合作勿扰,发表文章仅供学习,不进行商业合作!
新人互粉互粉啊!
本文章为自学笔记,由于之前学过C了,文章略显粗略,还有一些小错误,希望大家指正!本次为九篇总和(我上传了word,有5000字,可自行下载)-------------By Ryan
由于有人需要word文档,我还是提供下链接吧:
1、一份是在CSDN需要积分(才要1积分啊!!)下载的(大佬有能力的话可以支持下)
CSDN链接
2、还有一份是百度网盘的,供大家免费下载,毕竟白嫖党还是多的嘛【我也是啊~~但还是多点赞评论吧,收藏数和点赞数不成正比啊~(小声哔哔)】
百度网盘链接
提取码:8xrp
自学来源:B站小甲鱼零基础学Python(挺好的有兴趣的可以自己花个三四天去看看)
自学函数大全(菜鸟教程)





1.print函数
print(1,2,3,sep=” ”,end=” ”)
2.列表
注意项:
以下 a 为一个列表
1.可用逻辑运算符进行比较
2.可用“+”进行列表间的拼接,但尽量使用extend方法
3.可用“”进行元素的多次复制,和字符串的复制相同
4.可用 in 或者 not in 判断元素在不在列表中,但只能进行一个层次的判断,返回值为true或false,如:元素 in a
5.复制列表时不要使用a = b ,因为有其一列表发生变化时另一个列表也会随着改变
6.列表前加,表示把元组或者列表中的所有元素都弹出来
1.sort() --排序
a.sort() 默认从小到大排
a.sort(revers = true) 从大到小排
sort() 实际上有三个参数,目前不涉及
2.reverse() --倒置
a.reverse() 将a列表倒置,不含参
3.extend()–添加
将两个列表连接起来
如a是个列表,b是个列表,则a.extend(b)表示a中添加进了b的元素
4.insert()–添加
添加元素到指定位置之前一位(即变成哪个位置),列表第一个位置是0
insert(位置,元素)
5.remove()–删除
例:a.remove(元素)
6.del(注:不是列表的方法)–删除
删除列表指定位置元素:del a[num]
删除整个列表:del a
7.pop()–删除
语法a.pop(num) num为要删除的位置,返回值为该元素
a.pop() 指删除列表最后一个元素
8.分片–复制形成一个列表
语法a[num1 : num2] 区间内的元素形成一个新的列表,包含num1,不包含num2
可写为a[ : num2] 或 a[ num1: ] 或a[ : ]
9.count() --计次
a.count(元素) 查看该元素在a列表中出现的次数
10.index()–查找位置
a.index(元素) 查找元素在a中的位置
a.index(元素,num1,num2) 在num1到num2的范围内查找元素的位置
***一行输入一个时:
用append()在列表最后添加一个元素
***一行输入多个时:
用input().split()时,可以输入多个元素,相当于一个列表,
而用append方法时指添加元素,所以当元素为一个列表时,形成二维列表
创建一维时:
list_str = list()
list_str = input().split()
创建二维时:
list_str = list()
list_str . append ( input().split() )
3.模块
1.模块的导入
import turtle 调用模块全部,使用:turtle . a
from turtle import * 调用模块全部,使用时直接用: a
from turtle import a 选择性导入,调用turtle模块中的一部分a
import turtle as a 推荐
安装模块 pip install 模块名
2.(__name__ )与(__main__)和(模块名)关系
在主程序中,__name__等于__main__
当外部调用模块的__name__,__name__等于模块名
该方法常用于模块(或程序)内部的测试,模块被调用时测试内容不会显示
例: if __name__== ‘__main__’:
text( )
3.搜索路径
例:import 模块
模块.path
模块.path 可查看模块的搜索路径,当调用模块时,将在路径内进行搜索,最好放在site-packages内
可用 模块.path.append(‘路径’) 将新路径添加到模块的搜索路径内
4.包
必含一个【init.py】文件的文件夹,文件夹内放其他模块,这个模块叫包
调用包内的模块时用 包名.模块名 即可
5.学习一个模块
import 模块
模块.dor #查看模块的文档
help(模块) #查看模块的文档
模块.file #模块源代码的路径
dir(模块) #查看模块的bif及方法、变量等
.模块举例(具体自查):
视频见小甲鱼P31
OS模块 —对文件、目录的操作

turtle模块 — 绘图
os.path模块 — 路径操作
turtle模块:绘图
详解:https://blog.csdn.net/zengxiantao1994/article/details/76588580
主要三个方面:
- 创建窗口
- 设置画笔
- 绘制图形
绘制完成后要关闭:turtle.done
创建窗口:

设置画笔:

turtle.fillcolor(“red”) 画笔内部填充颜色
绘制图形:



pickle模块:文件操作
注:文件打开格式为‘’wb‘’或“rb”
1.dump()方法—添加
pickle . dump(‘hhhh’)
2.load()方法 —读取
str = pickle.load(“file_name”)
print(str)
3.close()方法—关闭
##easygui模块 —图形窗口
1.msgbox(‘str’) — 输出
例:easygui.msgbox(‘hhhhh’)
**
4. 异常处理
**
1.try – except语句
except 后面可多个,except(错误一,错误二)

例:

2.try – finally语句

3.raise 错误名
主动引发一个错误
**
5.函数
**
1.函数文档
例:def add(a,b):
“加法运算器” 该行为文档
return(a+b)
- 使用add.__doc__查看文档
- 使用help(add)参看文档
2.关键字参数
例:def my(name,age):
print(name +“ ”+age)
使用:my(age = ‘15’ , name = “hh”)
3.默认参数
例:def my(name = “小红”,age = “10”):
print(name +“ ”+age)
当my()未传入参数时将使用默认参数
4.收集参数(可变参数)
例:def add(*num):
print(sum(num))
当输入多少个不知道时使用该方法
如add(1,2,3,4),原理为将参数当做一个元组传给num
注意情况:def add(*num,num1):
print(sum(num)+ num1)
输入时应该进行区分,如add(1,2,3,num1=4)
5.可返回多个值
例:def my():
return (1,2,3)
6.变量作用域
1.函数外部无法访问函数内的局部变量
2.当函数内修改全局变量时,会自动在函数内创建一个和全局变量同名的局部变量,对真正的全局变量没有影响
3.如果有必要在函数内修改全局变量,先要对将全局变量申明为global类型(global 变量名),随后真正的全局变量才可修改
7.内嵌函数(内部函数)
函数的内部函数只能在函数内调用,在外部调用不了
8.闭包
返回函数
例:

注意nonlocal 类似于global使函数可以访问别的范围的变量,不过global用于函数访问全局变量,nonlocal用于内部函数访问函数的变量
例:

9.匿名函数(lambda表达式)
相当于普通def函数的简写,更方便
例:
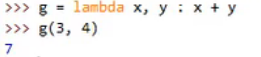
作用:

10.filter()函数—过滤器
filter(none,[1,0,false,true]),返回是对象,可用list()输出
用于筛选出为1的目标,参数1表示删选条件,参数2表示待筛选目标
11.map()函数
例:list(map(lambda x:x+1 , range(1,3))) 将range(1,3)产生的值迭代到前面的lambda表达式并输出,用list()形成一个列表
**
6.序列
**
列表,字符串,元组统称为序列,都具有以下特征

可用基本的max,min,sum,sorted,len,list(a)指对a迭代成一个列表,reversted()倒置,输出一个迭代器对象,可用list(reversed(a))输出列表,list(enumerate(a))输出一个带下标的列表(如图1),list(zip(a,b))成对打包(如图2)


