1. 数值/连续特性
- 商品的价格:二手商品的成交价格。我们的label
- 运费
2. 类别特征:
- 商品是否包邮:1是包邮,0是不包邮
- 商品的新旧程度
- 商品的标题
- 品牌名称:该产品的生产商品牌名称
- 商品的类目:由“\”分隔的项目的单个或多个类别F
- 商品的描述:可能包括删除的单词,由(rm)标记
对label商品的价格进行可视化,发现出现严重的数据倾斜,长尾现象严重,我们对价格进行cox-box转换(在变换前给值加1避免0和负数)

0.55的商品包邮,0.45的商品不包邮,不包邮用户所支付的平均价格低于那些包邮用户。这与我们认为消费者需要更低的价格来补偿额外的运费是一致的。

商品的类目
大约有1287个商品的类别,但在每一个类别中,我们总是先看到一个主要/一般类别,然后是两个更特殊的子类别(例如:美容/化妆/脸部或嘴唇)。此外,大约有6327个商品没有类别标签。让我们将类别分成三列。稍后我们将看到,从卖方的角度来看,这些信息实际上非常重要,我们如何处理brand_name列中缺失的信息将影响模型的预测。
品牌名称大概有4809件商品缺失了该信息
商品描述由于它是非结构化的文本数据,这是否意味着更详细和更长的描述将导致更高的投标价格?对其进行处理将删除所有标点符号,删除一些停止词:
需要检查商品描述中是否有缺失的值(4个样本没有描述),并将这些样本从我们的训练集中删除。
如果我们看看最常见的单词 大小,免费和包邮,可能为了吸引顾客这与我们之前所显示的价格和运输这两个变量之间几乎没有相关性是矛盾的(或者运输费用不考虑价格的差异)。品牌也起到了相当重要的作用
文本处理-商品描述。以下部分基于https://ahmedbesbes.com/how to mine-newsfeed-data-and extract- interactive-insights-inpython.html中的教程
预处理:标记
大多数情况下,NLP项目的第一步是“标记”文档,其主要目的是使文本规范化。
通常包括:把商品描述分成句子,然后把句子分成标记
去掉标点符号,去掉停用词,英文大小写转换
预处理:tf-idf
tf-idf是频率逆文档频率的缩写。它量化了特定单词相对于文档或语料库集合的词汇表的重要性。该指标取决于两个因素:词频:一个单词在给定文档中出现的次数(即单词包)与文档频率成反比:一个单词在文档语料库中出现的次数的倒数这样想:如果这个词在所有文档中都广泛使用,那么它在特定文档中的存在将不能为我们提供关于文档本身的很多特定信息。因此,第二项可以看作是惩罚常用词,如“a”、“the”、“and”等tf-idf,因此可以看作是特定文档中单词相关度的加权方案。
下面是tfidf得分最低的10个标记,这并不奇怪,这是非常通用的单词,我们无法用它们来区分不同的描述。

