大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是官方HBase-MapReduce与自定义。
目录
通过HBase的相关JavaAPI,我们可以实现伴随HBase操作的MapReduce过程,比如使用MapReduce将数据从本地文件系统导入到HBase的表中,比如我们从HBase中读取一些原始数据后使用MapReduce做数据分析。
标注:
此处为反爬虫标记:读者可自行忽略

原文地址:https://buwenbuhuo.blog.csdn.net/
1. 官方HBase-MapReduce
1.查看HBase的MapReduce任务的执行
[bigdata@hadoop002 hbase]$ bin/hbase mapredcp

上图标记处为所需jar包
2. 环境变量的导入
- 1. 执行环境变量的导入(临时生效,在命令行执行下述操作)
$ export HBASE_HOME=/opt/module/hbase
$ export HADOOP_HOME=/opt/module/hadoop-2.7.2
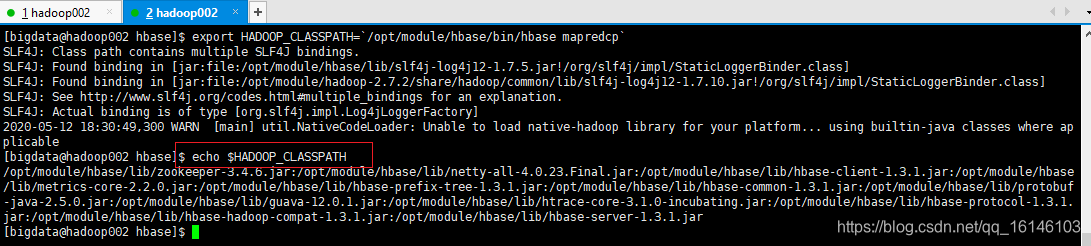
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
// 也可以直接这样
[bigdata@hadoop002 hbase]$ export HADOOP_CLASSPATH=`/opt/module/hbase/bin/hbase mapredcp`
配置完成后查看是否成功
- 2. 永久生效:在/etc/profile配置
export HBASE_HOME=/opt/module/hbase
export HADOOP_HOME=/opt/module/hadoop-2.7.2
在hadoop-env.sh中配置:(注意:在for循环之后配)
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*
- 3. 运行官方的MapReduce任务
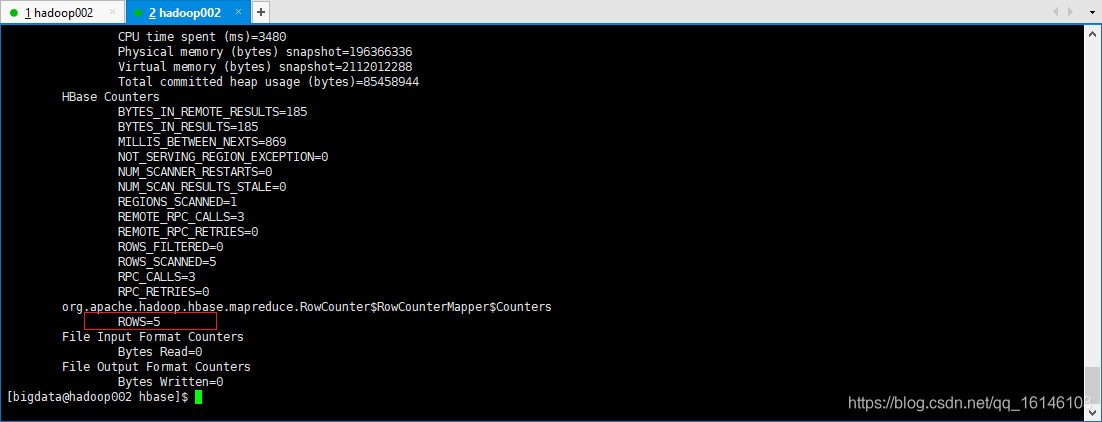
– 案例一:统计Student表中有多少行数据
[bigdata@hadoop002 hbase]$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter student
– 案例二:使用MapReduce将HDFS导入到HBase
- 1.在本地创建一个tsv格式的文件:fruit.tsv
[bigdata@hadoop002 datas]$ vim fruit.tsv
1001 Apple Red
1002 Pear Yellow
1003 Pineapple Yellow

- 2.创建HBase表
hbase(main):001:0> create 'fruit','info'
- 3.在HDFS中创建input_fruit文件夹并上传fruit.tsv文件
[bigdata@hadoop002 datas]$ hadoop fs -mkdir /input_fruit/
[bigdata@hadoop002 datas]$ hadoop fs -put fruit.tsv /input_fruit/