**
7.字符串中含有特殊符号(\ , ‘ 等)
**
1.用转义字符,如输出\,可以用“\\”
2.或在字符串前加个字母r ,如print( r”let’s go! ” )
**
8.换行的文本用三引号
**
用””” “”” 或’’’ ‘’’
例:“””hhsh
Defs”””
**
9.random库
**
1.randint
randint(num1,num2) 生成【num1,num2】
注:
>>> ans = random.randint(20,50)
>>> x = random.getstate()
>>> print(x)
>>> ans
30
>>> ans
30
>>> ans
30
>>> ans
30
>>>
**
10.数值类型
**
1.转换
float型转int 型会进行截取,即int(5.9)= 5
科学计数法 转 str型 会区分正负,如a = 2.5e3 , str(a) = ‘ 2.5e+3 ’
2.e计法(科学计数法)
都含有小数点
2.5e3 = 2500.0
2.5E3 = 2500.0
3.bool型是数值类型
true = 1
false = 0
如:true + false = 1
**
11.查看数据类型
**
1.type( a )
如 a = 1 , type(a) = <class ‘int’>
2.isinstence( a , b )
a 表示 变量
b 表示 类型名
如果a 的类型等于 b ,返回true ,否则返回false
**
12.运算符优先级
**
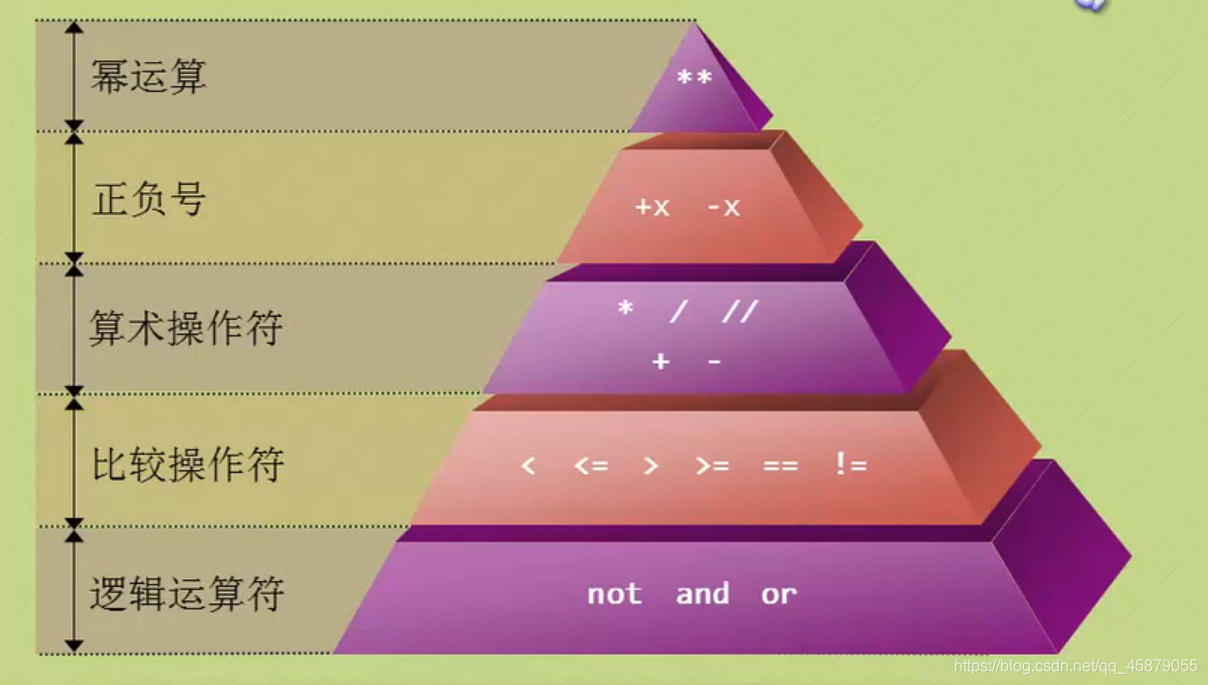
例:**与-

