这一节来梳理两个查询语句中的重要知识点:分组查询和limit限制。在分析了如此之多的select语句的组成部分之后,最后还会总结SELECT 语句的执行顺序以便于更好的使用SELECT 语句。
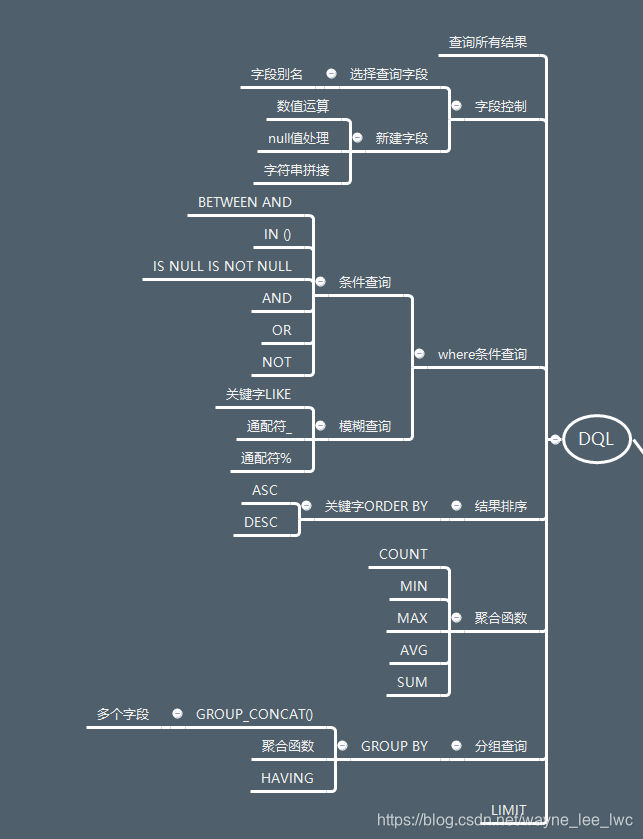
数据查询语言部分的思维导图:
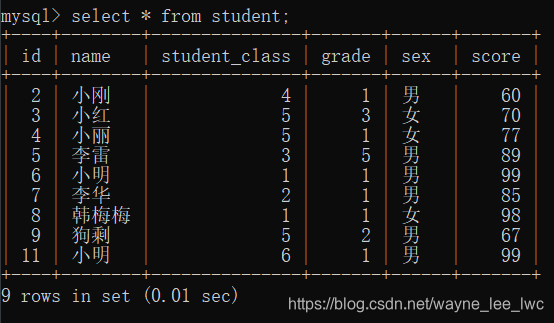
本篇博客用于演示的表为:
SQL语句:
/*
Navicat Premium Data Transfer
Source Server : Link
Source Server Type : MySQL
Source Server Version : 80020
Source Host : localhost:3306
Source Schema : learn
Target Server Type : MySQL
Target Server Version : 80020
File Encoding : 65001
Date: 15/06/2020 14:14:45
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`student_class` smallint(0) NOT NULL DEFAULT 1,
`grade` tinyint(0) NOT NULL DEFAULT 1,
`sex` varchar(3) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`score` double NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `name`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (2, '小刚', 4, 1, '男', 60);
INSERT INTO `student` VALUES (3, '小红', 5, 3, '女', 70);
INSERT INTO `student` VALUES (4, '小丽', 5, 1, '女', 77);
INSERT INTO `student` VALUES (5, '李雷', 3, 5, '男', 89);
INSERT INTO `student` VALUES (6, '小明', 1, 1, '男', 99);
INSERT INTO `student` VALUES (7, '李华', 2, 1, '男', 85);
INSERT INTO `student` VALUES (8, '韩梅梅', 1, 1, '女', 98);
INSERT INTO `student` VALUES (9, '狗剩', 5, 2, '男', 67);
