1.hashMap
参考:
HashMap中hash(Object key)原理,为什么(hashcode >>> 16) :http://www.fu-w.com/a/63569.html
1.1 结构
数据 + 链表 +红黑树
线性链表:增 删除仅处理结点,时间复杂度O(1)查找需要遍历也就是O(n)
二叉树:对一颗相对平衡的有序二叉树,对其进行插入,查找,删除,平均复杂度O(logn)
哈希表:哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1)哈希表的主干就是数组
1.1 为什么加载因子 设置为0.75
当加载因子越大数组的利用率越高,但hash碰撞将越大,经计算 0.75 是一个理想值,数组利用率高 hash碰撞低
1.2 为什么链表长度大于8 转化为红黑树
根据泊松定律,当链表长度为8的时候落入该index的概率1亿万分之一
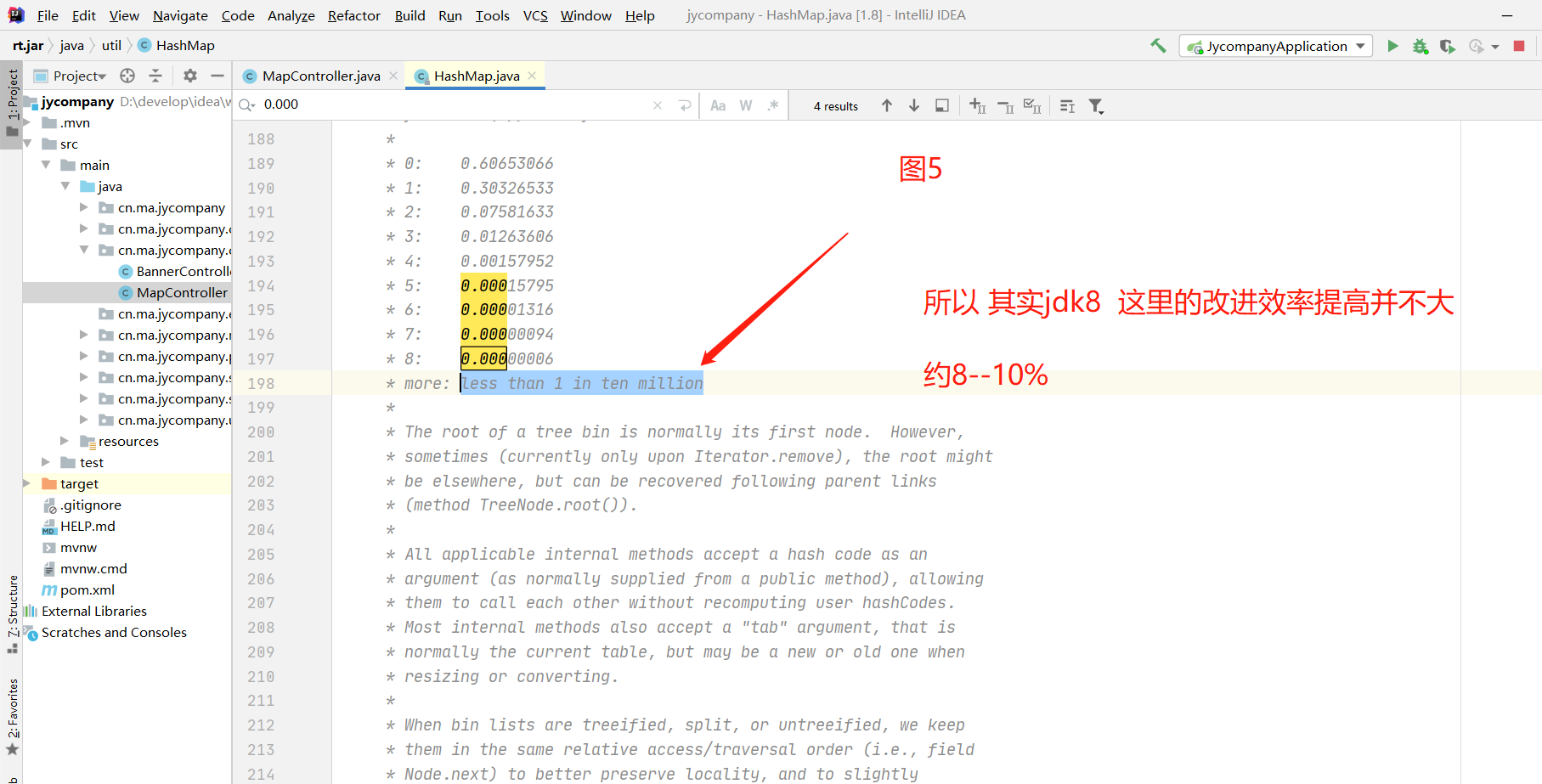
1.3 红黑树 结构有什么好处
