接上一篇获取完股票代码信息后,我们打开东方财富网,一通瞎点,进到某股票的K线板块
打开调试界面,XHR中并没有我们想要的数据,从网页数据加载来看应该不是实时资源的肯定有个传输的地方,我们先清空完所有Network的资源
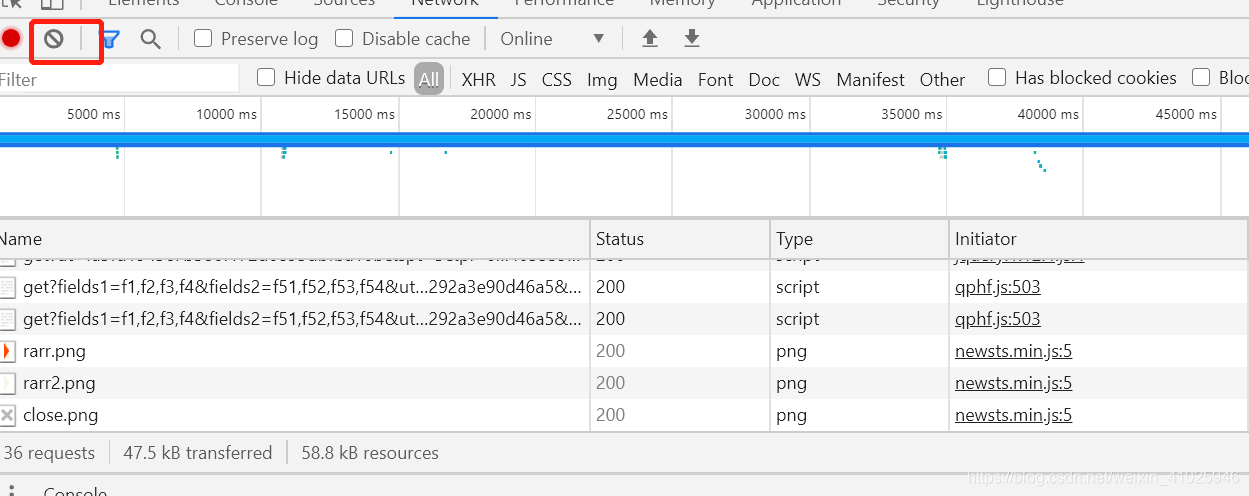
然后把鼠标放到K线上可以从后台再次获取传输数据,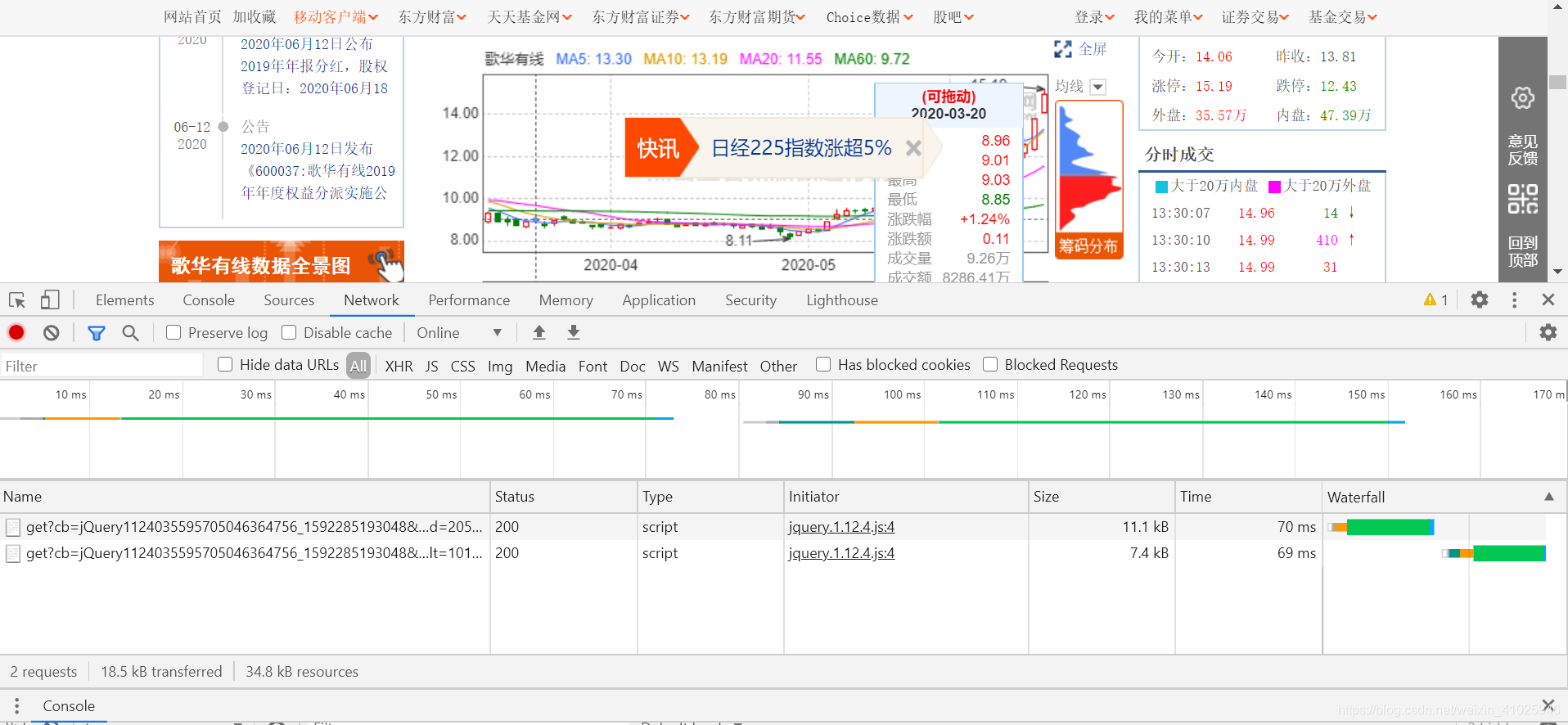
获取到数据立刻按按钮暂停获取,不然数据增多影响我们排查数据获取的Url,很快我们就可以查到JSON数据的url

该JSON数据获取地址的url为:http://56.push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery1124035595705046364756_1592285193048&secid=1.600037&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58&klt=101&fqt=0&end=20500101&lmt=120&_=1592285193152
首先我们能确认是个get请求方式,我们可以采用python代码进行提交参数的拆解,也可以肉眼拆解,
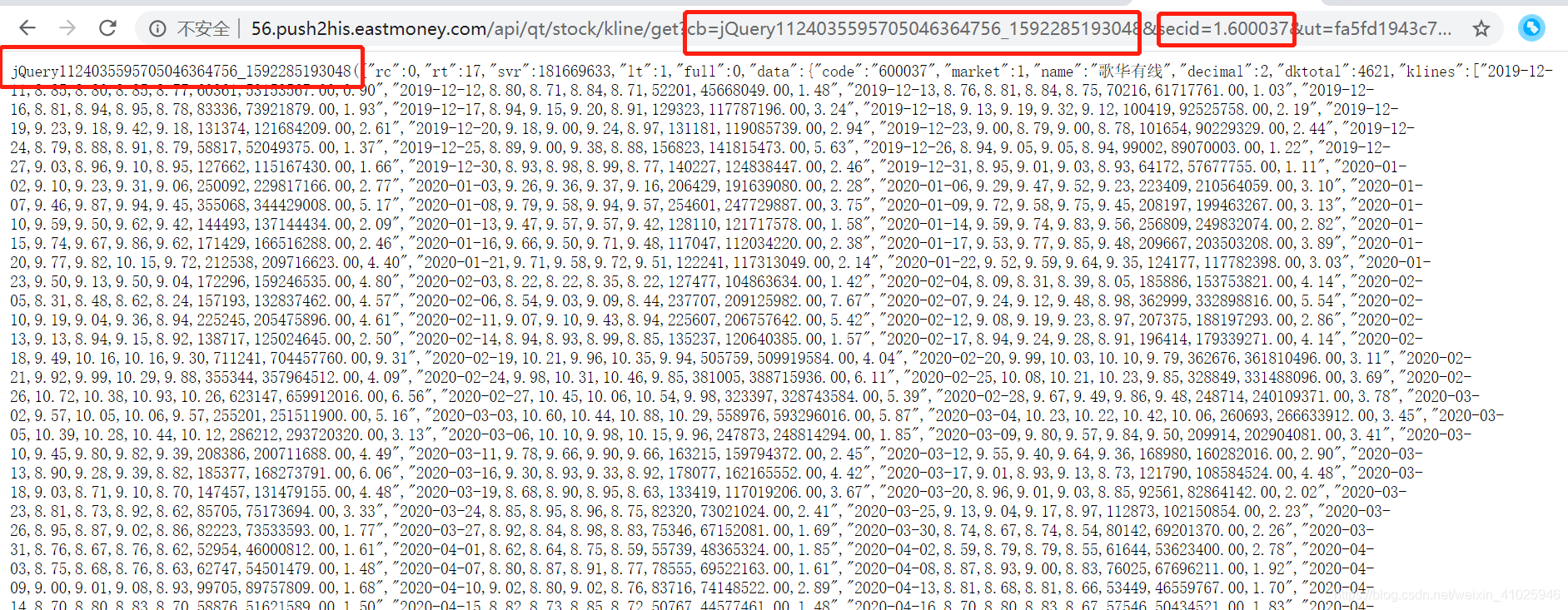
可以发现地址栏的jQuery与网页输出的部分数据相对应,股票代码为secid,但secid多了1. (此部分我们拿不同证券试验可以知道 深股为0. 上证为1. 开头 )。
我们去掉jQuery看能否获取数据,

可以看到可以获取到相关的数据,而且变得干净了不少,后续我们一个个拆解看有哪些没用的提交参数。
观察完页面和数据,我们来着手代码部分,首先从上一篇获取股票代码的文章我们已经拿到所有股票代码,需要进行股票代码输出
def get_stock_code():
#stock=['0.002415','0.000063']#深的股票为0. 上证为1.开头 加上对应股票代码
stock=[]
with open (file_stock,'r') as f:
for i in f.readlines():
if i !=None:
stock.append(i.strip("\n"))
#print(stock)
if stock:
return stock #返回股票代码
else:
return stock
接着进行网页数据获取
def get_json(url): # 获取JSON
try:
r=requests.get(url) # 抓取网页返回json信息
r.raise_for_status()
r.encoding = 'utf-8'
#print(r.json())
