一、简介
InfluxDB是一个由InfluxData用go语言开发的开源时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析等,无需外部依赖。
主要特点
1)基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
2)可度量性:你可以实时对大量数据进行计算
设计理念
- 同一时间点多次写入同样的数据被认为是重复写入
- 极少出现删除数据的情况,删除数据基本都是清理过期数据
- 极少更新已有数据且不会出现有争议的更新,时间序列数据总是新数据
- 绝大多数写入是针对最新时间戳的数据,并且数据按时间升序添加
- 数据的规模会非常大,必须能够处理大量的读写操作
- 能够写入和查询数据会比强一致性更重要
- 没有哪个point是过于重要的
优缺点
优势:
架构简单,无依赖
支持http读写
读写性能高,支持类sql查询
完整的生态
不足:
集群不开放
缓冲数据未进行压缩
周边工具不完善
扫描二维码关注公众号,回复:
11264405 查看本文章

生态
TIGK技术栈
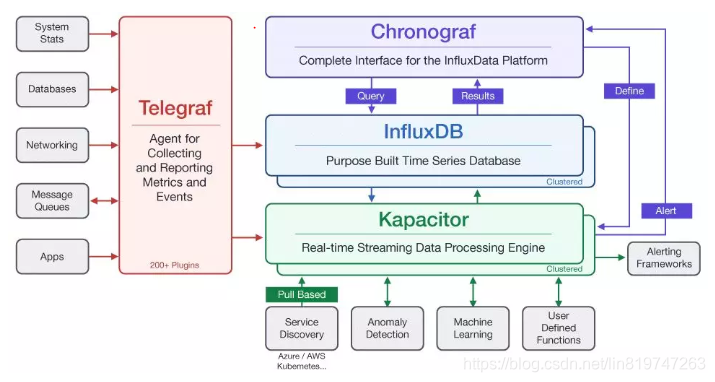
- Telegraf - 指标数据采集
- InfluxDB - 数据接收和存储
- Chronograf和Grafana - 数据可视化展示
- Kapacitor - 时序数据的处理,监视和警报等
lnfluxDB2.0预览
2.0主要把1.0 ICK技术栈合并到了一起,同时也有很多比变化,比如FLUX,详细我们之后会讲。
Flux是infloxdata的函数式数据脚本语言,用于查询、分析和转换数据
同类型数据库(https://db-engines.com/en/ranking/time+series+dbms)
TimescaleDB, 基于 PostgreSQL, 支持 SQL.
KairosDB, 基于 Cassandra, 不支持 SQL.
OpenTSDB 基于Habse
Prometheus facebook开源的,cncf成员,是一套监控系统,同时也有时序数据库存储功能。
应用场景
通用应用场景
只要符合写多读少、无事务要求、海量高并发持续写入、对近期数据比较关注,远期数据不太关注甚至会丢弃,基于时间区间聚合分析以及基于时间区间快速查询的数据都可以使用InfluxDB。
典型应用场景
- 物联网以及传感器监控
- DevOps 监控
- 实时分析