**
13.条件表达式(三元操作符)
**
num = N if 条件 else M
**
14.断言(assert)
**
assert 条件
当条件为假时,将跳出程序(报错)

**
15.for循环
**
for 目标 in 表达式:
循环体
通常配合range()函数:
例:
range(1,3) 表示【1,3)或【1,2】,执行两次,默认步长为1
range(3)表示【0,3)或【0,2】,执行三次
range(1,6,2) 表示【1,6)或【1,5】,执行三次,默认步长为2
**
16.元组
**
创建:x = () 或 x = 1, 或 x = (1,)
注:不能 x = (1) ,此时x类型为int ,创建时元组要含逗号即x = (1,)
元组不能修改元素,其他操作与列表相同
想要更新一个元组只能将其覆盖:例如添加一个元素 a[:2]+(1,)+a[2:],这将创建一个新元组,再将它覆盖到原先的元组即可
**
17.dir()函数
**
用于查看一个函数的方法
查看python内置函数 dir(builtins)
**
18.转义字符
**
转义字符 描述
\(在行尾时) 续行符
\\ 反斜杠符号
\' 单引号
\" 双引号
\a 响铃
\b 退格(Backspace)
\e 转义
\000 空
\n 换行
\v 纵向制表符
\t 横向制表符
\r 回车
\f 换页
\oyy 八进制数,yy代表的字符,例如:\o12代表换行
\xyy 十六进制数,yy代表的字符,例如:\x0a代表换行
\other 其它的字符以普通格式输出
**
19.字符串格式化符号
**

**
20.help()函数
**
用于查看函数的用法 help(函数名)
**
21.字符串
**
和元组类似,不能随意修改,操作和元组相同
具体用法见文首大全.
**
22.递归(分治思想)
**
例:实现累乘
def fun1(num):
if num == 1:
return 1
else:
return num*fun1(num- 1)
print(fun1(5))
实现斐波那契数列
汉诺塔分析:
一、 如果个数为1,则直接移动
二、 数量大于1
- 将n-1个从x移到y上
- 将第n个从x移到z上
- 将n-1个从y移到z上
代码实现:
def hannuota(num,x,y,z):
global temp
temp += 1
if num == 1:
print(x+"->"+z)
else:
#将n-1个从x移到y上
hannuota(num-1,x,z,y)
#将第n个从x移到z上
print(x+"->"+z)
#将n-1个从y移到z上
hannuota(num-1,y,x,z)
temp = 0
hannuota(3,'x','y','z')
print(temp)
**
23.字典
**
a = { } 或a = dict()
或:a = dict( ( (1,a),(2,b),(3,c) ) ) )
或:a = dict( 哈哈 = ‘哈’,略略 = ‘略’,嘻嘻 = ‘嘻’ ) 注意键不能加引号,相当于变量
通过a【‘哈哈’】= ‘开学’ 这种形式修改,通过 a [‘’酷酷‘’] = ‘酷’ 可以添加新项
1.fromkeys( x[,y] ) –- 新建一个字典
将值y赋给键x