#with open(r"C:\Users\xxp\.spyder-py3\testcode\tmp.txt", "w") as fp:
#fp.write(json.dumps(r.json(),indent=4,ensure_ascii=False)) # txt测试是否成功获取网页
return r.json()
except:
return 'false'
进而可以写出获取股票代码对应的JSON数据文件的代码:
def main():
stock=get_stock_code()
start= time.time()
#print(num)
for code in stock: # 获取每个股票的数据
url = 'http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf61&klt=101&fqt=1&secid='+str(code)+'&beg=0&end=20500000&_=1591683995756'# 1591683995 为时间戳
#此部分url删减了部分不需要的内容
stock_info=get_json(url)#获取json数据
get_stock_info(stock_info)#对数据进行处理
time.sleep(3)# 暂停3秒,防止被服务器拉黑
print('总耗时:' ,time.time()-start)
最后进行获取数据的整合,填充股票名称和股票代码,放入一个EXCEL中方便分析,总体代码如下:
import requests
import pandas as pd
import time
import json
import os
import csv
import numpy as np
file_stock=r'C:\Users\xxp\.spyder-py3\testcode\test\stock.txt' #股票代码txt
filename=r'C:\Users\xxp\.spyder-py3\testcode\test'#生成文件夹路径
file=r'C:\Users\xxp\.spyder-py3\testcode\test\stock.csv'#生成文件路径
class ClassName: # 构建类似static函数 python没有静态 只能自己构建
COUNT=0
def __init__(self, static):
self.static = static
ClassName.COUNT+=1
def get_json(url): # 获取JSON
try:
r=requests.get(url) # 抓取网页返回json信息
r.raise_for_status()
r.encoding = 'utf-8'