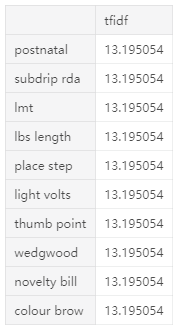
下面是tfidf得分最高的10个标记,其中包含了非常具体的单词,通过查看它们,我们可以猜出它们属于哪些类别:
考虑到tfidf矩阵的高维数,我们需要使用奇异值分解(SVD)技术来降低其维数。为了可视化我们的词汇表,我们接下来可以使用t-SNE将维度从50减少到2。
t-SNE更适合降维为2或3分布随机邻接嵌入(t-SNE)t-SNE是一种降维技术,特别适合于高维数据集的可视化。目标是取高维空间中的一组点,并在低维空间(通常是二维平面)中找到这些点的表示形式。它是基于邻域图上随机游走的概率分布来寻找数据内部的结构。但是由于t-SNE的复杂度非常高,通常在应用t-SNE之前,我们会使用其他高维约简技术
首先,让我们从培训和测试项目的描述中提取一个示例,因为t-SNE可能需要很长时间来执行。然后,我们可以使用SVD将每个向量的维数从n个分量(50)减少到n个分量(50)
我仔细看了一下最近几次比赛的NLP比赛的baseline kernel,发现NLP并没有像之前不了解时候感觉的那样复杂,一套流程下来大概三步吧.
- 用正则或NLTK对句子分句然后分词,另外根据需求涉及stopwords,词型还原等.
- 用sklearn的TfidfTransformer及CountVectorizer或keras的一些工具将句子向量化,再加上一些其他统计特征.
- 使用NB,GBDT,FM,LR,NN等方法模型建模,融合.
当然以上只能做出一个baseline,我并没有参加过比赛,如何提高性能可能有很多技巧,重点在于特征还是模型的设计我也不知道.
https://www.kaggle.com/lopuhin/mercari-golf-0-3875-cv-in-75-loc-1900-s
http://dzglalala.cn/2018/03/01/Mercari%20Price%E8%B5%9B%E5%90%8E%E6%84%9F/
https://www.bilibili.com/video/av18915803/
https://www.fashici.com/tech/620.html
https://blog.csdn.net/qq_33323162/article/details/78954263
https://www.cnblogs.com/zhengzhe/p/8983730.html
https://zhuanlan.zhihu.com/p/33987753
1.数据分析和处理
Mercari提供的价格数据包括如下信息:商品的标题、商品的描述、商品的类目、商品的新旧程度(离散变量),商品是否包邮,商品的价格。现在我们有训练集和测试集两个数据集,其中训练集有118.6万数据,测试集有29.6万数据。
建模前我们首先解决以下两个问题:(1)如何选择合适的loss function(2)如何处理数据作为模型的输入.
首先,我们的目标是预测商品的价格,是一个回归模型,所以我们的loss function应该用RMSE;另外商品的价格是一个非负的实数,所以价格模型及其loss function都应该是在logarithmicscale上的。同时logscale把小的数值拉的更远,让大的数值之间拉的更近。也就是说log(10)与log(20)之间的距离等同于log(100)与log(200)之间的距离。这样我们的模型就不会被少数价格高的商品的数据所主导。结合以上两点,我们选取RMSLE(如下所示)作为loss function是合适的,其中是预测价格,是真实价格。
其次,数据应该以什么形式作为模型的输入, 商品的类目、商品的新旧程度,商品是否包邮作为离散标量,我们可以直接用one hot key encoding将其向量化,商品的标题和商品的描述作为文本输入,可以有多种处理方式,我们尝试了两种方案,(1)用其TFIDF vector作为文本的向量化表示, (2)基于word embedding的GRU模型。下面我们展开介绍这两个方案。
2.基于TFIDF特征的多层神经网络模型(MLP)
影响商品的价格的文本信息包括商品标题和商品和描述,商品标题通常是关键词的堆砌,商品描述中对价格影响比较大的通常也是商品的型号、品牌、新旧程度等关键词,因此在价格预估模型中TFIDF的performance要优于sequential模型(例如LSTM或GRU模型)。但并不是说GRU模型对于优化价格模型完全没有增益,之后我们会提到,GRU模型能够很大的提高ensemble模型的准确度。
2.1基于TFIDF的MLP模型
模型的第一步是把商品的文本特征变换成TFIDF特征向量表示,我们可以用sklearn中的函数tfidfvectorizer实现这一点。同时这里我们把商品的标题独立于商品的描述,单独extract其TFIDF,主要原因是相比描述,标题对商品价格有更大的影响作用。然后基于商品的向量化表示,我们建了一个五层的神经网络,采用RELU激活函数。具体结构如下图表示:
我们发现把模型在同一训练样本上训练多次,然后emsemble多个模型的结果可以提高模型在测试集上的预测效果。同时我们可以把文本的TFIDF向量二值化,即所有的非0输入设为1,为0的输入依旧为0,这样我就会增加一个训练集。 因此我们把MLP模型在原始训练集上训练两次,在二值化后的训练集上训练两次。发现基于原数据的MLP单模型在测试集上的RMSLE为0.4138,基于二值化后的数据的MLP单模型在测试集上的RMSLE为0.4179,4个模型emsemble后的RMSLE为0.3952
2.2 MLP模型的变种
常识告诉我们商品标题的文本信息与商品的类目是密切相关的,通过数据分析我们也发现不同的关键词在不同类目下的分布完全不同。虽然一个好的神经网络模型可以catch到不同变量之间的相关性,但我们依然尝试了人为地加入了标题和类目间的交叉结构,其模型结构如下:

类似的我们把该MLP模型在原始样本上训练两次,在二值化后的样本上训练两次。基于原始样本的单模型在测试集上的RMSLE为0.4151,基于二值化后的数据的单模型在测试集上的RMSLE为0.4166,四次训练emsemble后的RMSLE为0.3977
3.基于GRU的循环神经网络模型
LSTM和GRU是比较常用的基于文本序列的模型,相较于LSTM, GRU模型的参数少,训练比较快,这里我们采用了GRU模型。虽然GRU模型的单模型performance相比基于TFIDF的多层神经模型要差些,但由于GRU模型的模型结构和TFIDF模型的模型结构有很大差异,可以极大的提高ensemble模型的准确率。
以商品的标题为例,首先通过padding(right padding)把所有商品标题变为同一长度,标题太短的情况下右边补0,然后通过one hot key的编码方式将每个word转换为向量形式,向量的维度为词典的大小, 然后连接一个word embedding层对其进行降维,商品标题中的每个词依次进入GRU层,产出一个向量代表商品标题;用这种方式把商品标题和描述都转化为其相应的向量表示,然后跟其他特征一起输入到下一层。具体的结构如下

