我们在做自动化的时候应该都听过PO模型,那么什么是PO模型呢?PO模型在自动化中的作用是什么呢?
PO模型
PO其实就是:、Page Object Model,也称作为POM模型,PO其实是一种设计模式,已经在自动化测试中流行起来,以增强测试维护并减少代码重复。页面对象是面向对象的类,用作页面的接口和被测设备。 然后,只要测试需要与该页面的UI进行交互,这些测试便会使用该页面对象类的方法,其好处在于,如果页面的UI发生了更改,则无需更改测试本身,只需更改其中的代码即可。页面对象需要更改。 随后,所有支持该新UI的更改都位于一个位置。其实说到低就是一句话:把每一个页面当作一个类,把页面上的元素信息和代码操作分离开,然后方面后面我们进行管理代码和元素内容
PO分层
PO分层也就是对我们自动化代码进行分层具体可以分为以下基层
1、基础层:封装一些定位方法,点击,输入,滑动等操作
2、公用层:获取元素方法,操作元素方法,获取CMD信息等方法
3、业务层:页面元素信息。
4、逻辑层:一些功能,比如登录,注册。
5、数据层:测试信息存放地方
emmm,这里是安静这边自身的了解,当然可能每个人对PO分层的理解不同,可能大佬们分的比我这里更加详细。(一起分享,共同学习)
这里安静简单拿项目来进行实际介绍下PO内容
首先我们先看以前如何编写测试用例的
# coding:utf-8 from appium import webdriver import time import unittest class login(unittest.TestCase): def setUp(self): desired_caps = { 'platformName': 'Android', # 测试版本 'deviceName': 'emulator-5554', # 设备名 'platformVersion': '5.1.1', # 系统版本 'appPackage': 'com.taobao.taobao', #apk的包名 'appActivity': 'com.ali.user.mobile.login.ui.UserLoginActivity', # apk的launcherActivity 'noReset':True , # 清除缓存 } self.driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_caps) def tearDown(self): self.driver.quit() def test01(self): ''' 账号密码错误 ''' self.driver.implicitly_wait(40) self.driver.find_element_by_id("com.eboss2.sbs:id/tv_username").send_keys("22222") time.sleep(2) self.driver.find_element_by_id("com.eboss2.sbs:id/tv_password").send_keys("33333333") time.sleep(2) self.driver.find_element_by_id("com.eboss2.sbs:id/btn_login").click() time.sleep(5) x = self.driver.find_element_by_id("com.eboss2.sbs:id/shopName_TextView").text print(x) self.assertEqual(x,'请输入正确的手机号') if __name__ == '__main__': unittest.main()
相信绝大部分的同学,第一次写代码的时候都会这样写测试用例
PO模型设计框架
肯定有人会问?什么是自动化框架?自动化框架有什么好处呢?这个地方我们先不说答案,我们后面写
首先把安静这边设计的框架先整体列出来,一个个为大家分析
appium_python # 目标工程 - case # 用例存放 test_login.py # 编写用例 - common # 公用方法 appium_start.py # 启动appium Base.py # 封装基础内容 dos_cmd.py # cmd执行 HTmlTestRunner.py # 报告文件 logger.py # 日志 read_yaml.py # 读取yaml文件 - config # 页面元素存放 appium.py # login页面存放 - function # 功能点 login.py # 登录逻辑 - logs # 日志存放内容 - pages # 获取页面元素信息 login_page.py # 获取登录元素信息 -report # 报告存放地方 runTest.py # 主函数
我们这里需要这么多内容,才能完成上面的简单的操作。
config目录
这里我们主要存放一些页面元素信息,前面也写了两种方法进行封装页面元素
# appium.yaml
LoginPage: dec: 登录 locators: - name: 用户名 type: id value: com.taobao.taobao:id/aliuser_login_mobile_et - name: 密码 type: android value: resourceId("com.taobao.taobao:id/aliuser_register_sms_code_et") - name: 登录按钮 type: className value: android.widget.Button
想象下,元素信息有了,我们是不是需要进行读取元素信息。读取元素信息的时候,是不是又需要通过PO模型的方法,把每个页面的元素都列举出来
common目录
common目录中包含一些公用的部分,比如读取yaml方法,执行cmd内容,appium中常用的方法等操作
# read_yaml.py import yaml import os class GetYaml(): def __init__(self,file_path): # 判断文件是否存在 if os.path.exists(file_path): self.file_path = file_path else: print('没有找到%s文件路径'%file_path) self.data = self.read_yaml() def read_yaml(self): with open(self.file_path,'r',encoding='utf-8')as f: p = f.read() return p def get_data(self,key=None): result = yaml.load(self.data,Loader=yaml.FullLoader) if key == None: return result else: return result.get(key) if __name__ == '__main__': read_yaml = GetYaml('E:/appium_python/config/appium.yaml') xx = read_yaml.get_data('LoginPage') print(xx['locators'])
pages目录