#print(r.json())
#with open(r"C:\Users\xxp\.spyder-py3\testcode\tmp.txt", "w") as fp:
#fp.write(json.dumps(r.json(),indent=4,ensure_ascii=False)) # txt测试是否成功获取网页
return r.json()
except:
return 'false'
def get_stock_code():
#stock=['0.002415','0.000063']#深的股票为0. 上证为1.开头 加上对应股票代码
stock=[]
with open (file_stock,'r') as f:
for i in f.readlines():
if i !=None:
stock.append(i.strip("\n"))
#print(stock)
if stock:
return stock #返回股票代码
else:
return stock
def data_write_csv(file, datas):#file为写入CSV文件的路径,datas为要写入数据列表
with open(file,'a+',encoding='utf-8-sig',newline='') as f:
writer = csv.writer(f)
for data in datas:
#print(data)#
#data_str=','.join(data) #列表拆分成str
#data_str=data_str.strip()
#print(data_str)
writer.writerow(data)
print("保存文件成功,处理结束")
def get_stock_info(result): # 获取某个股票的信息
try:
a_str = result.get("data").get("klines")# json数据对应值获取 报错时候跳过空值
s_name= result.get("data").get("name")
s_code= result.get("data").get("code")
array_str = np.array(a_str) #数组存储
#csv_str ="code,name,time,开盘,收盘,最高,最低,成交量,成交额,振幅,换手\n"
items_all=[]
for i in range(len(array_str)-31,len(array_str)-1): #数组长度限定30交易日内数据
item = array_str[i] #获取数据
items = item.split(",")#拆分后变成List函数
items.insert(0,s_name)
items.insert(0,'#'+s_code)#拼接数据
