基于深度学习的脑胶质瘤分割方法的研究
针对传统Unet模型较浅问题解与与二维全卷积神经网络存在的三维空间信息获取不足以及三维全卷积神经网络显存消耗问题,提出了DM-DA-Unet(Dual Multidimensional Dense Attention Unet,并与ResUnet进行对比。其中DM-DA-Unet加入了Attention,DenseUnet Block 以及多尺度融合等机制,充分提取脑胶质瘤图像的多序列信息,提高分割精度。
(1)2DResUnet
整体流程为:
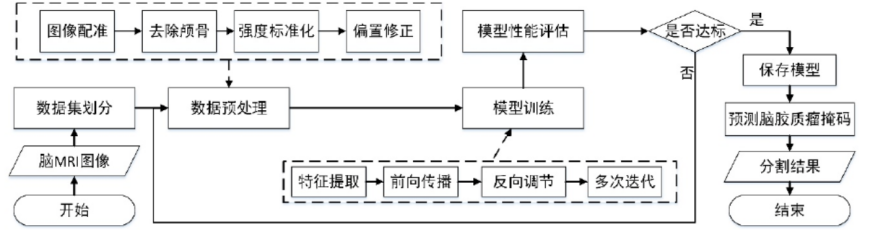
① 该算法的第一步是对数据进行预处理操作,对于脑胶质瘤的原始 MRI 进行预处理操作,从而消除原始图像采集中影响神经网络训练的因素,并使图像转化为模型需要的输入形式,其主要操作包括图像偏置修正(在核磁共振仪生成 MRI 的过程中,由于机器本身的性能限制以及周围环境的影响,生成的 MRI 常常出现具有强度不均匀和运动伪影的偏置场效应。这种偏置场效应会导致图像模糊和产生噪声从而加大图像分割的难度),图像裁剪(去除部分无关背景),图像标准化(使强度变得均匀),随机采样(首先,以病人 Flair 序列中标准化后的脑实质区域作为采样范围,同时以脑实质区域像素点作为采样中心,然后根据 2DResUnet 的模型输入要求,随机以这些点为中心取 128*128 的小框作为Patch,在 Flair 序列的每层中获取 3 个 Patch、如果这 3 个 Patch 中存在超出边界的Patch,则将其丢弃,并在其它层中多取一个符合条件的 Patch,从而使得 Flair 序列中每一层平均获得 3 个 Patch。接着在病人的其他序列中取相同位置的 Patch,从而获得大小为 2DResUnet 的输入数据)等操作
② 为了更好地解决脑胶质瘤分割中类别不均衡且需要对多区域分割的问题,本文在使用 Generalised Dice Loss(Dice Loss一般用作二分类样本不均匀,不适合用作多分类,因为在训练过程中,一旦多区域中某个区域的预测结果错误,就会出现 Dice Loss 大幅度变化的现象,从而导致梯度变化剧烈,训练不稳定)作为损失函数的基础上,再加入了Weighted Cross Entropy(WCE)损失函数。WCE 损失函数是在交叉熵(Cross Entropy)损失函数的基础上对需要分割的目标区域进行加权,从而加强模型对目标区域的学习。
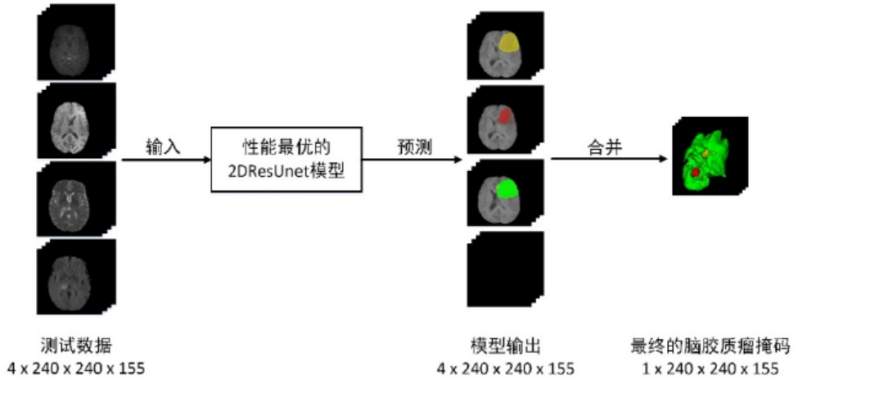
