问题:想将爬虫功能定义成一个函数,但困惑于如何调用参数
url = 'http://xxxx.com.cn'
resp = requests.get(url)
soup = BeautifulSoup(resp.text, "html.parser")
格式一:soup.find_all('div', attrs={'class': 'cnt1'})
格式二:soup.find_all('img', attrs={'class': 'by_img'})[0].get('src')
研究了一番相关知识,总结如下:
一、参数的几种类型:
1、位置参数:
函数调用时的数量、位置、参数类型必须和定义时的一致。必须按顺序传全部参数。
2、默认参数:
函数定义时,为参数设置一个默认值,当函数调用时,没有传入这个参数值,直接使用这个默认值。默认参数必须指向不可变对象。
3、可变参数:
*args:这种形式表示接受任意多个实际参数将其放到一个元组tuple中。
4、关键字参数:
**kwargs:这种形式表示接受任意多个实际参数将其放到一个字典dict中。也属于一种可变参数。
它们之间的排列顺序为:必选参数 -> 默认参数 -> 可变参数 -> 关键字参数。
二、函数参数的引用:
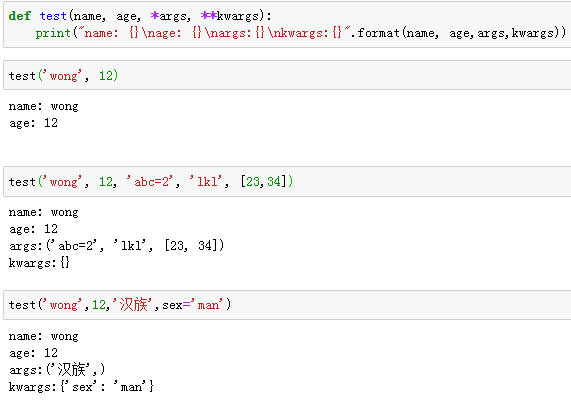
三、爬取数据
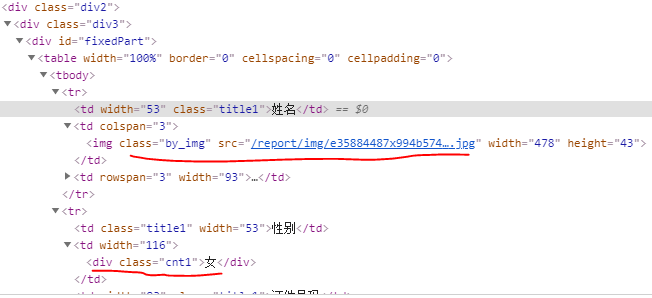
resp = requests.get(url)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text, "html.parser")
data1 = soup.find_all('div', attrs={'class': 'cnt1'})
data2 = soup.find_all('img', attrs={'class': 'by_img'})[0].get('src')
四、编写函数与调试
函数定义:

调用函数:
