InfluxDB笔记
![]()
参考链接:
influxDB 简介
influxDB 是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。类似的数据库有Elasticsearch、Graphite等
特色:
- 基于时间序列,支持与时间有关的相关函数(如最大,最小,求和等)
- 可度量性:你可以实时对大量数据进行计算
- 基于事件:它支持任意的事件数据
influxDB 安装:
# OS X(Via Homebrew)
brew update
brew install influxdb
# Ubuntu(64 bit)
wget https://dl.influxdata.com/influxdb/releases/influxdb_0.13.0_amd64.deb
sudo dpkg -i influxdb_0.13.0_amd64.deb
# Docker Image
docker pull influxdb- 服务器端启动
> sudo service influxdb start客户端登录
- 使用influxdb的环境变量在CLI进行登录
- Web页面:http://:8083
基本概念
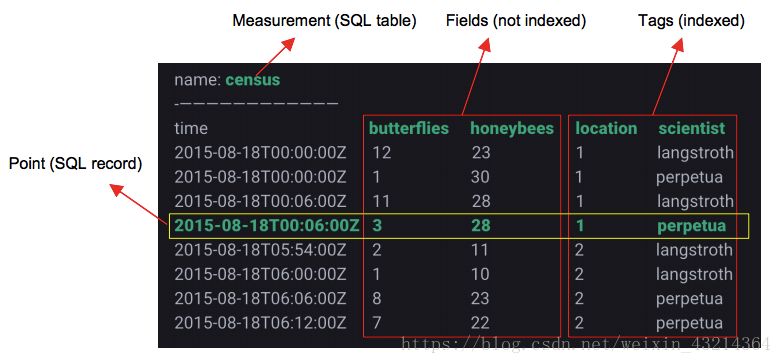
| Influxdb中的概念 | 传统数据库中的概念 |
|---|---|
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
Point
Point由时间戳(timestamp)、数据(field)、标签(tags)组成。
- timestamp: 时序型数据库的标志,可以留空让系统自己设置也可以指定
- field: 主要是用来存放数据的部分,是“key-value”形式。
- tag: 表名+tag一起作为数据库的索引,是“key-value”的形式。
Point相当于传统数据库里的一行数据,如下表所示:
Point属性 传统数据库中的概念 time 每个数据记录时间,是数据库中的主索引(会自动生成) fields 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 tags 各种有索引的属性:地区,海拔
Series
Series的官方解释为:一个共享相同Retention Policy, measurement和tag set的数据集。换句话说,Series就是一个数据集,这个数据集由RP,measurement和tag set共同确定。例子:measurement: census
time location scientist butterflies honeybees 2015-08-18T00:00:00Z 1 langstroth 12 23 2015-08-18T00:00:00Z 1 perpetua 1 30 2015-08-18T00:06:00Z 1 langstroth 11 28 2015-08-18T00:06:00Z 1 perpetua 3 28 2015-08-18T05:54:00Z 2 langstroth 2 11 2015-08-18T06:00:00Z 2 langstroth 1 10 2015-08-18T06:06:00Z 2 perpetua 8 23 2015-08-18T06:12:00Z 2 perpetua 7 22 它的series为:
Arbitrary series number Retention policy Measurement Tag set series 1 default census location = 1,scientist = langstroth series 2 default census location = 2,scientist = langstroth series 3 default census location = 1,scientist = perpetua series 4 default census location = 2,scientist = perpetua
基本操作
如同MYSQL一样,InfluxDB提供多数据库支持,对数据库的操作也与MYSQL相同。
# 显示数据库
> SHOW DATABASES
# 新建数据库
> CREATE DATABASE <db name>
# 删除数据库
> DROP DATABASE <db name>
# 使用数据库
> USE <db name>
# 显示表
> SHOW <measurement name>
# 新建表
> INSERT <measurement name>, <tag key>=<tag value> <field key>=<field value> [timestamp]
# 删除表
> DROP MEASUREMENT <measurement name>
# 增加数据
> INSERT <measurement name>, <tag key>=<tag value>,<tag key>=<tag value> <field key>=<field value>,<field key>=<field value> [timestamp]InfluxDB是时序型数据库,没有提供修改和删除数据的方法,但是数据删除可以通过influxDB的数据保存策略实现(Retention Policies)
influxDB中的数据保留策略
InfluxDB的数据保留策略(RP) 用来定义数据在InfluxDB中存放的时间,或者定义保存某个期间的数据。
注意:
- RP是数据库级别而不是表级别的属性。这和很多数据库都不同。
- 每个数据库可以有多个数据保留策略,但只能有一个默认策略。
- 不同表可以根据保留策略规划在写入数据的时候指定RP进行写入
目的:控制数据库中的数据量,因为influxDB中没有删除数据的操作
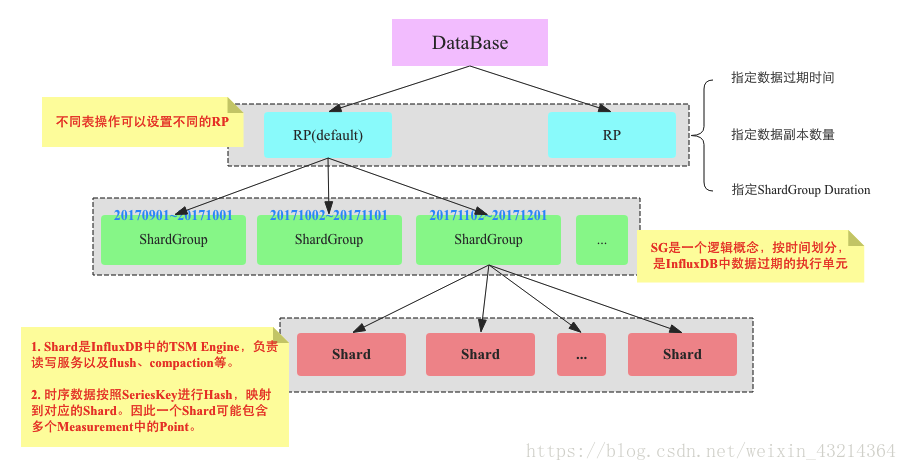
Shard Group
Shard Group是influxDB中的一个重要的逻辑概念,它的意思是将数据按照时间进行分区,每一个Shard只能存储特定时间段内的数据。不同Shard Group对应的时间段不会重合。比如2017年9月份的数据落在Shard Group0上,2017年10月份的数据落在Shard Group1上。
每个Shard Group对应多长时间是通过Retention Policy中字段”SHARD DURATION”指定的,如果没有指定,也可以通过Retention Duration(数据过期时间)计算出来,两者的对应关系为:

使用Shard Group的原因:
将数据按照时间分割成小的粒度会使得数据过期实现非常简单,InfluxDB中数据过期删除的执行粒度就是Shard Group,系统会对每一个Shard Group判断是否过期,而不是一条一条记录判断。
实现了将数据按照时间分区的特性。将时序数据按照时间分区是时序数据库一个非常重要的特性,基本上所有时序数据查询操作都会带有时间的过滤条件,比如查询最近一小时或最近一天,数据分区可以有效根据时间维度选择部分目标分区,淘汰部分分区。
Note: Shard为InfluxDB后台真正的存储引擎,influxDB的Sharding策略为Hash Sharding,分布式存储的Sharding策略暂不研究
# 查询策略
> SHOW RETENTION POLICIES ON <db name>
name duration shardGroupDuration replicaN default
default 0 168h0m0s 1 true
# name: 保留策略的名称
# duration:持续时间,0表示无限制
# shardGroupDuration--shardGroup的存储时间,shardGroup是InfluxDB的一个基本储存结构
# replicaN--副本个数
# default: 是否是默认策略
# 新建策略
> CREATE RETENTION POLICY <retention policy name> ON <db name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
# 修改策略
> ALTER RETENTION POLICY <retention policy name> ON <db name> DURATION <duration> DEFAULT
# 删除策略
> DROP RETENTION POLICY <retention policy name> ON <db name>influxDB中的连续查询
InfluxDB的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT 关键词和 GROUP BY time() 关键词。
InfluxDB会将查询结果放在指定的数据表中。
连续查询的目的:
- 降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的系统占用量
- 使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
注意:InfluxDB的连续查询操作只能由管理员用户完成
# 创建连续查询
> CREATE CONTINUOUS QUERY <continusous query name> ON <db name>
[RESAMPLE [EVERY <interval>] [FOR <interval>]]
BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement>
FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>]
END
# 显示已存在的连续查询
> SHOW CONTINUOUS QUERIES
# 删除连续查询
> DROP CONTINUOUS QUERY <continuous query name> ON <db name>常用聚合类函数
COUNT()函数:
返回一个field中的非空值的数量
> SELECT COUNT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>] # 注意:InfluxDB中的函数如果没有指定时间的话,会默认以 epoch 0 (1970-01-01T00:00:00Z) 作为时间。 # 可以在where中加入时间条件 > SELECT COUNT(<field name>) FROM <measurement name> WHERE time >= 'yyyy-mm-ddThh:MM:ssZ' AND time < 'yyyy-mm-ddThh:MM:ssZ' GROUP BY time(<time length>)DISTINCT()函数:
返回一个字段(field)的唯一值。
> SELECT DISTINCT(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]MEAN() 函数:
返回一个字段(field)中的值的算术平均值(平均值)。字段类型必须是长整型或float64。
> SELECT MEAN(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]MEDIAN()函数:
从单个字段(field)中的排序值返回中间值(中位数)。字段值的类型必须是长整型或float64格式。
> SELECT MEDIAN(<field_key>) FROM <measurement name> [WHERE <stuff>] [GROUP by <stuff>]SPREAD()函数:
返回字段的最小值和最大值之间的差值。数据的类型必须是长整型或float64。
> SELECT SPREAD(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]SUM()函数
返回一个字段中的所有值的和。字段的类型必须是长整型或float64。
> SELECT SUM(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
常用选择类函数
TOP()函数
作用:返回一个字段中最大的N个值,字段类型必须是长整型或float64类型。
> SELECT TOP( <field_key>[,<tag_key(s)>],<N> )[,<tag_key(s)>|<field_key(s)>] [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] [ORDER_BY_clause] [LIMIT_clause] [OFFSET_clause] [SLIMIT_clause] [SOFFSET_clause]BOTTOM()函数
