OceanBase是一个支持海量数据的通用高性能分布式数据库系统,兼容MySQL绝大部分常用用法,目标是尽可能的兼容Oracle常用用法。实现了数千亿条记录、数百TB数据上的跨行跨表事务,由淘宝核心系统研发部、运维、DBA、广告、应用研发等部门共同完成。在设计和实现OceanBase的时候暂时摒弃了不紧急的DBMS的功能,例如临时表,视图(view),研发团队把有限的资源集中到关键点上,当前 OceanBase主要解决数据更新一致性、高性能的跨表读事务、范围查询、join、数据全量及增量dump、批量数据导入。
连接OceanBase
OceanBase 支持MySQL协议,支持JDBC接口。用户可以使用mysql客户端工具连接OceanBase,应用使用jdbc for mysql驱动连接OceanBase。
示例:mysql命令行连接oceanbase的sys租户
- mysql常用管理命令1
查看database列表,查看表列表以及查看表的数据
- 查看OB租户元数据库的命令
OceanBase租户里会多一个默认的数据库(oceanbase),里面有部分元数据库视图,方便了解租户所在集群信息。OceanBase sys租户里元数据视图会更多更全。
- OB常用的mysql命令1

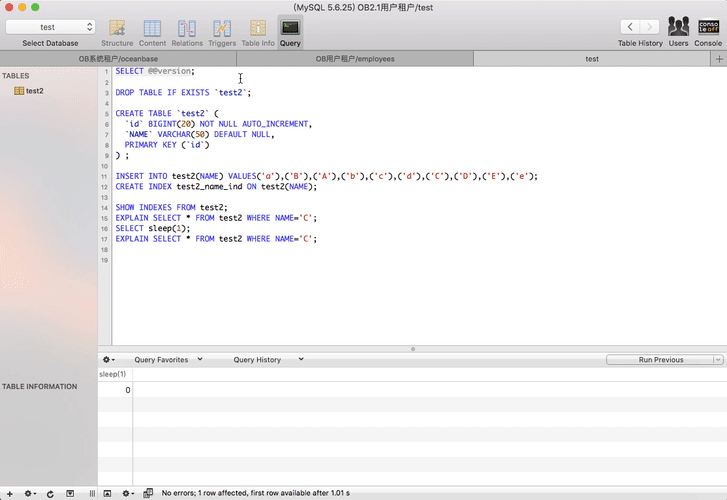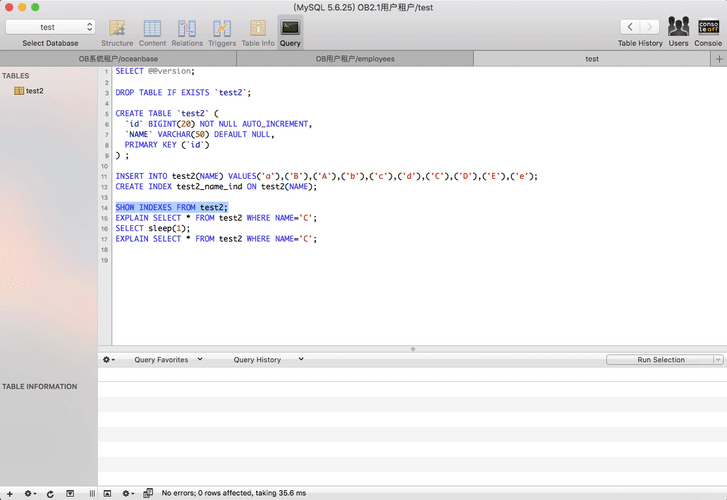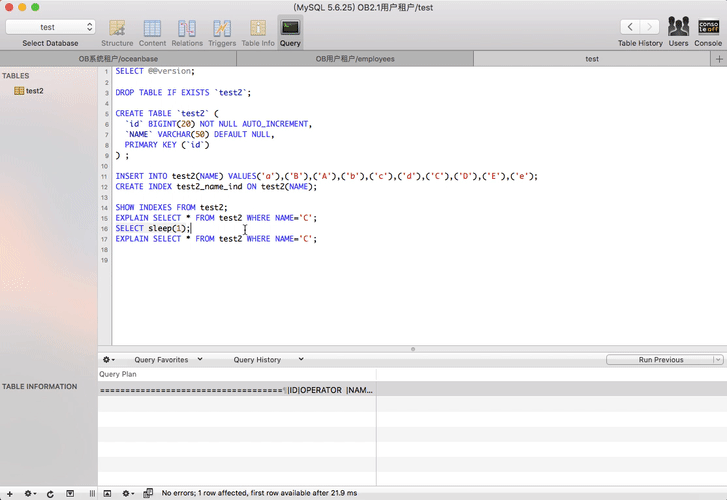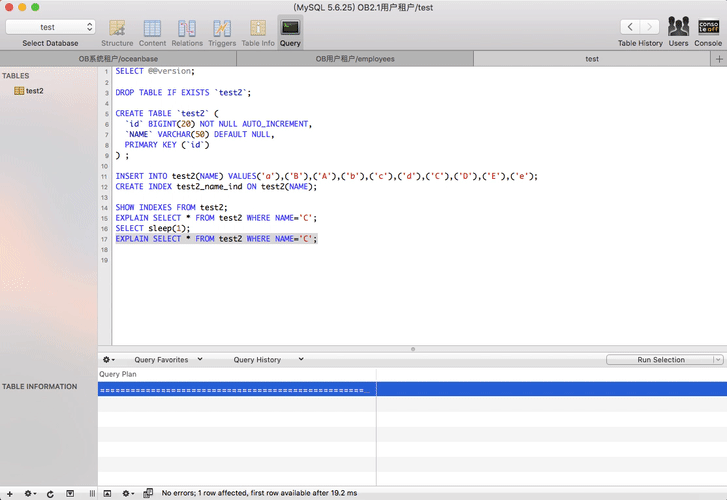
OceanBase 1.4分区表用法
业务数据做水平拆分,有如下几种方案
- 分库分表:通过分布式数据库中间件做分库分表拆分和路由等。如DRDS,MyCat,TDSQL等。
- 分区:Oracle 12c的sharding, OceanBase 1.0及以后的版本
- 存储级别切片,对应用透明。如Google的Spanner,PingCap的TiDB
OceanBase的分区策略支持hash/list/range,以及支持二级分区(hash+hash,hash+range,key+key,range+range等)。详细用法请参见OceanBase官网 文档里 的OB分区表用法 。
无论是分库分表,还是分区的方案,都会面临一个问题,就是当一个Query 要取不同机器(节点)上的数据的时候,如果保证取出来的数据是一致的(指来自于同一个时间点或版本)。
分库分表方案解决不了这个问题, OB1.4也不能解决这个问题。OB2.0 新增全局时间服务,能提供全局一致性快照读功能,所以解决了这个问题。
这里演示一下 OB1.4 里规避这个跨节点读的方案(弱一致读)
SELECT @@version;
drop table if exists t_parttable;
create table t_parttable(
id bigint not null primary key,
name varchar(50) not NULL,
KEY name_ind(NAME) LOCAL
) DEFAULT CHARSET=utf8mb4 partition by hash(mod(id,1000)) partitions 8;
insert into t_parttable(id, name) values(1,'a'),(2,'A'),(3,'b'),(4,'B'),(5,'c'),(6,'C'),(7,'d'),(8,'D');
set session ob_query_timeout=1000000; select * from t_parttable where name='a';
explain select * from t_parttable where name='a';
select /*+read_consistency(weak)*/ * from t_parttable where name='a';
select * from t_parttable partition(p1);
select * from t_parttable partition(p2);
该问题,在OceanBase 2.0后版本已经解了
OB租户负载均衡历史查看
OB作为一个分布式数据库,至少包含3个节点。其负载均衡的原理跟传统负载均衡的原理大不一样。
传统负载均衡设备(F5)或软件(LVS,SLB等)都是通过在某一协议层作为流量入口然后分配流量给后端不同的节点,从而去改变后端节点的压力。
OceanBase的负载均衡是自己通过调整每个节点(ObServer)里的数据(Partition)分布,从而间接改变打到各个节点(ObServer)上的流量,从而改变各个节点的压力。
