前言
具体的分析爬取过程这边就直接省略了,不会分析的小伙伴直接百度下,网上有很多介绍细节的,我这边只要把我爬取中重要的几个环节写一下,加深下记忆,也给大家一个参考。
声明:我的爬虫程序是用C#写的,还有滑动和点序验证码直接对接的是第三方接口完成。
反爬背景
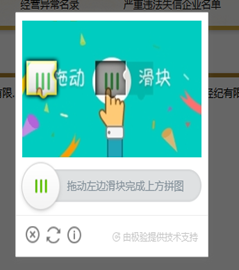
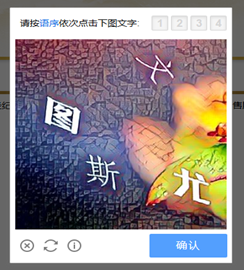
企业国家企业信用信息公示系统出现了大量反爬技术手段使得爬取网站信息变得非常困难,具体的反爬手段包括:加密混淆的js文件,IP封锁,验证码识别(滑动和语序点击并存),useragent检查,多重url拼接cookie等。

测试
- 公司ip(多次访问后):查询界面出现语序验证码,多次之后被封ip(404报错);
- 代理ip1,2,3规律:第一次查询无需验证码,之后是滑动验证码和语序验证码交替出现。大概30次左右:只出现语序验证码;(每次验证码成功解开再次查询又会出现无需验证码的情况,次数在0-3次之间)
- 特殊情况:
1.同一个ip火狐被封,谷歌没被封。
2.正常访问网站会出现521报错,刷新不出数据,空白页的情况
爬取策略
绕开验证码直接对接验证码的接口,然后直接封装需要的cookie进行伪装访问列表界面,解析出企业详情页的链接,然后依次去下载。
具体流程
1. 访问http://www.gsxt.gov.cn/SearchItemCaptcha获取名为__jsluid的cookie值和加密的JS然后通过两次解密JS获取名为__jsl_clearance的cookie值。
2. 用第1步的两个cookie值再次访问http://www.gsxt.gov.cn/SearchItemCaptcha,得到名为SECTOKEN,JSESSIONID,tlb_的cookie值和challenge、gt两个参数。
3. 发送第2步的challenge,gt参数到验证码识别接口,获取validate参数(调用的是外部的验证码接口)。
4. 访问http://www.gsxt.gov.cn/corp-query-custom-geetest-image.gif?v=54,V(参数是当前时间分钟和秒的累加数),得到ASCII码的JS语句,解析JS语句得到参数location_inf。
5. 访问http://www.gsxt.gov.cn/corp-query-geetest-validate-input.html?token=(参数是第4步的location_inf)得到ASCII码的JS语句,解析JS语句得到参数token
6. 拼接以上获得的参数,tab参数固定、province参数为空即可、其他参数填入前面动态获取的数据即可。
postData={ ‘tab’:‘ent_tab’, ‘province’:’’, ‘geetest_challenge’:challenge, ‘geetest_validate’:validate], ‘geetest_seccode’:validate+’|jordan’, ‘token’:token, ‘searchword’:keyword }
访问http://www.gsxt.gov.cn/corp-query-search-advancetest.html提交post请求获取列表页面拿到需要的公司的各个详情页链接。
7. 带着所有cookie去访问第6步的详情页链接抓取到需要的内容。
流程图

具体的代码就不贴了,太繁了。
效果图

平时不怎么上CSDN,这次上来看到好几个同学让我发代码,我也不一一发了,自己去下吧,供大家参考的小demo。
https://download.csdn.net/download/huanxiao8512/11191333添加链接描述
资源被CSDN官方删掉了,理由是违规,我换个地方,这个是19年的demo,需要的自己去下吧!https://item.taobao.com/item.htm?ft=t&id=618712985216