2.keys()–输出字典的键
3.values() — 输出值
4.items()—输出项
5.gets(x[,y])-- 查找是否存在
X为键,若键存在则输出键对应的值,否则不输出(none,若设置了y则输出y)
6.clear()—清空字典
7.copy() — 复制字典
8.setdefuault(x,y)—添加键为x,值为y的项
9.字典1.update(字典2)—将2的项覆盖到1
24.集合
注意:
- 集合内部元素没有顺序,不能用下标读取
- 可以用for输出和用in & not in
- 可以用list(set(【1,2,3,0】))输出,但形成的列表不是按照集合的顺序排列,而是排过序
- 集合会自动去除重复元素
1.创建
a = {1,2,3} ----里面直接写值,不能写键
a = set( ) —可在里面加列表,如set(【1,2,3】)
2.a.add()—添加
3.a.remove() —删除
4.frozenset()—固定集合,不可更改
25.文件
1.读取类型
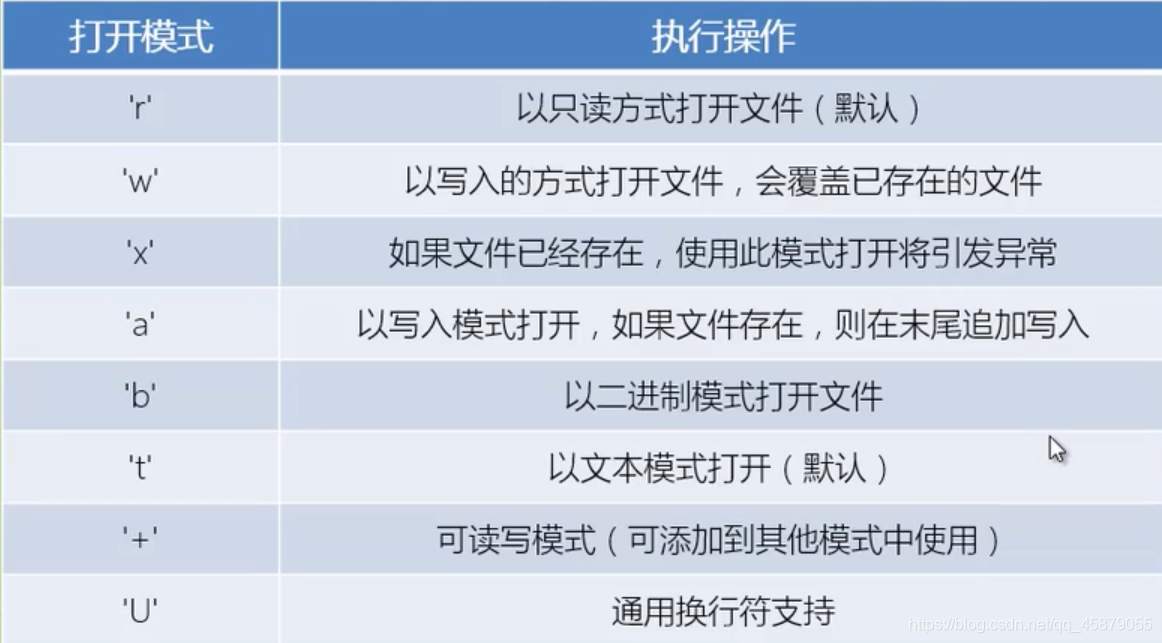
2.语法
f = open(“路径”,“读取方式”) 或 with open(“路径”,“读取方式”)as f
路径:”C:\TEXT.txt” 或 “C:/TEXT.txt”
3.方法

4.可以用for 将文件按行读取出来
for lines in file:
print(lines)
**
26.else 用法
**
1.if – else 语句
2.while – else语句
while ():
----
else:
----
只有当while语句运行完(没有使用break跳出)才会运行else
3.try – except – else语句
当为执行except时才会执行else语句
**
27.魔法方法
**

__init__ ( self ) 和__new__(cla[, ~~]) 称为构造器
__del__(self)称为析构器
更多魔法方法见文档
1.__init__ ( self ) ---构造方法
class <类名>:
init__(self [,参数表]):
#函数体
#其它的方法和属性
2.__new__(cla[, ~~])


3.__del__(self) (垃圾回收机制)
4.__str__(self)

5.repr(self)
class A():
def __repr__(self):
return “哈哈哈”
>>>a= A()
>>>a
>>>’哈哈哈’
6.属性访问

7.描述符

.算术运算魔法方法

**
28.类
**
1.私有机制
变量前加’__’则外部无法调用该变量,但可以用 a._类名__name 访问
2.继承


多重继承

在子类中额外添加内容(保留父类):
1.调用未绑定的父类方法
直接填入 父类的名字.函数名

2.调用super函数 (主要用的是这个)
super().函数名

3.组合
小甲鱼P40

4.对象

1,、把实例对象修改后会覆盖原先的类对象,再对类对象修改不影响实例对象
2、如果属性和对象的名字相同,则属性会覆盖方法,方法将调不出来
self 相当于 实例对象的名字,所以定义函数时要使用self与实例进行绑定
5与类相关的BIF
1.issubclass(class,classinfo)
如果class 是classinfo的子类则返回true,否则返回false
注意点:


2.isinstence(object,classinfo)
检查object实例是否属于classinfo类,是则返回true
注意点:


3.hasattr(object,name)

判断变量名name是否属于object ,是则返回true
4.getattr(object,name[, default] )