items_all.extend([items]) #数组整合
#print(items_all)
if os.path.exists(filename):#文件路径检测
#print("path exists")
if os.path.exists(file): #文件检测
data_write_csv(file,items_all)# 进行excel多个股票写入
ClassName(1)#调用自己构建的静态函数
print('股票数',ClassName.COUNT) #输出调用次数
else: #文件不存在就创建
df=pd.DataFrame(data=items_all,columns=['code','name','time','开盘','收盘','最高','最低',
'成交量','成交额','振幅','换手'])
df.to_csv(file,index=False,encoding='utf_8_sig')
print ('文件创建成功')
ClassName(1)#调用自己构建的静态函数
print('股票数',ClassName.COUNT) #输出调用次数
else:
os.makedirs(filename)
print('create path success')
return ''
except Exception as e :
return e
def main():
stock=get_stock_code()
start= time.time()
#print(num)
for code in stock: # 获取每个股票的数据
url = 'http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf61&klt=101&fqt=1&secid='+str(code)+'&beg=0&end=20500000&_=1591683995756'# 1591683995 为时间戳
#此部分url删减了部分不需要的内容
stock_info=get_json(url)#获取json数据
get_stock_info(stock_info)#对数据进行处理
time.sleep(3)# 暂停3秒,防止被服务器拉黑
print('总耗时:' ,time.time()-start)
if __name__=='__main__': #在其他文件import这个py文件时,不会自动运行主函数
main()
关于股票代码的获取可以参考我上一篇文章:Python获取所有股票代码以及股票历史成交数据分析
有什么不懂的或者代码可以优化的可以留言沟通,这个代码可以再加入一个获取状态判断400系列,从而进行400相关数据重新获取,以及多线程+多进程方式加快数据的获取。