示例演示:租户视角查看负载均衡历史。
这里是新建了一个分区表(8个分区),在插入数据后,触发了负载均衡机制,把8个分区分散到多个节点上。
# 查看分区表的数据
SHOW CREATE TABLE db_bin.t_parttable;
SELECT /*+read_consistency(weak)*/ * FROM db_bin.t_parttable ORDER BY id ;
# 查看租户的资源单元(Unit)分布
SELECT tenant_name, unit_id,zone,svr_ip,max_cpu,round(max_memory/1024/1024/1024) max_mem_gb FROM gv$unit;
# 查看租户的负载均衡历史
SELECT str_to_date(h.gmt_create,'%Y-%m-%d %h:%i:%s') gmt_create, h.zone, t.database_name, t.tablegroup_name, t.table_name, t.part_num,h.partition_id,h.data_size, h.data_src_ip, h.dest_unit_id, h.dest_ip, h.result_code, h.COMMENT , h.rs_svr_ip
FROM gv$unit_load_balance_event_history h JOIN gv$TABLE t ON (h.table_id=t.table_id)
WHERE t.table_name NOT LIKE '%recycle%' AND t.database_name='db_bin'
ORDER BY gmt_create DESC LIMIT 100;OB sys租户查看集群使用信息
OceanBase作为一款通用的分布式关系型数据库,跟其他同行产品相比,有一个独特的地方,就是支持多租户,即支持集群资源(CPU/MEM/DISK等)的做租户管理。
OceanBase集群,至少是三节点。OceanBase把三个节点的机器资源能力聚合成一个大的资源池,然后做二次资源管理和分配。为每个租户分配一个特定规格的小的资源池,并且随时可以动态调整。