返回object对象的name的属性值,若name不存在,则返回default
5.setattr(object,name,value)
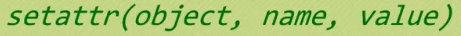
新建object.name = value
6.delattr(object,name)
删除object.name
7.property(fget = none,fset = none, fdel = none, doc = none)
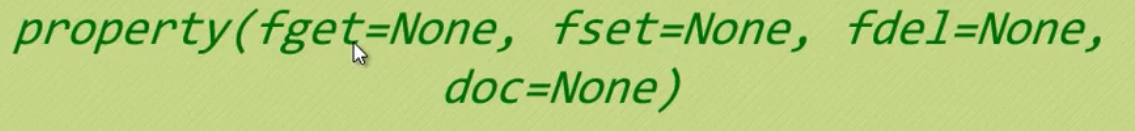
例:

**
29.容器
**
容器的协议:

**
30.迭代器
**
iter()开始迭代
next() 向下迭代一次

**
31.爬虫
**
1.urllib

URL请求:
使用urllib.request 模块
打开网址 response = urllib.request.open(“网址”)
读取内容 html = response.read()
打印内容 print(html)
进行解码 html = html.decode(“编码类型(一般为utf-8,可在网页查看源码查看)”)
获取地址 response.geturl()
获取信息 response.info() ---是个对象,具体内容可用print打印出来

2.实战
#对翻译网址的爬取
#小甲鱼P55
#可使用time.sleep(5) 减缓访问间隔 或 使用代理
import urllib.request
import urllib.parse
import json
#添加浏览器标识(一种为该方式,另一种在后追加,如图)

head = {}
head[‘user-agent’]=’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36’
url='http://rlogs.youdao.com/rlog.php?_npid=dictweb&_ncat=pageview&_ncoo=588639594.4354843&_nssn=NULL&_nver=1.2.0&_ntms=1585799026538&_nref=http%3A%2F%2Fwww.youdao.com%2Fw%2F%25E6%2588%2591%25E7%2588%25B1%2520changjunfu%2F&_nurl=http%3A%2F%2Fwww.youdao.com%2Fw%2F%25E6%2588%2591%25E7%2588%25B1%2520changjun%2F%23keyfrom%3Ddict2.top&_nres=1536x864&_nlmf=1585799026&_njve=0&_nchr=utf-8&_nfrg=keyfrom%3Ddict2.top&keyfrom=dict2.top&page=search&q=%E6%88%91%E7%88%B1%20changjun'
date = {}
date['pid']='dictweb'
date['_ncat']='pageview'
date['_ncoo'] ='588639594.4354843'
date['_nssn'] ='NULL'
date['_nver'] ='1.2.0'
date['_ntms'] ='1585799026538'
date['_nref'] ='http://www.youdao.com/w/%E6%88%91%E7%88%B1%20changjunfu/'
date['_nurl']='http://www.youdao.com/w/%E6%88%91%E7%88%B1%20changjun/#keyfrom=dict2.top'
date['_nres']='1536x864'
date['_nlmf'] ='1585799026'
date['_njve'] ='0'
date['_nchr'] ='utf-8'
date['_nfrg'] ='keyfrom=dict2.top'
date['keyfrom'] ='dict2.top'
date['page'] ='search'
date['q'] ='我爱 changjun'
#将数据进行编码
date = urllib.parse.urlencode(date).encode('utf-8')
#获取、解码、输出
response = urllib.request.urlopen(url,date,head)
html = response.read().decode('utf-8')
print(html)
#用于格式转换
temp = json.loads(html)
#temp 应该是个字典,然后再操作
代理事例:
import urllib.request
url = 'https://www.baidu.com/'
#ip可用列表随机使用
#如:

proxy_support = urllib.request.ProxyHandler({"HTTP":"61.135.186.243:80"})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read().decode("utf-8")
print(html)

下载:
1.urllib.request.urlretrieve(‘网址’,‘文件名’,none)
2.
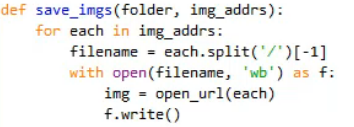
3.
from selenium import webdriver
import requests
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.get('http://baidu.com')
# 使用get_attribute()方法获取对应属性的属性值,src属性值就是图片地址。
url = driver.find_element_by_css_selector('#lg>img').get_attribute('src')
driver.quit()
# 通过requests发送一个get请求到图片地址,返回的响应就是图片内容
r = requests.get(url)
# 将获取到的图片二进制流写入本地文件
with open('baidu.png', 'wb') as f:
# 对于图片类型的通过r.content方式访问响应内容,将响应内容写入baidu.png中
f.write(r.content)
3.scrapy