INSERT INTO `student` VALUES (11, '小明', 6, 1, '男', 99);
SET FOREIGN_KEY_CHECKS = 1;
分组查询
分组查询以某一个或者某几个字段为关键字,依据字段内内容是否不同的进行分组。使用的关键字是GROUP BY
参考格式为:SELECT 字句 GROUP BY 字段1,字段2...;
只是说明格式并不足以表示明白,我们来上实际实例
例如,按照班级,将学生分组
编写SQL
SELECT student_class FROM student GROUP BY student_class;
执行:
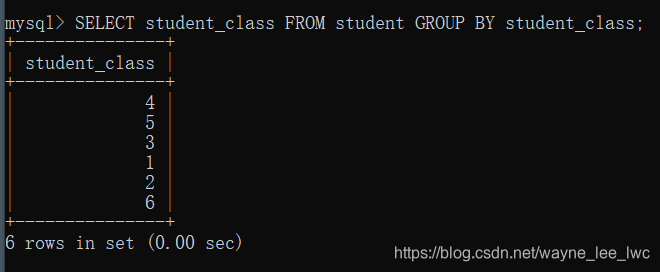
可以看到,我们将所有的班级查了出来,但是并不知道每个班级内部更多的信息。如果就是硬要查询更多的信息会发生什么
例如,查询班级的同时,在查询字段处填写姓名
编写SQL
SELECT student_class,name FROM student GROUP BY student_class;
执行:
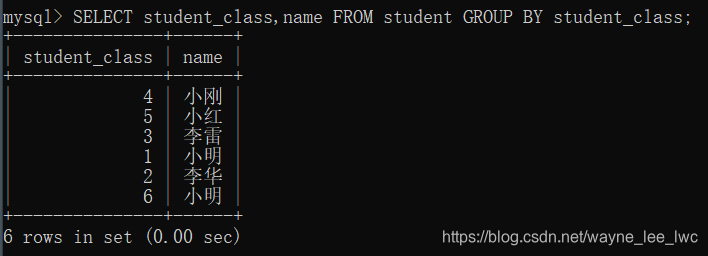
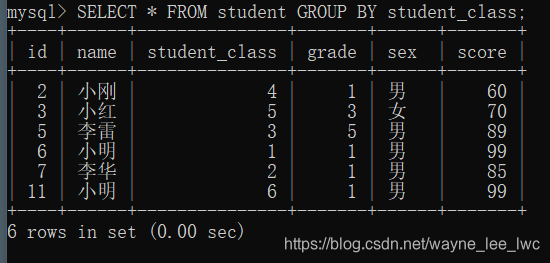
可以看到,他只为我们显示了每组中的第一条数据。
如果查询所有字段也会是这样:
编写SQL
SELECT * FROM student GROUP BY student_class;
执行:
如果仍然要求按照姓名和班级进行分组,那可以尝试同时按照姓名和班级两个字段进行分组:
编写SQL
SELECT name,student_class class FROM student GROUP BY name,class;
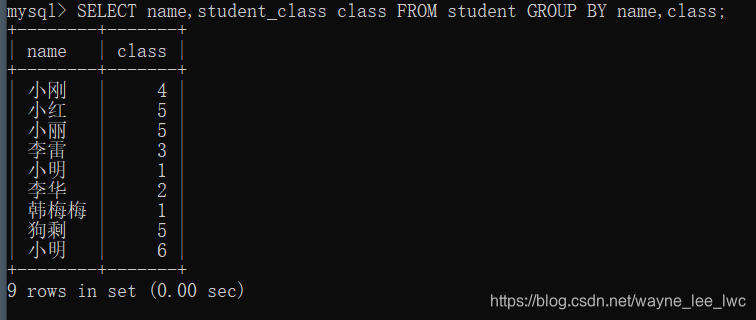
对于结果,并没有像我们期待的那样以分组的形式展现,反而像我们直接查询两个字段。
这是因为,我们以两个字段同时作为关键字段进行分组,那么两个组不同的条件就变成了两个字段内容必须同时不相同。这张表中还没有同班又同名的同学,因此所有同学都是一组
所以想要显示组中更多的内容,还需要额外的操作:
GROUP_CONCAT
使用GROUP_CONCAT函数可以将组内的更多信息拼接起来(CONCAT),作为一个字段显示出来。
使用方法就是将GROUP_CONCAT函数放在字段列表中:SELECT 分组字段1,GROUP_CONCAT(显示字段) FROM student GROUP_BY 字段1;
例如,将学生按照班级分组,并能显示每组内学生的姓名
编写SQL
SELECT student_class,GROUP_CONCAT(name) FROM student GROUP BY student_class;