租户对于业务开发来说就是一个体的实例,只是开发不需要关注这个实例在哪个节点上。租户的使用体验类似于
MySQL (默认,以后还支持Oracle兼容模式的租户)。
假设OceanBase集群已经搭建好了,在创建租户之前,先清点一下现有集群的资源使用状况。下面是示例
# 查看集群节点资源使用情况
SELECT svr_ip, s.zone, s.cpu_total, s.cpu_assigned, s.cpu_assigned_percent, round(s.mem_total/1024/1024/1024) mem_total_gb, round(s.mem_assigned/1024/1024/1024) mem_ass_gb, s.mem_assigned_percent
FROM __all_virtual_server_stat s
ORDER BY zone,svr_ip;
# 查看资源单元规格定义
SELECT NAME, max_cpu, min_cpu, round(max_memory/1024/1024/1024) max_mem_gb , round(min_memory/1024/1024/1024) min_mem_gb FROM __all_unit_config ORDER BY unit_config_id LIMIT 10;
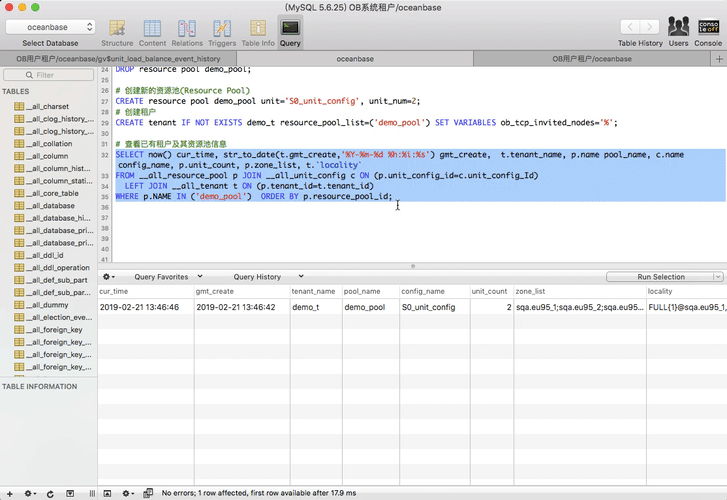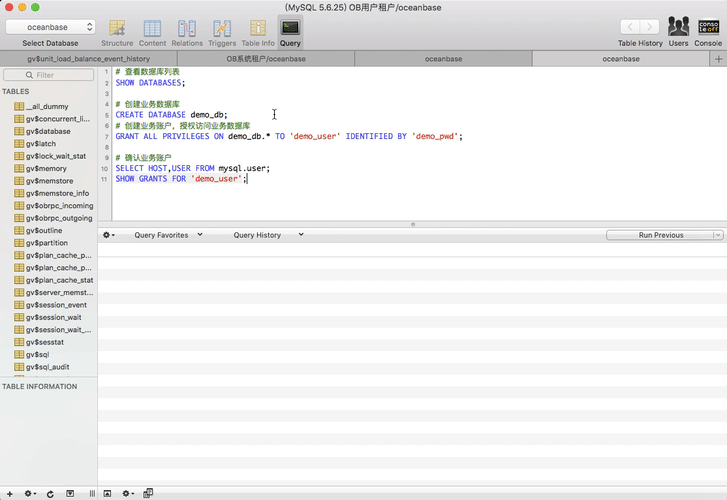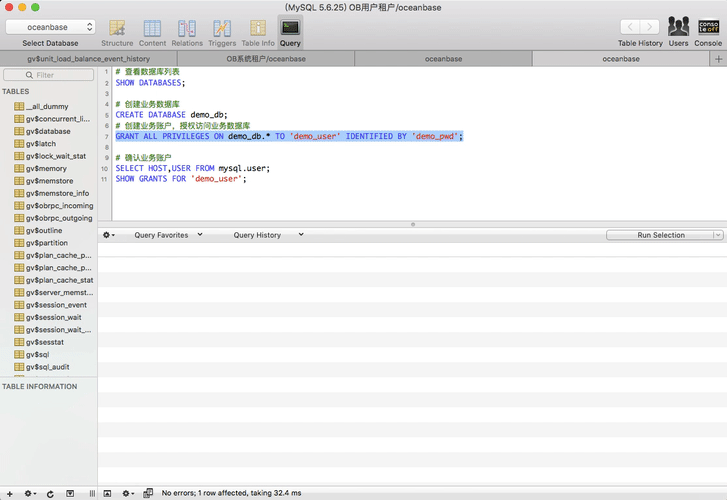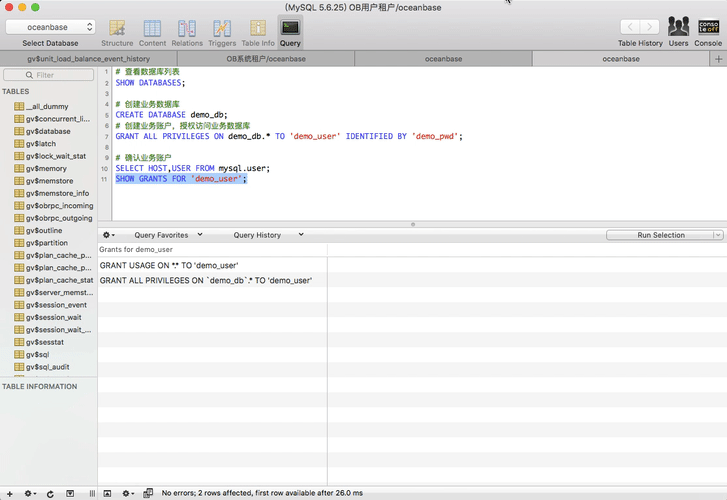
# 查看已有租户及其资源池信息
SELECT t.tenant_name, p.name pool_name, c.name config_name, p.unit_count, p.zone_list, t.`locality`
FROM __all_resource_pool p JOIN __all_unit_config c ON (p.unit_config_id=c.unit_config_Id)
LEFT JOIN __all_tenant t ON (p.tenant_id=t.tenant_id)