步骤1:创建scrapy项目

步骤二:定义item容器

在item.py中编写需要储存的内容

步骤三:编写爬虫
https://blog.csdn.net/lwgkzl/article/details/89237060
运行scrapy shell “网址”
进入命令模式,出现>>>行
可进行xpath等操作(见小甲鱼P64 22分)

如:response.xpath('//title/text()').extract()
//title 表示目标
//text() 表示转换成文本
.extract() 表示转化成字符串类型
获得内容 sel.xpath(‘//ul/li/@herp’.extract()

对源码进行筛选,使用自带的selector选择器

XPath的使用
https://cloud.tencent.com/developer/article/1571528



步骤四:储存内容
scrapy crawl 爬虫名 -o 文件名.json -t 文件类型(json)
4.selenium
详见:https://cuiqingcai.com/5630.html
from selenium import webdriver
#设置浏览器驱动举例:
#browser = webdriver.Chrome()
#browser = webdriver.Firefox()
#browser = webdriver.Edge()
#browser = webdriver.PhantomJS()
#browser = webdriver.Safari()
browser = webdriver.chrome()
#请求网页
browser.get(‘https://www.taobao.com’)
#打印网页源码
#print(browser.page_source)
查找方法举例:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
成功实战(爬图片):
from selenium import webdriver
import requests
import time
#下载图片
def download_img(url,temp):
filename = 'img_crawler_'+str(temp)+'.jpg'
with open(filename,'wb') as f:
f.write(url.content)
print(str(temp)+" finish")
time.sleep(.5)
#获取地址
browser = webdriver.Chrome()
browser.get('https://www.meitulu.com/item/21036.html')
web_href = browser.find_elements_by_xpath('/html/body/div[4]/center/img')
#web_href = browser.find_elements_by_css_selector('#lg>img')
print('获取')
print(web_href)
print('结束')
temp = 1
for item in web_href:
href =item.get_attribute('src')
print(temp, href, sep="---")
url_img = requests.get(href)
download_img(url_img,temp)
temp += 1
time.sleep(2)
browser.close()
**
32.正则表达式
**
使用re模块
***group()方法的使用
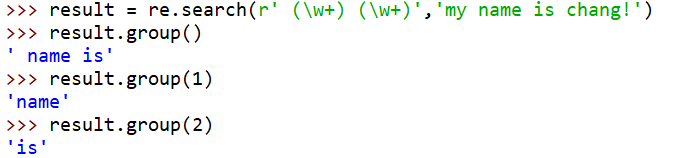
***编译标志


***模式对象
temp = re.compile(r’[a-z]’)
temp.findall(‘ha123ha’)
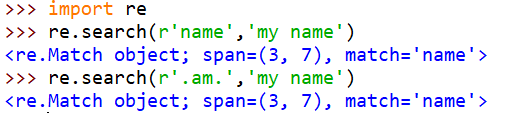
1—re.seach(r’规则’,”文本”)
r表示原始字符串
点号可用代表任何符号(除\)
. 表示( . )本身
\d表示任何数字
\数 表示重复;\三位数 表示八进制字符

$ 和 \Z 表示结尾
^ 和 \A 表示开头

[ ]表示内部都为字符,除一些特殊字符(- \ ^)
{ }表示前个字母重复次数(可为0),内部可用是个范围
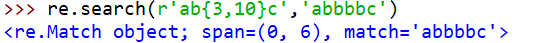
-表示范围

例:(查找0-255的数)

分析:000-199 或 200-249 或250-255
2---findall(r’规则’,”文本”)
找到符合条件的输出列表
例:

[ ] 内^放在最前表示取反,最后表是本身,例:

+表示匹配子表达式一次或多次

*表示匹配子表达式零次或多次

? 表示匹配子表达式零次或一次
默认在符合条件下尽可能多匹配,用?可限制一次

\s 表示空白字符(\t \n \r \f \v)
\w 表示单词字符(汉字、字母、数字、下划线)

其他 \字符 见表!