1:一般互联网项目中mysql的事务隔离级别设置成 Read Commited 读已提交
Oracle,SqlServer 的默认事务隔离级别是读已提交(Read Commited);
Mysql 的默认事务隔离级别是可重复读(Repeatable Read);
为什么mysql的默认事务级别设置成Repeatable Read?
答:历史原因
下面分析读已提交(Read Commited)和可重复读(Repeatable Read)这两种隔离级别的效果
为了便于描述,下面将
- 可重复读(Repeatable Read),简称为RR;
- 读已提交(Read Commited),简称为RC;
我们为什么选读已提交(Read Commited)作为事务隔离级别!
先搞一个表和数据作为讲解的例子
假设表结构如下
CREATE TABLE `test` ( `id` int(11) NOT NULL, `color` varchar(20) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB
数据如下

1) 在RR隔离级别下,存在间隙锁,导致出现死锁的几率比RC大的多!
此时执行语句
select * from test where id <3 for update;
在RR隔离级别下,存在间隙锁,可以锁住(2,5)这个间隙,防止其他事务插入数据!
而在RC隔离级别下,不存在间隙锁,其他事务是可以插入数据!
ps:在RC隔离级别下并不是不会出现死锁,只是出现几率比RR低而已!
2)在RR隔离级别下,条件列未命中索引会锁表!而在RC隔离级别下,只锁行
此时执行语句
update test set color = 'blue' where color = 'white';
在RC隔离级别下,其先走聚簇索引,进行全部扫描。加锁如下:
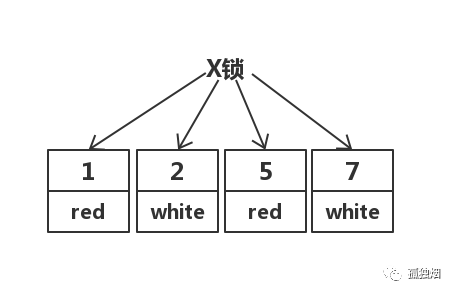
但在实际中,MySQL做了优化,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁。
实际加锁如下
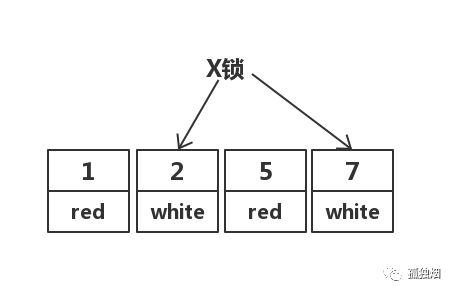
然而,在RR隔离级别下,走聚簇索引,进行全部扫描,最后会将整个表锁上,如下所示
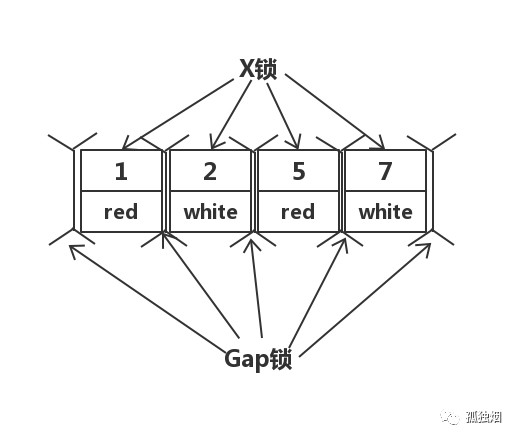
3)在RC隔离级别下,半一致性读(semi-consistent)特性增加了update操作的并发性!
在5.1.15的时候,innodb引入了一个概念叫做“semi-consistent”,减少了更新同一行记录时的冲突,减少锁等待。
所谓半一致性读就是,一个update语句,如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足update的where条件。若满足(需要更新),则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)!
具体表现如下:
此时有两个Session,Session1和Session2!
Session1执行
update test set color = 'blue' where color = 'red';
先不Commit事务!
与此同时Ssession2执行
update test set color = 'blue' where color = 'white';
session 2尝试加锁的时候,发现行上已经存在锁,InnoDB会开启semi-consistent read,返回最新的committed版本(1,red),(2,white),(5,red),(7,white)。MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)!
而在RR隔离级别下,Session2只能等待!
关于Mysql中的 semi-consistent read 可参考这篇文章: MySQL介于普通读和加锁读之间的读取方式:semi-consistent read
题外话一个问题: 事务可重复读的意义在哪?
不可重复读是指在一个事务中对同一数据进行多次读取时,由于其他事务对该数据进行了更新,导致事务中多次读取的结果不一致;而可重复读就是即使其他事务对该数据进行了更新,该读事务多次读取的结果也是一致的。
这样的话我就有疑惑了:数据本身就被更新了,为什么还要保证多次读取的结果一致?这也只是表面上看上去一致的呀,实际都已经改变了,相反我个人还觉得不可重复读能够及时反映数据的变化,似乎更合理一些?那么可重复读的意义在哪呢?或者说不可重复读会有什么后果呢?
一些回答:
不可重复读很容易让人陷入一个思维定式那就是 我干嘛需要多次读取一个值 还要保证一致
要跳出这个思维看本质:我在事务中会不会受到其他事务的影响
举个简单的例子 数据校对(只是举个例子体现意思 不用太在意具体的业务)
我要取当前的余额 当前的账单 上个月的余额 我要检验一下数据对不对
我在事务中取了当前的账单和上个月的余额,好嘛,这时候又有新的订单提交了,我再获取余额是不是就不一致了?
和业务场景有关。
比如财务对账,某个时刻内,我读取账目来对账之类的操作,这个时候肯定不希望读到的数据再发生变化,比如读已提交。这样既保证当前业务继续进行,又可以保证我在某一时刻内的操作不会有影响。相比较串行化的读写互斥的情况,性能和业务处理灵活性上要好一些。否则一旦查询,其他操作无法进行,一般生产环境是不允许的。