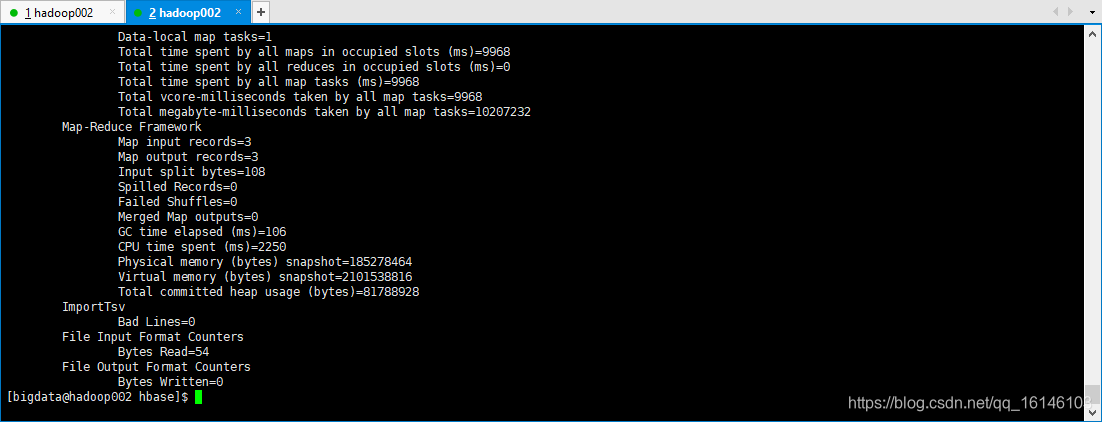
- 4.执行MapReduce到HBase的fruit表中
[bigdata@hadoop002 hbase]$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit \
hdfs://hadoop002:9000/input_fruit
- 5.使用scan命令查看导入后的结果
hbase(main):001:0> scan ‘fruit’

经过测试证明是没问题的
2. 自定义HBase-MapReduce1
目标:将fruit表中的一部分数据,通过MR迁入到fruit_mr表中。
- 1.构建ReadMapper类,用于读取fruit表中的数据
package com.buwenbuhuo.hbase.mr;
import java.io.IOException;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
/**
* @author 卜温不火
* @create 2020-05-12 19:32
* com.buwenbuhuo.hbase.mr - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class ReadMapper extends TableMapper<ImmutableBytesWritable,Put> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
Put put = new Put(key.copyBytes());
for (Cell cell : value.rawCells()) {
if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
put.add(cell);
}
}
context.write(key,put);
}
}
- 2. 构建WriteReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中
package com.buwenbuhuo.hbase.mr;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-05-12 19:32
* com.buwenbuhuo.hbase.mr - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class WriteReducer extends TableReducer<ImmutableBytesWritable,Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put value : values) {
context.write(NullWritable.get(),value);
}
}
}
- 3. 构建Driver用于组装运行Job任务
package com.buwenbuhuo.hbase.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HRegionPartitioner;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-05-12 19:32
* com.buwenbuhuo.hbase.mr - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop002,hadoop003,hadoop004");
conf.set("hbase.zookeeper.property.clientPort", "2181");
Job job = Job.getInstance();
job.setJarByClass(Driver.class);
Scan scan = new Scan();
TableMapReduceUtil.initTableMapperJob(
"fruit",
scan,
ReadMapper.class,
ImmutableBytesWritable.class,
Put.class,
job
);
job.setNumReduceTasks(100);
TableMapReduceUtil.initTableReducerJob("fruit_mr",WriteReducer.class,job,HRegionPartitioner.class);
job.waitForCompletion(true);
}
}
- 4. 打包并上传
- 5. 创建表
hbase(main):003:0> create 'fruit_mr','info'

- 6. 运行验证
[bigdata@hadoop002 hbase]$ hadoop jar hbase-0512-1.0-SNAPSHOT.jar com.buwenbuhuo.hbase.mr.Driver

hbase(main):005:0> scan 'fruit_mr'

3. 自定义HBase-MapReduce2
目标:实现将HDFS中的数据写入到HBase表中。
- 1. 构建ReadFruitFromHDFSMapper于读取HDFS中的文件数据
package com.buwenbuhuo.hbase.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-05-12 22:41
* com.buwenbuhuo.hbase.mr2 - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class ReadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
if (split.length <= 3){
return;
}
Put put = new Put(Bytes.toBytes(split[0]));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(split[1]));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("color"),Bytes.toBytes(split[2]));
context.write(new ImmutableBytesWritable(Bytes.toBytes(split[0])),put);
}
}
- 2. 构建WriteFruitMRFromTxtReducer类
package com.buwenbuhuo.hbase.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-05-12 23:09
* com.buwenbuhuo.hbase.mr2 - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class WriteReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put value : values){
context.write(NullWritable.get(),value);
}
}
}
- 3.创建Driver
package com.buwenbuhuo.hbase.mr2;
import com.buwenbuhuo.hbase.mr.WriteReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HRegionPartitioner;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @author 卜温不火
* @create 2020-05-12 23:09
* com.buwenbuhuo.hbase.mr2 - the name of the target package where the new class or interface will be created.
* hbase0512 - the name of the current project.
*/
public class Driver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop002,hadoop003,hadoop004");
Job job = Job.getInstance(conf);
job.setJarByClass(Driver.class);
job.setMapperClass(ReadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
FileInputFormat.setInputPaths(job,new Path("/input_fruit"));
job.setNumReduceTasks(10);
TableMapReduceUtil.initTableReducerJob("fruit_mr", WriteReducer.class,job, HRegionPartitioner.class);
job.waitForCompletion(true);
}
}
- 4. 打包上传
- 5.测试运行
[bigdata@hadoop002 hbase]$ hadoop jar hbase-0512-1.0-SNAPSHOT.jar com.buwenbuhuo.hbase.mr2.Driver

本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