减少了时间复杂度: 链表平均复杂度O(n) 树结构平均复杂度O(logn)
1.4 为什么hash计算要 高低位进行异或运算 (h = key.hashCode()) ^ (h >>> 16)
目的: 让得到的下标更加散列
hashcode为四字节 所以 一共32(4*8) 位
平时用map大多数情况下map里面的数据不是很多。这里与(length-1)相&,但由于绝大多数情况下length一般都小于2^16即小于65536。所以return h & (length-1);结果始终是h的低16位与(length-1)进行&运算
为什么用^而不用&和| ???
因为&和|都会使得结果偏向0或者1 ,并不是均匀的概念,所以用^
补充: 与运算(&)、或运算(|)、异或运算(^)
与运算(&):两个同时为1,结果为1,否则为0
或运算(|):参加运算的两个对象,一个为1,其值为1。
异或运算(^):参加运算的两个对象,如果两个位为“异”(值不同),则该位结果为1,否则为0
1.2 初始化大小
1.2.1 开发者没有设置初始值
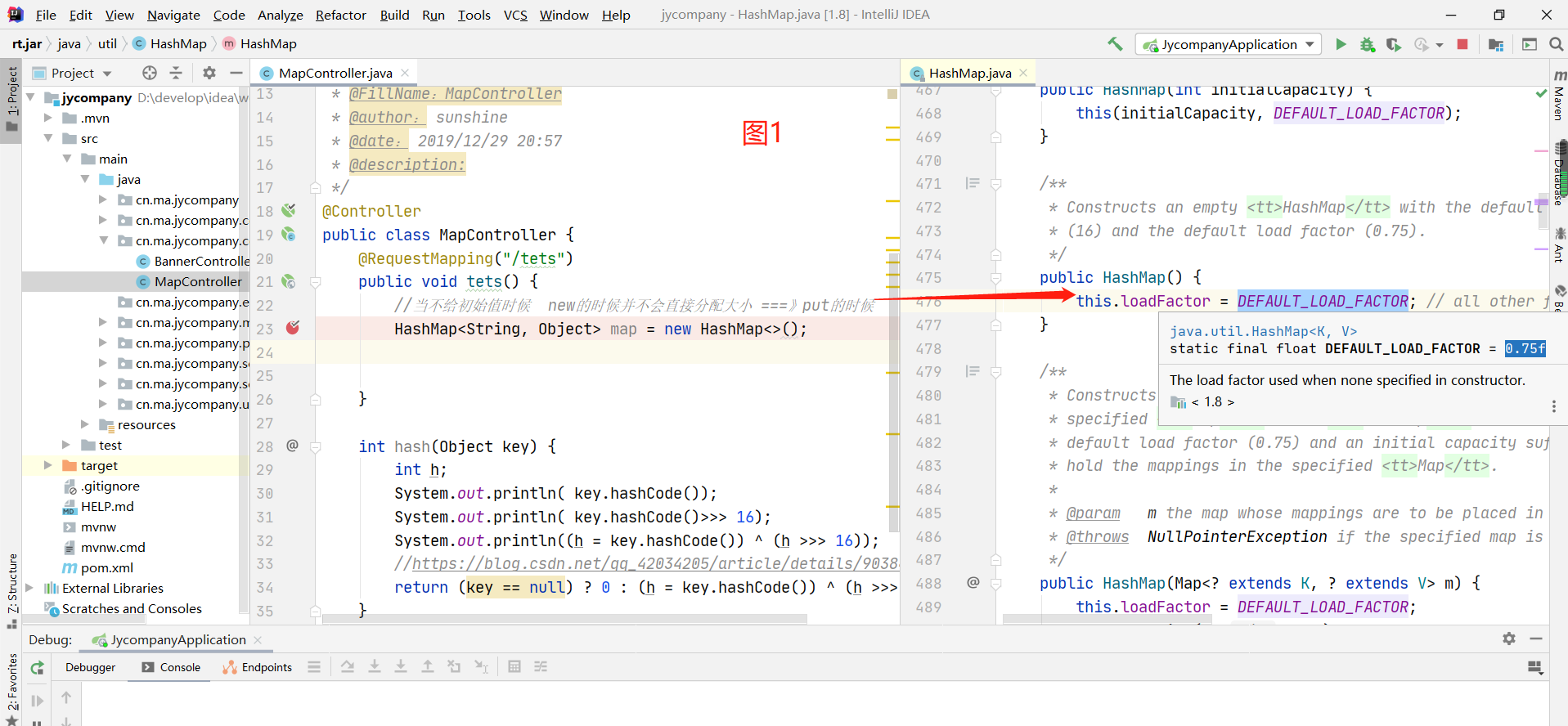
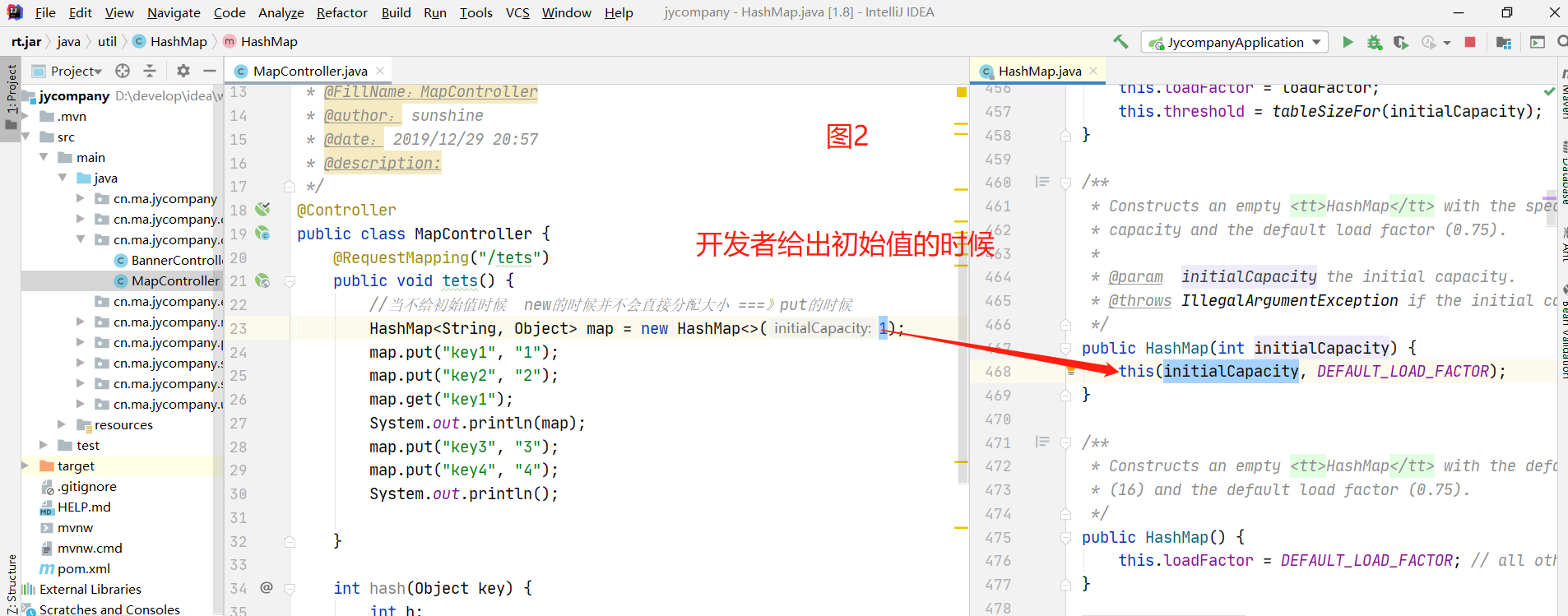
1.2.2 开发这给出了初始值
若开发者给出的非2的幂次方,hashMap会将初始值设置位大于且最接近初始值的2的幂次方
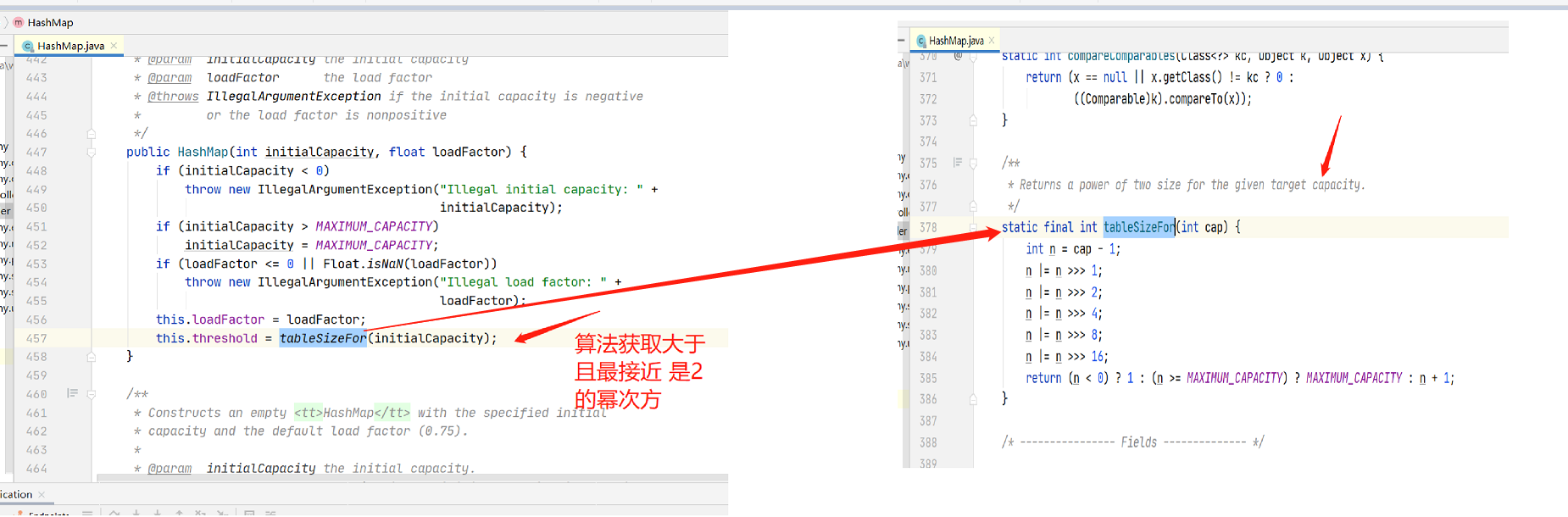
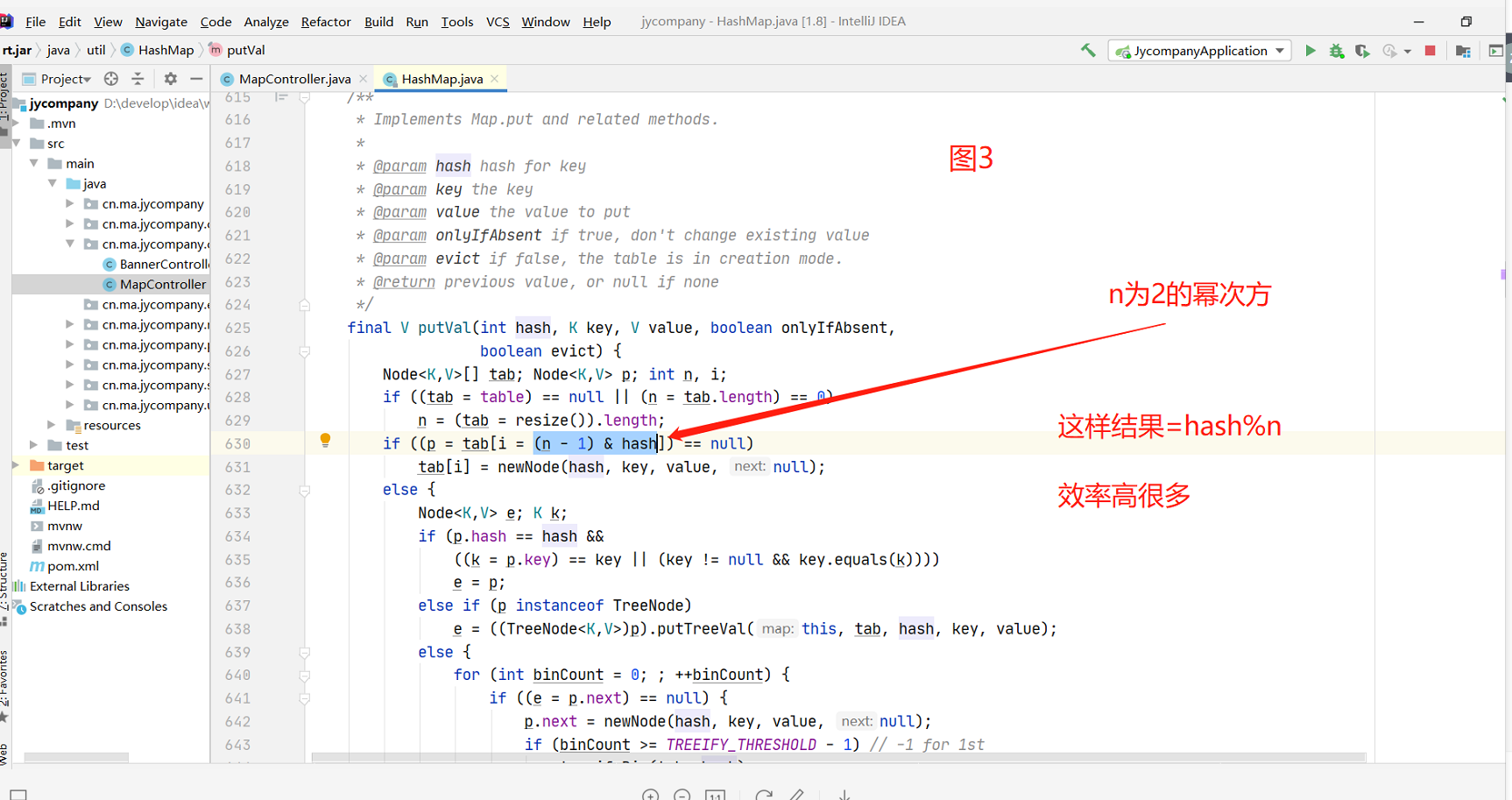
1.2.3 为什么初始化要是2的幂次方???