在GRU模型中标题和商品描述可以共用一个word embedding layer,这样可以减少模型参数,提高训练速度。我们发现GRU模型单模型的RMSLE为0.4223,同一模型在训练数据上训练四次,然后ensemble其预测结果,得到ensemble模型的RMSLE为0.4152。
4.模型Ensemble
通过以上实验我们发现,由于商品的描述,尤其是标题通常是关键词的堆叠,基于TFIDF的MLP模型更适用于解决‘基于商品描述预测商品价格’的问题。但由于GRU模型的模型结构完全不同于MLP模型,所以三个结构迥异的模型ensemble后,反而会显著的模型整体的准确率。这里ensembling的方法我们采用的是不同模型的加权平均。模型2.1和模型2.2ensemble后的rmsle降低为0.3916(theensembled prediction is average of the outputs from model 2.1 and model 2.2),三个模型ensemble后rmsle降低为0.3873(the final ensembled prediction is weighted average of the outputs from thefirst ensembling step with weight 3/4 and the outputs from model 3 with weight1/4)。

5.总结
基于文本信息的价格预估模型的商业化应用目前不是很多,我们看到基于文本的模型很好的解决了商品数据非结构化的问题,未来还可以结合商品的图片特征,以及优化ensemblemethod 例如尝试boostingand stacking(another predictionmodel is built on top of the base models and take the predictions from the basemodels as input)等方法,进一步对模型进行优化。
import os; os.environ['OMP_NUM_THREADS'] = '1'
from contextlib import contextmanager
from functools import partial
from operator import itemgetter
from multiprocessing.pool import ThreadPool
import time
from typing import List, Dict
import keras as ks
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer as Tfidf
from sklearn.pipeline import make_pipeline, make_union, Pipeline
from sklearn.preprocessing import FunctionTransformer, StandardScaler
from sklearn.metrics import mean_squared_log_error
from sklearn.model_selection import KFold
@contextmanager
def timer(name):
t0 = time.time()
yield
print(f'[{name}] done in {time.time() - t0:.0f} s')
def preprocess(df: pd.DataFrame) -> pd.DataFrame:
df['name'] = df['name'].fillna('') + ' ' + df['brand_name'].fillna('')
df['text'] = (df['item_description'].fillna('') + ' ' + df['name'] + ' ' + df['category_name'].fillna(''))
return df[['name', 'text', 'shipping', 'item_condition_id']]
def on_field(f: str, *vec) -> Pipeline:
return make_pipeline(FunctionTransformer(itemgetter(f), validate=False), *vec)
def to_records(df: pd.DataFrame) -> List[Dict]:
return df.to_dict(orient='records')
def fit_predict(xs, y_train) -> np.ndarray:
X_train, X_test = xs
config = tf.ConfigProto(
intra_op_parallelism_threads=1, use_per_session_threads=1, inter_op_parallelism_threads=1)
with tf.Session(graph=tf.Graph(), config=config) as sess, timer('fit_predict'):
ks.backend.set_session(sess)
model_in = ks.Input(shape=(X_train.shape[1],), dtype='float32', sparse=True)
out = ks.layers.Dense(192, activation='relu')(model_in)
out = ks.layers.Dense(64, activation='relu')(out)
out = ks.layers.Dense(64, activation='relu')(out)
out = ks.layers.Dense(1)(out)
model = ks.Model(model_in, out)
model.compile(loss='mean_squared_error', optimizer=ks.optimizers.Adam(lr=3e-3))
for i in range(3):
with timer(f'epoch {i + 1}'):
model.fit(x=X_train, y=y_train, batch_size=2**(11 + i), epochs=1, verbose=0)
return model.predict(X_test)[:, 0]
def main():
vectorizer = make_union(
on_field('name', Tfidf(max_features=100000, token_pattern='\w+')),
on_field('text', Tfidf(max_features=100000, token_pattern='\w+', ngram_range=(1, 2))),
on_field(['shipping', 'item_condition_id'],
FunctionTransformer(to_records, validate=False), DictVectorizer()),
n_jobs=4)
y_scaler = StandardScaler()
with timer('process train'):
train = pd.read_table('../input/train.tsv')
train = train[train['price'] > 0].reset_index(drop=True)
cv = KFold(n_splits=20, shuffle=True, random_state=42)
train_ids, valid_ids = next(cv.split(train))
train, valid = train.iloc[train_ids], train.iloc[valid_ids]
y_train = y_scaler.fit_transform(np.log1p(train['price'].values.reshape(-1, 1)))
X_train = vectorizer.fit_transform(preprocess(train)).astype(np.float32)
print(f'X_train: {X_train.shape} of {X_train.dtype}')
del train
with timer('process valid'):
X_valid = vectorizer.transform(preprocess(valid)).astype(np.float32)
with ThreadPool(processes=4) as pool:
Xb_train, Xb_valid = [x.astype(np.bool).astype(np.float32) for x in [X_train, X_valid]]
xs = [[Xb_train, Xb_valid], [X_train, X_valid]] * 2
y_pred = np.mean(pool.map(partial(fit_predict, y_train=y_train), xs), axis=0)
y_pred = np.expm1(y_scaler.inverse_transform(y_pred.reshape(-1, 1))[:, 0])
print('Valid RMSLE: {:.4f}'.format(np.sqrt(mean_squared_log_error(valid['price'], y_pred))))
if __name__ == '__main__':
main()