这里我们把每个类中都代表一个页面,获取页面上的所有信息
# coding:utf-8 from common.Base import BaseApp import os from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from common.loger import Logger path = os.path.dirname(os.path.realpath(__file__)) yaml_path = os.path.join(os.path.join(os.path.dirname(path),'config'),'appium.yaml') class Login_element: def __init__(self,driver): self.log = Logger('element.py') self.driver = driver self.get_element = BaseApp(self.driver) def user_element(self): ''' 获取用户名元素''' self.log.info('正在获取用户名元素信息---------------------------------------') element = self.get_element.get_element(yaml_path,'LoginPage')['locators'][0] self.log.info('用户名元素信息为:%s'%element) return element def password_element(self): ''' 获取密码元素''' self.log.info('正在获取用户名元素信息-------------------------------------') element = self.get_element.get_element(yaml_path,'LoginPage')['locators'][1] self.log.info('密码元素信息为:%s'%element) return element def login_boot(self): ''' 获取登录按钮元素''' self.log.info('正在获取用户名元素信息-------------------------------------') element = self.get_element.get_element(yaml_path,'LoginPage')['locators'][2] self.log.info('登录按钮元素信息为:%s'%element) return element def toast(self,message): '''获取toast信息''' toast_loc = ("xpath", ".//*[contains(@text,'%s')]"%message) element = WebDriverWait(self.driver, 30, 0.1).until(EC.presence_of_element_located(toast_loc)).text return element
页面用例元素都已经全部获取出来了,那么我们可以通过封装一些操作内容,比如说登录,注册,然后直接把我们的数据存放进去
function目录
function目录表示每个测试点,例如、;登录和注册全部都单独封装起来,用的时候,可以直接进行调用
# login.py # coding:utf-8 from pages.login_page2 import Login_element class LoginTest: def __init__(self,driver): self.element = Login_element(driver) self.app = self.element.get_element
def login(self,username,password): self.app.send_text(self.element.user_element(),username) self.app.send_text(self.element.password_element(),password) self.app.click(self.element.login_boot())
case目录
case表示存放测试用例的目录
# test_login.py from function.login import LoginTest from common.appium_start import start import unittest import threading import time from common.loger import Logger import warnings warnings.simplefilter("ignore", ResourceWarning) class BaseDriver(unittest.TestCase): @classmethod def setUpClass(cls): '''启动apk''' cls.log = Logger('anjing') cls.log.info('app启动中') cls.driver = start() cls.log.info('app启动完成') cls.login = LoginTest(cls.driver) def test01(self): '''账号密码错误''' self.log.info('用例名称:账号密码错误,测试数据:账号名:11111,密码:22222,') self.login.login('11111','22222') element= self.login.element.toast('手机号') self.log.info('test01获取toast信息为:%s'%element) self.assertEqual(element,'请输入正确的手机号') def test02(self): '''账号密码错误1''' self.log.info('用例名称:账号密码错误1,测试数据:账号名:222,密码:33333,') self.login.login('2222','33333') element= self.login.element.toast('手机号') self.log.info('test02获取toast信息为:%s' %element) self.assertEqual(element,'请输入正确的手机号') @classmethod def tearDownClass(cls): '''退出APK''' cls.driver.quit() if __name__ == '__main__': t1 = threading.Thread(target=start) t1.start() time.sleep(20) t2 = threading.Thread(target=unittest.main()) t2.start()
logs目录