③ 模型的预测:对于 BraTS 数据集而言,原始序列图像大小为 4*240*240*155,因此可以对输入的多序列图像通过分割效果最好的 2DResUnet 模型进行逐层预测。在对输入数据的155 层二维图像进行预测的过程中,每一层都会把一个大小为 4*240*240 的数据在数据预处理之后输入到 2DResUnet 中,并得到输出大小为 4*240*240 的预测结果。在所有层都经过模型预测之后,再将所有层的预测结果进行叠加,并将多个区域进行合并,从而得到 1*240*240*155 的脑胶质瘤分割掩码结果。
疑问:为什么要采用随机采样的模式,如果采用随机采样,会不会出现采样的区域没有包含肿瘤区域,其次,如果采用随机采样,对应额掩码如何处理,如何让label与input一一对应。
(2)DM-DA-Unet
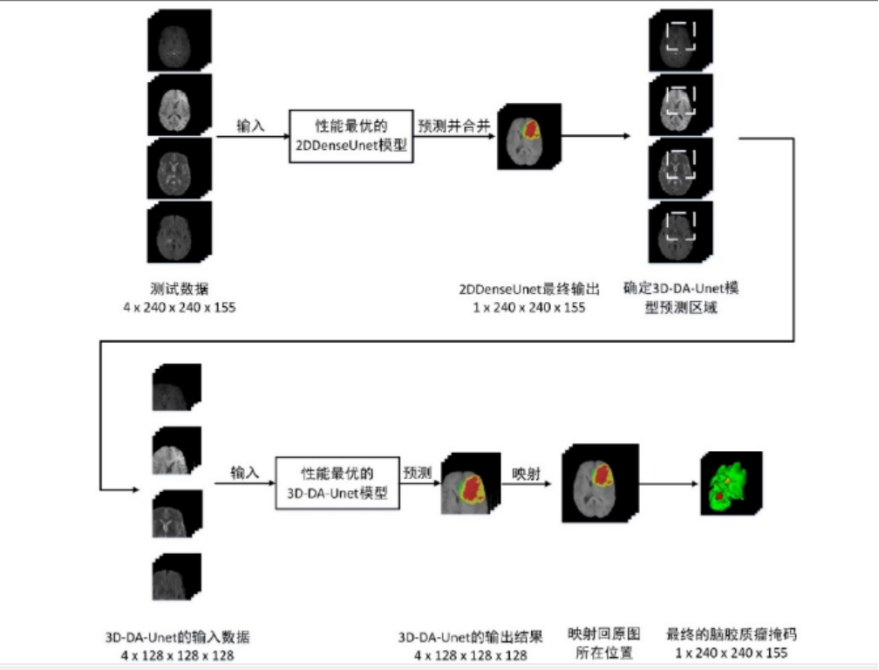
二维的卷积神经网络容易损失脑胶质瘤的空间信息,但是其消耗显存低,预测速度快,灵敏度高,但是如果全程用于三维卷积则对于硬件条件非常高。因此,预测的时候(在训练的时候是单独训练)在第一阶段使用2DDenseUnet对脑胶质瘤进行全局定位,将此输出作为三维卷积的输入,从而实现脑胶质瘤的精准分割。


Attention 机制由一个主干分支(Trunk Branch)和一个软掩码分支(Soft Mask Brank)
组成,用于融合模型下采样部分和上采样部分的特征。多尺度融合部分是在上采样的过程中收集各个阶段不同尺度的特征图,并通过UpScale 将它们的大小缩放为同一尺度并加入到最终输出的特征图中,用于融合多尺度特征。 在 3D-DA-Unet 中当图像经过三维卷积层之后常常会使用 Instance Nomalization(IN)((由于传统 BN 层是通过 Batch Size 个数据来计算均值和方差,所以对图像输入的Batch Size 大小比较敏感。在脑胶质瘤分割中,因为脑胶质瘤图像是多序列图像,如果 Batch Size 太大会造成内存泄漏和显存不足的情况,所以一般使用较小的 Batch Size 进行训练和预测,而 Batch Size 太小又会导致 BN 层计算的均值和方差不符合原始图像的分布。因此,在 3D-DA-Unet 中需要使用 IN 层来对输入图像实例进行标准化,不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立))层进行特征归一化,并使用 Leaky ReLU(由于常用的激活函数 ReLU 是将特征图中所有的负值都设为零,而对于经过标准化的脑胶质瘤输入而言,存在小于 0 的强度值,因此需要使用 Leaky ReLU来给所有负值变量赋予一个非零的斜率,从而消除使用 ReLU 函数带来的梯度消失现象) 激活函数添加非线性特征。
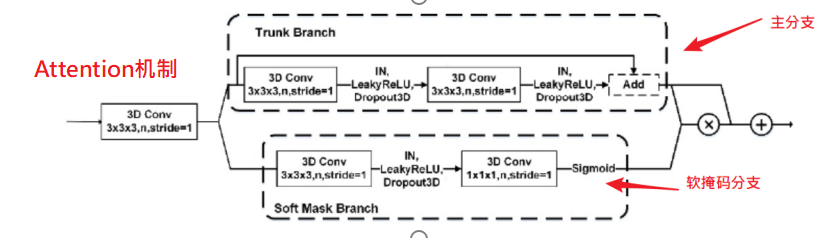
其中,主干分支用于学习原始特征,而软掩模分支则用于减少噪声和增强特征。
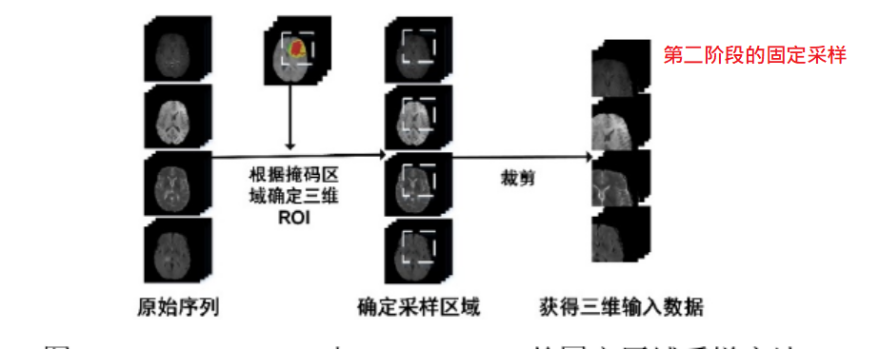