执行:
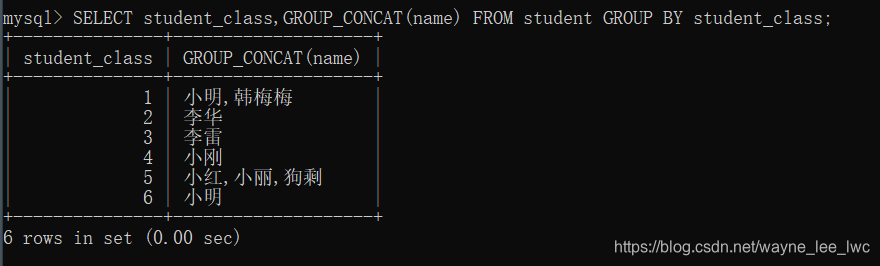
啊哈!!这回就是我们想要的结果了。
当然,如果仅是将一个字段中的内容拼接起来,那可就太小瞧CONCAT的功能了。作为拼接,它当然可以拼接多个字段切拼接额外的字符串了,将他们一并放入函数中,使用逗号隔开。
例如,按照班级,将同学们分组,并显示组内同学的姓名和分数,格式为“姓名-分数”
编写SQL:
SELECT student_class class,GROUP_CONCAT(name,'-',score) FROM student GROUP BY class;
执行:
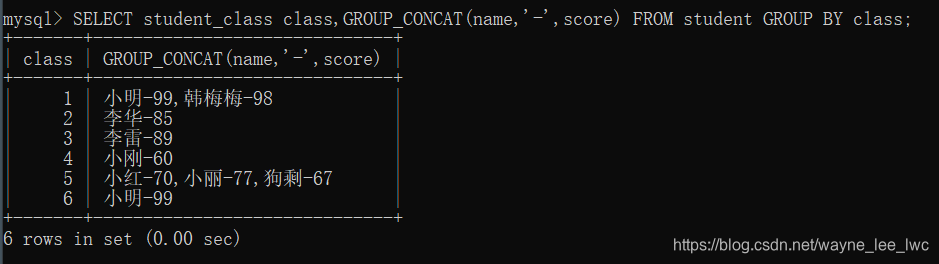
聚合函数
聚合函数在前面的博客中介绍过用法(往期的博客连接在下面),那时的聚合函数针对的对象是整个结果集,仅有一个结果。这一次,我们在分组查询中使用聚合函数,统计各个组的数据。
由于聚合函数种类较多,这里我们仅测试其中的一个AVG
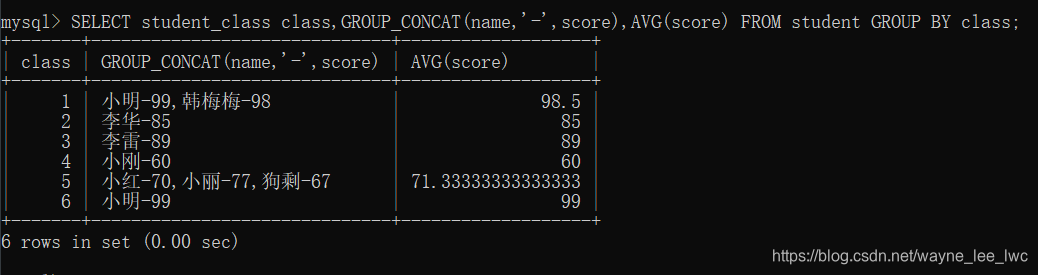
例如,将学生按照班级分组,显示所有人的姓名和分数,并计算平均分。
编写SQL:
SELECT student_class class,GROUP_CONCAT(name,'-',score),AVG(score) FROM student GROUP BY class;
执行:
HAVING限制
使用HAVING关键字可以对分好组的数据进行筛选。注意,这里筛选的对象是:分组。这里不可以使用WHERE关键字进行分组,WHERE关键字并没有分组的概念。
好在在句法上,他们没有差别,在WHERE中使用过的关键字在HAVING中也可以使用。
例如,将学生按照班级分组,显示学生的姓名和分数,只显示平均分数大于75的班级
编写SQL
SELECT
student_class class,GROUP_CONCAT(name,'-',score),AVG(score)
FROM
student
GROUP BY
class
HAVING
AVG(score) > 75;

HAVING & WHERE
为了更好的表现HAVING在分组上的筛选、WHERE在数据层面的筛选。让我们来看一个例子:
例如,将所有分数大于80的同学挑出并按照班级分组,显示姓名和分数,并筛选出其中最低分大于90的班级
编写SQL
SELECT
student_class class,GROUP_CONCAT(name,'-',score),MIN(score)
FROM
student
WHERE
score > 80
GROUP BY
class
HAVING
MIN(score) > 90;
执行:
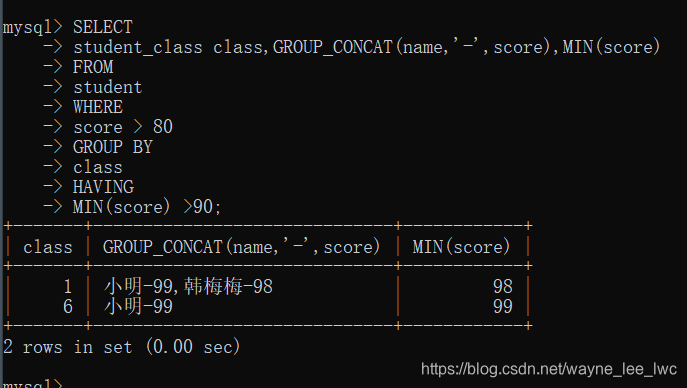