1.在计算key值的index时候通过与运算(&)与取模方式结果相同,但是与运算效率高很多(计算机底层是2进制) 如图3
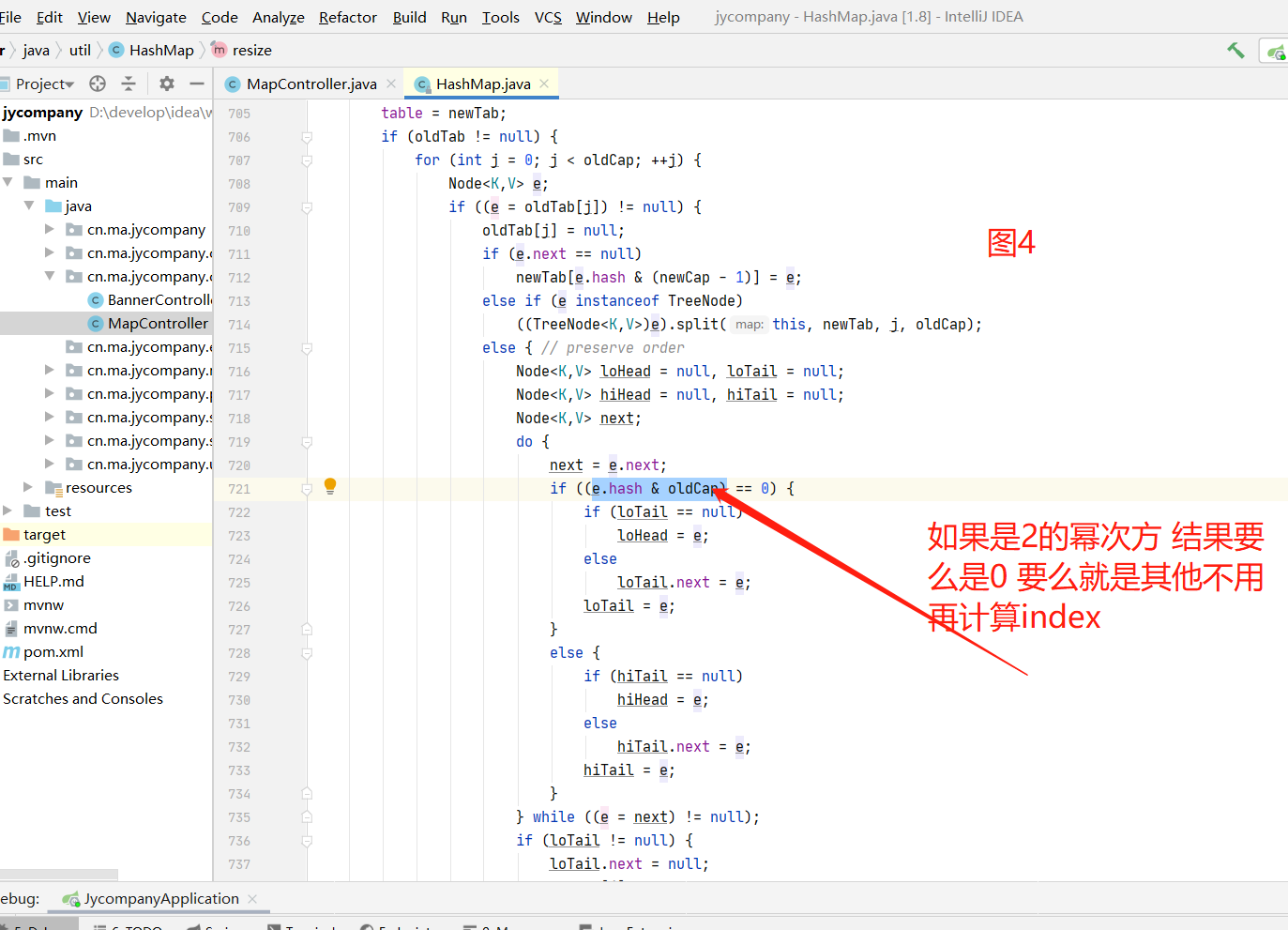
2.jdk 1.8的扩容时候对数据迁移用到了高低位,不需要再去rehash效率高了很多 如图4
文章分享完毕,希望我的分享对大家有所帮助。更多学习技巧也可参阅:网站源码、模板、教程