logs表示执行用例过程中,存放自己打印的日志地方和appium日志
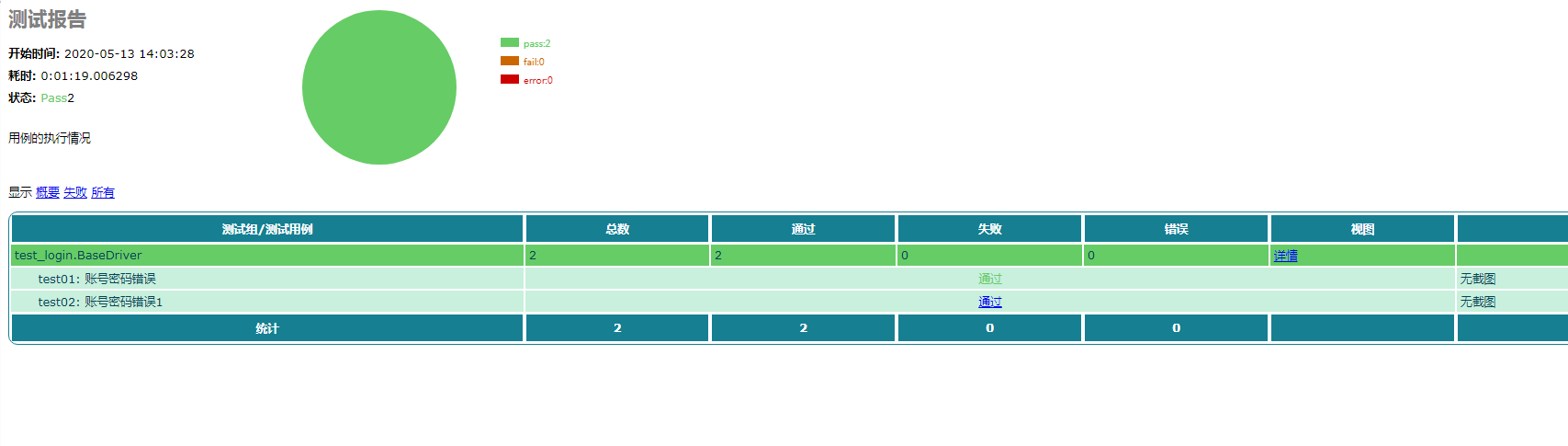
report目录
report表示存放测试报告的位置
runTest.py文件
这个主执行文件,用来执行所有的用例,生成测试报告,发送邮件。
# coding:utf-8 import unittest from common import HTMLTestRunner_cn import time import os import smtplib import threading from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from common.appium_start import start import warnings warnings.simplefilter("ignore", ResourceWarning) # 脚本路径 path = os.path.dirname(os.path.realpath(__file__)) # case用例 case_path = os.path.join(path,'case') # 执行用例 返回discover def add_case(rule="test*.py"): '''加载所有的测试用例''' # 如果不存在这个case文件夹,就自动创建一个 if not os.path.exists(case_path):os.mkdir(case_path) # 定义discover方法的参数 discover = unittest.defaultTestLoader.discover(case_path, pattern=rule, top_level_dir=None) return discover # 执行报告 def run_case(discover): report_path = os.path.join(path,'report') now = time.strftime("%Y-%m-%d-%H-%M-%S") # 最新的报告 report_abspath = os.path.join(report_path, now+"result.html") # 报告的位置 rp=open(report_abspath,"wb") runner=HTMLTestRunner_cn.HTMLTestRunner(rp, title=u"测试报告", description=u"用例的执行情况") runner.run(discover) return report_abspath def sen_mail(file_path): smtpserver = 'smtp.163.com' # 发送邮箱用户名密码 user = '[email protected]' password = 'xxxxxx' # 发送邮箱 sender = '[email protected]' # 接收邮箱 receiver ='[email protected]' #导入报告 with open(file_path, "rb") as fp: mail_body = fp.read() msg=MIMEMultipart() body=MIMEText(mail_body,_subtype="html",_charset="utf-8") msg['Subject']=u'自动化测试报告' msg['from']=sender # 发送邮件 msg['to']=receiver # 接手邮件 msg.attach(body) att = MIMEText(mail_body, "base64", "utf-8") # 生成附件 att["Content-Type"] = "application/octet-stream" att["Content-Disposition"] = 'attachment; filename="report.html"' # 生成附件名称 msg.attach(att) smtp = smtplib.SMTP() smtp.connect(smtpserver) # 连接服务器 smtp.login(user,password) # 登录服务器 # 发送邮件 split(',')分隔符 smtp.sendmail(sender, receiver.split(','), msg.as_string()) # 关闭 print ("邮件发送") def main(): discover = add_case() # 调用执行 执行用例 file_path = run_case(discover) # 用例生成报告 # sen_mail(file_path) # 发送报告 if __name__=="__main__": # add_case() t1 = threading.Thread(target=start) t1.start() time.sleep(20) t2 = threading.Thread(target=main) t2.start()
整体的PO模型设计都已经理完了,相信大家肯定都会有一种体验,怎么感觉原始的方法比较简单,代码还少,还简单,但是如果测试用例较多呢?那么是不是觉得这样方法就很简单,很已读。
这里我们在回复前面留下的那个问题? 自动化框架有什么用?
如果自动化框架建立起来了,那么组里一些代码基础比较弱的同学,都可以自己进行按照一个模板进行编写测试用例。如果页面元素或者UI发生了变化,我们只需要找到对应的page和元素信息进行修改,这样就可以继续保持以前的用例了。
那么当中PO模型也占了很大的用途,很清楚的使我们代码更加简洁,已读。也方便维护。
通过上面的内容,相信大家对PO模型有了简单的了解,也相信大家都有不同的分层,这里可以留言一起进行讨论,学习更多方便简单的方法