
Collections.addAll(list, 5, 222, 1,2);
System.out.println(list);
}
总结
目标:可变参数。
可变参数用在形参中可以接收多个数据。
可变参数的格式:数据类型... 参数名称
可变参数的作用:
传输参数非常灵活,方便。
可以不传输参数。
可以传输一个参数。
可以传输多个参数。
可以传输一个数组。
可变参数在方法内部本质上就是一个数组。
可变参数的注意事项:
1.一个形参列表中可变参数只能有一个!!
2.可变参数必须放在形参列表的最后面!!
小结:
可变参数的作用:传输参数非常灵活,方便。
可变参数的注意事项:
1.一个形参列表中可变参数只能有一个!!
2.可变参数必须放在形参列表的最后面!!
第六章 集合综合案例
6.1 案例介绍
按照斗地主的规则,完成洗牌发牌的动作。
具体规则:
使用54张牌打乱顺序,三个玩家参与游戏,三人交替摸牌,每人17张牌,最后三张留作底牌。
6.2 案例分析
-
准备牌:
牌可以设计为一个ArrayList,每个字符串为一张牌。
每张牌由花色数字两部分组成,我们可以使用花色集合与数字集合嵌套迭代完成每张牌的组装。
牌由Collections类的shuffle方法进行随机排序。 -
发牌
将每个人以及底牌设计为ArrayList,将最后3张牌直接存放于底牌,剩余牌通过对3取模依次发牌。
-
看牌
直接打印每个集合。
6.3 代码实现
- Poker.java
public class Poker {
private String name;
public Poker() {
}
public Poker(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "{" + name + "}";
}
}
2 测试类
public class Demo12 {
public static void main(String[] args) {
// 创建一个ArrayList用于存放一副牌
ArrayList<Poker> pokers = new ArrayList<>();
pokers.add(new Poker("大王", ""));
pokers.add(new Poker("小王", ""));
String[] colors = new String[] {"♠", "♥", "♣", "♦"};
String[] numbers = new String[] {"2", "A", "K", "Q", "J", "10", "9", "8", "7", "6", "5", "4", "3"};
// 组合牌, 嵌套循环的流程:外循环一次,内循环所有次
// 2.使用嵌套循环生成一副牌
for (String n : numbers) {
// "2", "A"
for (String c : colors) {
// "♠", "♥", "♣", "♦"
Poker p = new Poker(c, n);
// 3.将54张牌放到集合
pokers.add(p);
}
}
// 打印
// System.out.println(pokers);
// 洗牌: Collections,集合工具类
// static void shuffle(List<?> list) 将集合中元素的顺序打乱
Collections.shuffle(pokers);
System.out.println("洗牌后:" + pokers);
// 发牌
// 1.创建3个玩家集合,创建底牌集合
ArrayList<Poker> player01 = new ArrayList<>();
ArrayList<Poker> player02 = new ArrayList<>();
ArrayList<Poker> player03 = new ArrayList<>();
ArrayList<Poker> diPai = new ArrayList<>();
// 2.遍历牌的集合
// 0 1 2 3 4 5 6 7 8 9 10 ...51 52 53
// pokers = [♦5], [♣4], [♦8], [♣A], [♣7], [♦2], [♠6], [♣J], [♥A], [♥7], [♥6], [♣5], [♦7], [♥10]
// 玩家1: 索引0,3,6 索引 % 3 == 0
// 玩家2: 索引1,4,7 索引 % 3 == 1
// 玩家3: 索引2,5,8 索引 % 3 == 2
// 3.根据索引将牌发给不同的玩家
for (int i = 0; i < pokers.size(); i++) {
// i表示索引,poker就是i索引对应的poker
Poker poker = pokers.get(i);
if (i >= 51) { // 最后3张给底牌
diPai.add(poker);
} else if (i % 3 == 0) { // 玩家1
player01.add(poker);
} else if (i % 3 == 1) { // 玩家2
player02.add(poker);
} else if (i % 3 == 2) { // 玩家3
player03.add(poker);
}
}
// 看牌
System.out.println("玩家1: " + player01);
System.out.println("玩家2: " + player02);
System.out.println("玩家3: " + player03);
System.out.println("底牌: " + diPai);
// 还要创建一副牌
// 创建一个ArrayList用于存放一副牌
}
}
总结
如果String类型的特殊字符复制到idea会变成数字+字母,那就先复制特殊字符,再加引号
排序:
由输出新牌观察可得,可以根据牌的索引来判断牌的大小。


大王也是相同的方法
