本文是本系列的第二篇博客,内容是分析non-VCLU解码的相关代码。
该系列相关博客为:
VVC/H.266代码阅读(VTM8.0)(一. NALU提取)
VVC/H.266代码阅读(VTM8.0)(二. non-VCLU解码)
VVC/H.266代码阅读(VTM8.0)(三. Slice到CTU的处理 )
VVC/H.266代码阅读(VTM8.0)(四. CU划分 )
VVC/H.266常见资源为:
VVC/H.266常见资源整理(提案地址、代码、资料等)
注:
- 考虑到从解码端分析代码,一是更加简单(解码流程无需编码工具和编码参数的择优),二是可以配合Draft文本更好地理解视频编解码的流程(解码端也都包含预测、量化、环路滤波、熵解码等流程),所以本系列从解码端入手分析VVC解码大致流程。等到解码端代码分析完后,再从编码端深入分析。
- 本文分析的bin文件是利用VTM8.0的编码器,以All Intra配置(IBC 打开)编码100帧得到的二进制码流(TemporalSubsampleRatio: 8,实际编码 ⌈100 / 8⌉ = 13帧)。
- 解码用最简单的:-b str.bin -o dec.yuv
在上一篇博客中,我分析了解码端将收到的二进制码流bin文件提取成一个个NALU的过程。上一篇博客的最后写道 “ 调用DecLib::decode()进行当前NALU的核心解码流程。该函数内,会根据当前NALU的类型进行针对性地解码。” 本篇博客就是对该函数的部分展开,即针对non-VCLU解码进行分析,如SPS、PPS等non-VCLU。
1. 什么是non-VCLU?non-VCLU一般包含什么内容?
(1) 万帅老师在书籍《新一代高效视频编码H.265HEVC原理、标准与实现》的第三章51页有过以下介绍:
NAL单元根据是否装载视频编码数据被分为VCLU和non-VCLU。
非编码数据的参数集作为non-VCLU进行传输,为传递关键数据提供了高鲁棒机制。
参数集的独立使得其可以提前发送,也可以在需要增加新参数集的时候再发送,可以被多次重发或者采用特殊技术加以保护,甚至采用带外(Out-of-band)发送的方式。
(2) 也就是说,non-VCLU内部一般装载了VPS、SPS、PPS等参数信息。这部分数据非常重要,所以优先级也比较高,draft里有过以下要求:
The value of TemporalId for non-VCL NAL units is constrained as follows:
// non-VCLU的时域ID要求如下(0为最高级,增加优先级下降):
– If nal_unit_type is equal to DCI_NUT, VPS_NUT, or SPS_NUT, TemporalId shall be equal to 0 and the TemporalId of the AU containing the NAL unit shall be equal to 0.
// DCI、VPS、PPS的时域ID应该设为0。
– Otherwise, if nal_unit_type is equal to PH_NUT, TemporalId shall be equal to the TemporalId of the PU containing the NAL unit.
– Otherwise, if nal_unit_type is equal to EOS_NUT or EOB_NUT, TemporalId shall be equal to 0.
– Otherwise, if nal_unit_type is equal to AUD_NUT, FD_NUT, PREFIX_SEI_NUT, or SUFFIX_SEI_NUT, TemporalId shall be equal to the TemporalId of the AU containing the NAL unit.
– Otherwise, when nal_unit_type is equal to PPS_NUT, PREFIX_APS_NUT, or SUFFIX_APS_NUT, TemporalId shall be greater than or equal to the TemporalId of the PU containing the NAL unit.