可以看到,同学中分数在70分之下的被筛选掉了,这个是WHERE的作用,所有的分组中,最低分小于80的组别被筛选掉了,这个是HAVING的作用。
排序在分组中的使用
前面我们介绍过排序ORDER BY关键字的使用,用来给数据排序。而如果在分组的情况下使用排序,排序就会作用在分组上。
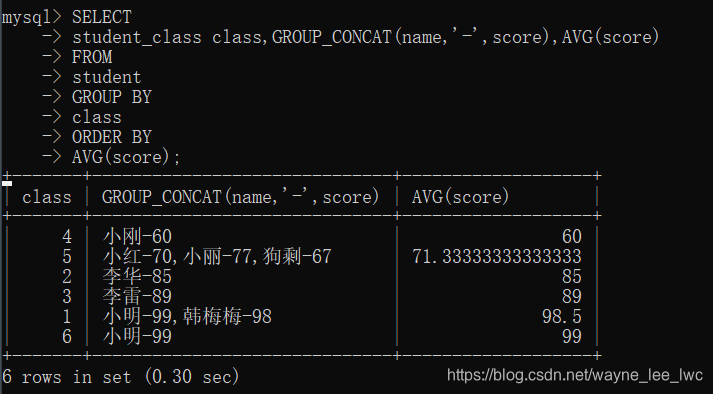
例如,将学生按照班级排序,显示姓名分数并按照平均分排序
编写SQL
SELECT
student_class class,GROUP_CONCAT(name,'-',score),AVG(score)
FROM
student
GROUP BY
class
ORDER BY
AVG(score);
执行:
需要特别注意的是,如果排序和分组同时出现,一定是排序出现在分组之后,也就是先分组后排序,否则语句就会报错。

LIMIT 限制
LIMIT限制用于限制显示条目的起始位置和数量,常用做分页查询
使用时格式为 SELECT 语句 LIMIT a,b;
其中a的位置表示显示条目初始的位置,b代表条目的数量。
需要注意的是,MySQL中是从0开始计数的!!!
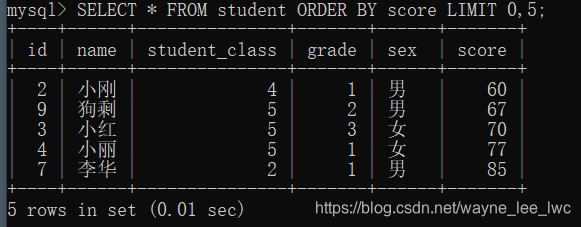
例如,查询所有学生中分数从小到大前五名
编写SQL:
SELECT * FROM student ORDER BY score LIMIT 0,5;
执行:
SELECT 语句的顺序
说了这么多和分组相关的操作,现在我们不妨来对SELECT语句的执行顺序进行一下梳理。
总的来说,select语句中涉及到的机制有:
GROUP BY分组HAVING条件WHERE条件ORDERBY排序SELECT字段选择FROM表单选择LIMIT查询限制
他们执行的顺序是:
SELECT -> FROM -> WHERE -> ORDER BY -> HAVING -> ORDER BY -> LIMIT
这里,我将《MySQL必知必会》中的表单放在这里:
| 字句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 数据排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
往期博客在这里:
- MySQL数据库基础 MySQL的下载安装及使用
- MySQL数据库基础 数据库,表,字段的增删改查
- MySQL数据库基础 数据的增、删、改
- MySQL数据库基础 数据查询语句DQL(一)字段控制,where限制查询
- MySQL数据库基础 数据查询语句DQL(二)结果排序,聚合函数
参考资料:
- 《MySQL必知必会》
- 站内视频教程:Mysql数据库基础入门视频教程