① 数据预处理:在第一阶段,对每个序列的每一层进行随机采样得到4*128*128大小,在第二阶段,通过掩码获得感兴趣区域(ROI)并适当增大,将增大的ROI区域进行固定区域采样,即以脑胶质瘤的中心作为ROI的中心,取128*128大小,得到128*128*128的立方体,因此,第二阶段的输入为128*128*128*4
② 标准化:第二阶段标准化

对背景添加随机噪声,如下图所示:

③ 数据增强:首先,在 3D-DA-Unet 训练过程中对输入的三维立方体数据进行在线数据增强,即对输入的 4*128*128*128 的数据进行 x,y,z 轴上的三维旋转,以及 x,y,z 轴上的随机翻转等六种增强方式的数据增强,从而得到6*4*128*128*128 的增强数据,并将这些增强数据用于 3D-DA-Unet 模型的训练。 然后,3D-DA-Unet 对数据的预测过程中,使用与模型训练过程相同的 6 种随机增强方式,从而得到 6 个 TTA 增强之后的测试数据,并将 6 个增强之后的数据通过使用 TTA 数据增强训练得到的模型进行预测,因此得到 6 个预测结果。然后,将这些预测结果还原为同样的视图和方向,并对它们进行求和然后取均值,就能得到多个预测结果的融合结果,即 TTA 数据增强的模型预测结果
④ 训练:二者单独训练
⑤ 预测:在第一阶段,使用 2DDenseUnet 的网络结构,对需要预测的多序列三维图像进行逐层分割,从而得到 2DDenseUnet 分割的脑胶质瘤掩码。由于此时获得的2DDenseUnet 分割掩码具有很高的敏感性,因此可以通过获取 2DDenseUnet 掩码的三维边界框进而得到脑胶质瘤区域的中心位置,并以该中心位置取一个 128*128*128的三维边界框,并从 4 个输入序列中获得用于下一阶段分割的三维数据。 在第二阶段,通过第一阶段得到的三维边界框,可以在不同序列上得到相同的三维区域,并通过裁剪得到不同序列的三维立方体。然后,将多个序列的三维立方体作为 3D-DA-Unet 的输入图像,并将该输入图像通过 3D-DA-Unet 预测进而得到最终的掩码,由于在 3D-DA-Unett 网络中采用了三维卷积进行特征采样,并使用多视图融合为基础的 TTA(Test Time Augment)作为数据增强方式,因此可以很好脑胶质瘤区域的空间信息,在第一阶段获得的三维区域中对脑胶质瘤区域进行更加精确的分割,获 4*128*128*128 的脑胶质瘤多区域分割结果,并将三个脑胶质瘤分割区域和背景区域进行融合,从而得到 1*128*128*128 的预测结果。最后,在对脑胶质瘤预测结果进行后处理之后,可以将该结果映射尺寸大小为 240*240*155 的原始图像中,从而获得最终的脑胶质瘤分割掩码
参考文献:基于深度学习的脑胶质瘤分割方法研究_庄宇舟_华中科技大学