注:关于代码和草案的下载地址,可以参考:
VVC/H.266常见资源整理(提案地址、代码、资料等)
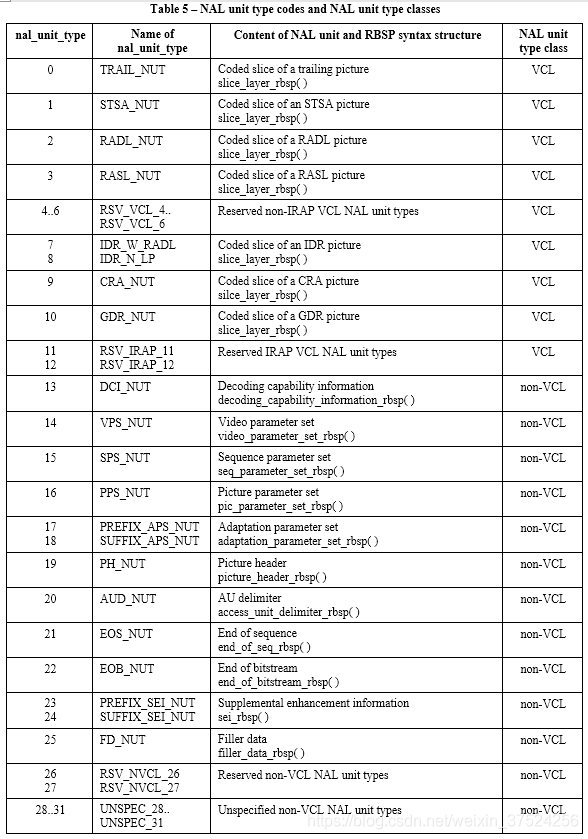
我们再看看draft(我参考的是JVET-Q2001-vE)里面non-VCLU的大致内容,可以参考7.4.2.2 Table 5 – NAL unit type codes and NAL unit type classes。
2. non-VCLU解码代码分析
(1) 细节回顾:
- 和上一篇博客VVC/H.266代码阅读(VTM8.0)(一.NALU提取)使用的bin文件相同,从00 00 00 01开始到DC 0D 56 81是一个NALU的内容。

- 在提取完该NALU的数据后,调用read() 、readNalUnitHeader()函数分析了该NALU的NalUnitHeader。该NALU中,除去前缀和起始码,前两个字节为0x00 和 0x79 (01111 001),所以nal_unit_type为 01111 = 15 (SPS_NUT),时域ID为0最高级。该部分相关代码在上一篇博客中分析过。

(2) 现在从DecLib::decode()分析。
① 首先,根据nal_unit_type调用不同的函数针对性地解码。以该NALU为例,nalu是SPS,调用xDecodeSPS( nalu );
switch (nalu.m_nalUnitType)
{
case NAL_UNIT_VPS:
xDecodeVPS( nalu );
return false;
case NAL_UNIT_DPS:
xDecodeDPS( nalu );
return false;
case NAL_UNIT_SPS:
xDecodeSPS( nalu );
return false;
case NAL_UNIT_PPS:
xDecodePPS( nalu );
return false;
case NAL_UNIT_PH:
xDecodePicHeader(nalu);
return !m_bFirstSliceInPicture;
case NAL_UNIT_PREFIX_APS:
case NAL_UNIT_SUFFIX_APS:
xDecodeAPS(nalu);
return false;
case NAL_UNIT_PREFIX_SEI:
m_prefixSEINALUs.push_back(new InputNALUnit(nalu));
return false;
case NAL_UNIT_SUFFIX_SEI:
if (m_pcPic)
{
m_seiReader.parseSEImessage( &(nalu.getBitstream()), m_pcPic->SEIs, nalu.m_nalUnitType, nalu.m_temporalId, m_parameterSetManager.getActiveSPS(), m_HRD, m_pDecodedSEIOutputStream );
}
else
{
msg( NOTICE, "Note: received suffix SEI but no picture currently active.\n");
}
return false;
case NAL_UNIT_CODED_SLICE_TRAIL:
case NAL_UNIT_CODED_SLICE_STSA:
case NAL_UNIT_CODED_SLICE_IDR_W_RADL:
case NAL_UNIT_CODED_SLICE_IDR_N_LP:
case NAL_UNIT_CODED_SLICE_CRA:
case NAL_UNIT_CODED_SLICE_GDR:
case NAL_UNIT_CODED_SLICE_RADL:
case NAL_UNIT_CODED_SLICE_RASL:
ret = xDecodeSlice(nalu, iSkipFrame, iPOCLastDisplay);
return ret;
case NAL_UNIT_EOS:
m_associatedIRAPType = NAL_UNIT_INVALID;
m_pocCRA = 0;
m_pocRandomAccess = MAX_INT;
m_prevLayerID = MAX_INT;
m_prevPOC = MAX_INT;
m_prevSliceSkipped = false;
m_skippedPOC = 0;