作用:返回一个字段中最小的N个值。字段类型必须是长整型或float64类型。
> SELECT BOTTOM(<field_key>[,<tag_keys>],<N>)[,<tag_keys>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]FIRST()函数
作用:返回一个字段中最老的取值。
> SELECT FIRST(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]LAST()函数
作用:返回一个字段中最新的取值。
> SELECT LAST(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]MAX()函数
作用:返回一个字段中的最大值。该字段类型必须是长整型,float64,或布尔类型。
> SELECT MAX(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]MIN()函数
作用:返回一个字段中的最小值。该字段类型必须是长整型,float64,或布尔类型。
> SELECT MIN(<field_key>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]PERCENTILE()函数
作用:返回排序值排位为N的百分值。字段的类型必须是长整型或float64。
百分值是介于100到0之间的整数或浮点数,包括100。
> SELECT PERCENTILE(<field_key>, <N>)[,<tag_key(s)>] FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]
常用变化类函数
DERIVATIVE()函数
作用:返回一个字段在一个series中的变化率。
InfluxDB会计算按照时间进行排序的字段值之间的差异,并将这些结果转化为单位变化率。其中,单位可以指定,默认为1s。> SELECT DERIVATIVE(<field_key>, [<unit>]) FROM <measurement_name> [WHERE <stuff>]其中unit的取值可以有以下几种:
u --microseconds s --seconds m --minutes h --hours d --days w --weeksDERIVATIVE()函数还可以在GROUP BY time()的条件下与聚合函数嵌套使用,格式如下:
> SELECT DERIVATIVE(AGGREGATION_FUNCTION(<field_key>),[<unit>]) FROM <measurement_name> WHERE <stuff> GROUP BY time(<aggregation_interval>)DIFFERENCE()函数
作用:返回一个字段中连续的时间值之间的差异。字段类型必须是长整型或float64。
最基本的语法:> SELECT DIFFERENCE(<field_key>) FROM <measurement_name> [WHERE <stuff>]与GROUP BY time()以及其他嵌套函数一起使用的语法格式:
> SELECT DIFFERENCE(<function>(<field_key>)) FROM <measurement_name> WHERE <stuff> GROUP BY time(<time_interval>)其中函数可以包含:
COUNT(), MEAN(), MEDIAN(),SUM(), FIRST(), LAST(), MIN(), MAX(), 和 PERCENTILE()。ELAPSED()函数
作用:返回一个字段在连续的时间间隔间的差异,间隔单位可选,默认为1纳秒。
可选单位如下表Units Meaning u microseconds(1 millionth of a second) ms milliseconds(1 thousandth of a second) s second m minute h hour d day w week > SELECT ELAPSED(<field_key>, <unit>) FROM <measurement_name> [WHERE <stuff>]MOVING_AVERAGE()函数
作用:返回一个连续字段值的移动平均值,字段类型必须是长整形或者float64类型。
语法:> SELECT MOVING_AVERAGE(<field_key>,<window>) FROM <measurement_name> [WHERE <stuff>]与其他函数和GROUP BY time()语句一起使用时的语法:
> SELECT MOVING_AVERAGE(<function>(<field_key>),<window>) FROM <measurement_name> WHERE <stuff> GROUP BY time(<time_interval>)此函数可以和以下函数一起使用:
COUNT(), MEAN(),MEDIAN(), SUM(), FIRST(), LAST(), MIN(), MAX(), and PERCENTILE().
NON_NEGATIVE_DERIVATIVE()函数
作用:返回在一个series中的一个字段中值的变化的非负速率。
> SELECT NON_NEGATIVE_DERIVATIVE(<field_key>, [<unit>]) FROM <measurement_name> [WHERE <stuff>]unit取值可以有:
Unit Meaning u microseconds s seconds m minutes h hour d days w weeks 与聚合类函数放在一起使用时的语法如下所示:
> SELECT NON_NEGATIVE_DERIVATIVE(AGGREGATION_FUNCTION(<field_key>),[<unit>]) FROM <measurement_name> WHERE <stuff> GROUP BY time(<aggregation_interval>)STDDEV()函数
作用:返回一个字段中的值的标准偏差。值的类型必须是长整型或float64类型。
基本语法:
> SELECT STDDEV(<field_key>) FROM <measurement_name> [WHERE <stuff>] [GROUP BY <stuff>]