今天给大家介绍一个史上最简单的爬虫程序,如何利用python中的pandas库来快速读取web网页中的table数据,我以搜狐NBA数据中心的一个网页(http://data.sports.sohu.com/nba/nba_teams_rank.php?type=division#division)为例,该网页包含了6个table,我们要做的是快速获取这6个table中数据,并对其格式进行调整,使其更加美观实用:

1. 读取数据
我们使用pandas的read_html方法可以快速获取网页中所有table的数据。
import pandas as pd
url="http://data.sports.sohu.com/nba/nba_teams_rank.php?type=division#division"
tables = pd.read_html(url)
print("table数量:",len(tables))
tables
2. 调整数据格式
我们的tables中包含了6个table的数据,下面我们查看一下第一个table中数据
df1 = tables[0]
df1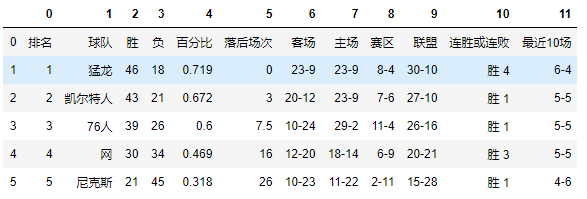
很显然第一个table中的表头不是我们所需要的,看上去第0行应该是表头,所以接下来我们要做的是将第0行变成我们的表头,并删除原来的第0行:
df1.columns = list(df1.iloc[0])
df1 = df1.drop([0], axis=0)
df1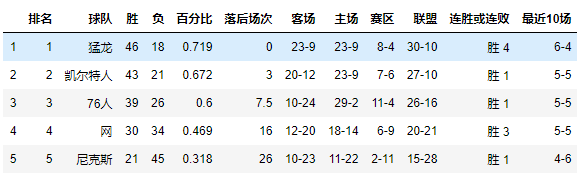
3. 删除不需要的行或列,并重建索引
上面的数据经过调整以后已经比较完美了,但是如果是你自己的数据,你可能还需要进一步完善,比如删除某些行或列,最后再重建索引,下面我们来实现以下删除若干行和列,再重建索引的方法:
#删除第3,4行
df1 = df1.drop([3,4], axis=0)
#删除客场,主场这两列
df1 = df1.drop(['客场', '主场'], axis=1)
#重建索引
df1.reset_index(drop=True)
4.总结
经过上述简单折腾以后,我们可以快速实现一个最简单爬虫的功能,通过这个简单的方法我们可以自己扩展出更加复杂的功能,比如可以通过修改网页链接中的参数的方法来获取需要翻页的数据等等。