return false;
case NAL_UNIT_ACCESS_UNIT_DELIMITER:
{
AUDReader audReader;
uint32_t picType;
audReader.parseAccessUnitDelimiter(&(nalu.getBitstream()),picType);
return !m_bFirstSliceInPicture;
}
case NAL_UNIT_EOB:
return false;
case NAL_UNIT_RESERVED_IRAP_VCL_11:
case NAL_UNIT_RESERVED_IRAP_VCL_12:
msg( NOTICE, "Note: found reserved VCL NAL unit.\n");
xParsePrefixSEIsForUnknownVCLNal();
return false;
case NAL_UNIT_RESERVED_VCL_4:
case NAL_UNIT_RESERVED_VCL_5:
case NAL_UNIT_RESERVED_VCL_6:
case NAL_UNIT_RESERVED_NVCL_26:
case NAL_UNIT_RESERVED_NVCL_27:
msg( NOTICE, "Note: found reserved NAL unit.\n");
return false;
case NAL_UNIT_UNSPECIFIED_28:
case NAL_UNIT_UNSPECIFIED_29:
case NAL_UNIT_UNSPECIFIED_30:
case NAL_UNIT_UNSPECIFIED_31:
msg( NOTICE, "Note: found unspecified NAL unit.\n");
return false;
default:
THROW( "Invalid NAL unit type" );
break;
}
② 进入DecLib::xDecodeSPS()。
void DecLib::xDecodeSPS( InputNALUnit& nalu )
{
SPS* sps = new SPS();
//创建SPS
m_HLSReader.setBitstream( &nalu.getBitstream() );
//将nalu内读取出的码流信息放入m_HLSReader中,HLS是高层语法的缩写
m_HLSReader.parseSPS( sps );
//解析SPS
m_parameterSetManager.storeSPS( sps, nalu.getBitstream().getFifo() );
//m_parameterSetManager中存储相关的参数集
}
此时,按照draft 7.3.2.3 和 7.4.3.3相关的章节进行SPS的解码。(仅截取部分)

void HLSyntaxReader::parseSPS(SPS* pcSPS)
{
uint32_t uiCode;
READ_CODE(4, uiCode, "sps_decoding_parameter_set_id"); pcSPS->setDecodingParameterSetId( uiCode );
READ_CODE(4, uiCode, "sps_video_parameter_set_id" ); pcSPS->setVPSId( uiCode );
READ_CODE(3, uiCode, "sps_max_sub_layers_minus1"); pcSPS->setMaxTLayers (uiCode + 1);
READ_CODE(4, uiCode, "sps_reserved_zero_4bits");
READ_FLAG(uiCode, "sps_ptl_dpb_hrd_params_present_flag"); pcSPS->setPtlDpbHrdParamsPresentFlag(uiCode);
……
其中,READ_CODE()核心调用了InputBitstream::read() 函数,是连续读取无符号n位。READ_UVLC()是0阶指数哥伦布编码。下面详细分析二者代码。
u(n): unsigned integer using n bits.
ue(v): unsigned integer 0-th order Exp-Golomb-coded syntax element with the left bit first.
