百度OCR工具链使用
百度OCR的API使用总体来说比较容易,主要步骤为:注册云平台并登录,选择服务并创建应用,保存API Key以及Secret Key,选择调用API。
注册登录百度云平台
首先需要注册一个百度账号,然后进入百度AI首页

点击控制台即可进行注册或者登录。

选择服务并创建应用
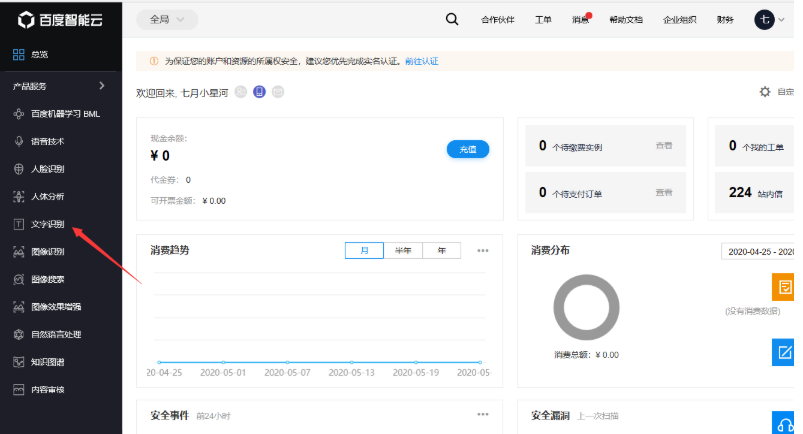
登录后进入到个人管理页面,选择左边服务栏的文字识别服务。

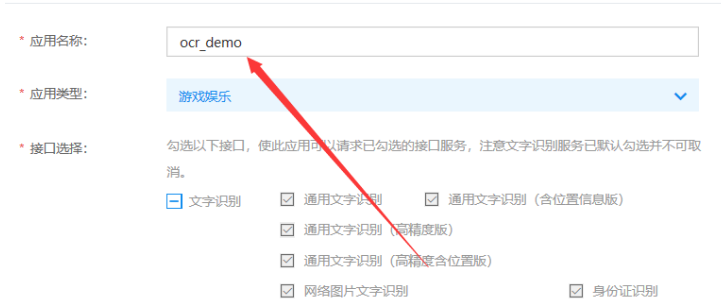
然后选择创建应用,输入应用名称并根据选择选择是否需要包含文字识别包名(我直接选择了不需要)
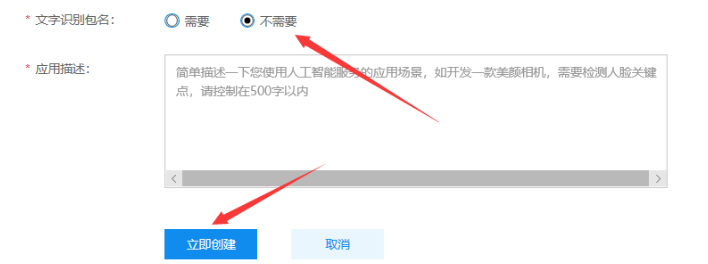
点击立即创建即可创建成功。
保存API Key以及Secret Key
创建应用成功后,点击左边工具栏的应用列表选项,就可以看见自己已经创建的应用。
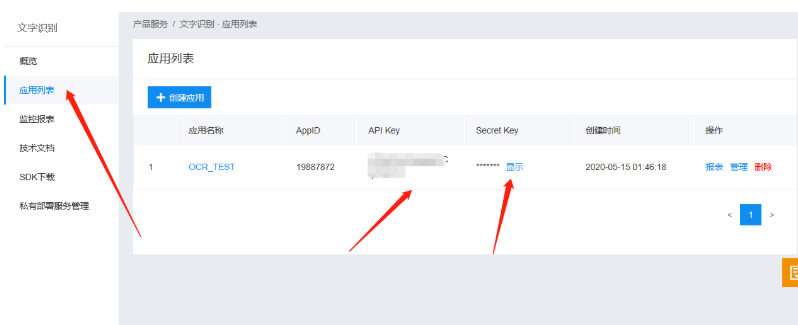
保存API Key以及Secret Key,后续使用API的时候需要用到。
选择调用API
百度OCR的api种类比较多,但是调用方法几乎一致。通过API Key和Secret Key获取access_token,然后使用该参数并结合官方的文档去调用具体的API。下面以通用文字识别接口为例进行简要说明
获取access_token:
通过以下代码可以获取access_token,注意host中的AK和SK要对应更换成前面保存的API Key和Secret Key。
def getAccessToken():
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=AK&client_secret=SK'
response = requests.get(host)
acc_token = response.json()['access_token']
return acc_token
调用接口:
import requests
import base64
'''
通用文字识别
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open('[本地文件]', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
上述代码中需要修改的参数是access_token以及本地文件路径。注意本地图片只支持:PNG、JPG、JPEG、BMP,如果图片格式不匹配,那么会返回216201的错误码。
下面给出一个测试样例:

测试结果为:
{
'log_id': 3587321190249100793,
'words_result_num': 1,
'words_result': [
{'words': '2020春季计算机学院软件工程(罗杰任健)(北京航空航天大学-计算机学院)'}
]
}
至此,百度OCR工具链的介绍到此结束。