void InputBitstream::read (uint32_t uiNumberOfBits, uint32_t& ruiBits)
{
//uiNumberOfBits就是读n位,ruiBits返回参数值。
m_numBitsRead += uiNumberOfBits;
//m_numBitsRead 记录了读过bits的位数。
//比如说,如果用u(4)解析SPS的第一个语法sps_seq_parameter_set_id。之前读取NALU header使用了2个Bytes = 16bits,所以解析完该4个bits后,该值会变成20。
uint32_t retval = 0;
if (uiNumberOfBits <= m_num_held_bits)
{
//m_num_held_bits 记录了一个完整的Byte剩下未读完的位数。
//比如说,之前只读了1个bit,所以m_num_held_bits = 8 - 1 = 7,如果现在要读的位数 < 7(m_num_held_bits), 直接位操作读取出来即可。
//下面X表示已读位,VH是未读位,V是需要读的位数
//n=1, len(H)=7: -X(已读位) VHH HHHH, shift_down=6, mask=0xfe=11111110
//n=3, len(H)=7: -X(已读位) VVV HHHH, shift_down=4, mask=0xf8=11111000
retval = m_held_bits >> (m_num_held_bits - uiNumberOfBits);
//m_held_bits表示了该Byte的数据。
//右移m_num_held_bits - uiNumberOfBits,排除后面不用读的bits
retval &= ~(0xff << uiNumberOfBits);
//利用mask读取需要的数据
m_num_held_bits -= uiNumberOfBits;
//m_num_held_bits 记录了一个完整的Byte剩下未读完的位数。进行更新。
ruiBits = retval;
return;
}
//m_num_held_bits 记录了一个完整的Byte剩下未读完的位数。能进行下面步骤,说明超过了目前的Byte范围,目前Byte留下的有效未读bits需要全部读取。
//下面X表示已读位,V是该Byte需要读的位数, H是后续Bytes需要读的bits
//n=5, len(H)=3: ---- -XXXXX(已读位) VVV HH, mask=0x07, shift_up=5-3=2,
//n=9, len(H)=3: ---- -XXXXX(已读位) VVV HHHHHH, mask=0x07, shift_up=9-3=6
uiNumberOfBits -= m_num_held_bits;
//减去剩下的bits, uiNumberOfBits变成后续Bytes需要读的bits
retval = m_held_bits & ~(0xff << m_num_held_bits);
//利用mask读取需要的数据
retval <<= uiNumberOfBits;
//左移uiNumberOfBits,方便和后面bits进行拼接
/* number of whole bytes that need to be loaded to form retval */
/* n=32, len(H)=0, load 4bytes, shift_down=0
* n=32, len(H)=1, load 4bytes, shift_down=1
* n=31, len(H)=1, load 4bytes, shift_down=1+1
* n=8, len(H)=0, load 1byte, shift_down=0
* n=8, len(H)=3, load 1byte, shift_down=3
* n=5, len(H)=1, load 1byte, shift_down=1+3
*/
uint32_t aligned_word = 0;
uint32_t num_bytes_to_load = (uiNumberOfBits - 1) >> 3;
//num_bytes_to_load 看看还需要后续几个Bytes进行拼接读取
switch (num_bytes_to_load)
{
//根据num_bytes_to_load,从码流里读取出来对应数量的Bytes
case 3: aligned_word = m_fifo[m_fifo_idx++] << 24;
case 2: aligned_word |= m_fifo[m_fifo_idx++] << 16;
case 1: aligned_word |= m_fifo[m_fifo_idx++] << 8;
case 0: aligned_word |= m_fifo[m_fifo_idx++];
}
uint32_t next_num_held_bits = (32 - uiNumberOfBits) % 8;
//next_num_held_bits是读取完后续Bytes后,最后一个Byte还剩几个未读的bits
retval |= aligned_word >> next_num_held_bits;
//右移next_num_held_bits,就是读取到的后续Bytes的相关数据,进行拼接
m_num_held_bits = next_num_held_bits;
//m_num_held_bits 记录了一个完整的Byte剩下未读完的位数。也就是next_num_held_bits。
m_held_bits = aligned_word;
//截断aligned_word的最后一个Byte,赋给m_held_bits
ruiBits = retval;
}
READ_UVLC()是0阶指数哥伦布编码,流程很简单,简单的处理前缀后缀即可。
万帅老师在书籍《新一代高效视频编码H.265HEVC原理、标准与实现》的第八章236页有过以下介绍:


void VLCReader::xReadUvlc( uint32_t& ruiVal, const char *pSymbolName)
{
uint32_t uiVal = 0;
uint32_t uiCode = 0;
uint32_t uiLength;
m_pcBitstream->read( 1, uiCode );
//读第一个bit
if( 0 == uiCode )
{
uiLength = 0;
while( ! ( uiCode & 1 ))
{
m_pcBitstream->read( 1, uiCode );
uiLength++;
//读取前缀连续0的个数,如果有0,一直往下读
}
m_pcBitstream->read( uiLength, uiVal );
//读取后缀,此处后缀bits数目就是前缀的连续0的个数uiLength。
uiVal += (1 << uiLength)-1;
//根据公式,后缀 + 前缀 - 1
}
ruiVal = uiVal;
}
从上可知,SPS语法主要的编码方法u(n)和ue(v)已经分析完毕。
VPS、PPS等其他non-VCLU的解码原理基本相同,此处不再赘述。
在下一篇博客中,会展开分析VCLU中CU划分的相关代码,敬请期待。