WHERE p.NAME IN ('yq_Pool','app_pool') ORDER BY p.resource_pool_id;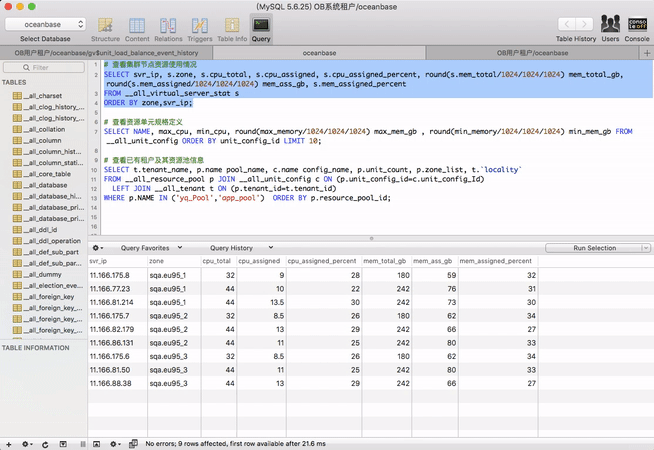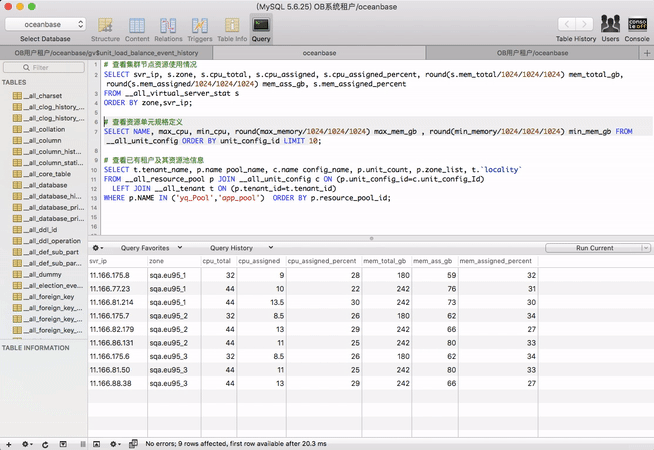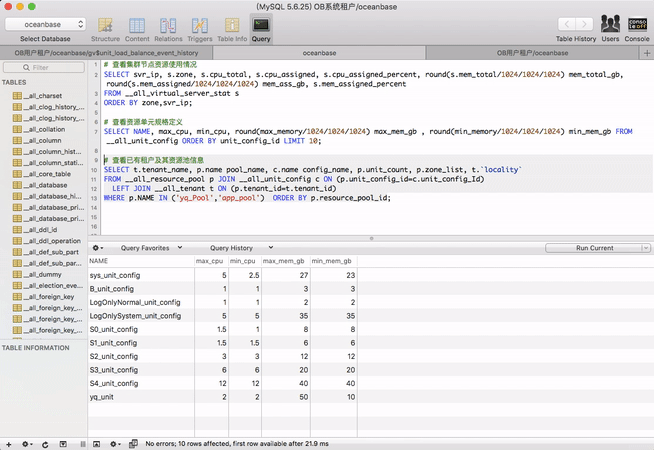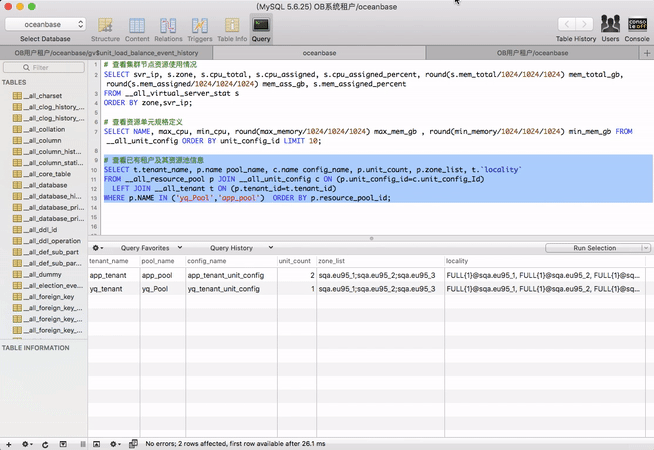
OceanBase租户创建(很简单)
清点了OceanBase集群资源使用情况后,选定一个规格,就可以快速创建出一个租户(demo_t)
示例:OB1.4下创建租户(2步)
# 清理已经创建的同名租户
DROP tenant IF EXISTS demo_t;
DROP resource pool demo_pool;
# 创建新的资源池(Resource Pool)
CREATE resource pool demo_pool unit='S0_unit_config', unit_num=2;
# 创建租户
CREATE tenant IF NOT EXISTS demo_t resource_pool_list=('demo_pool') SET VARIABLES ob_tcp_invited_nodes='%';
# 查看已有租户及其资源池信息
SELECT now() cur_time, str_to_date(t.gmt_create,'%Y-%m-%d %h:%i:%s') gmt_create, t.tenant_name, p.name pool_name, c.name config_name, p.unit_count, p.zone_list, t.`locality`
FROM __all_resource_pool p JOIN __all_unit_config c ON (p.unit_config_id=c.unit_config_Id)
LEFT JOIN __all_tenant t ON (p.tenant_id=t.tenant_id)
WHERE p.NAME IN ('demo_pool') ORDER BY p.resource_pool_id;退出当前sys租户,重新登录新建租户 ,用户名是:root@demo_t#集群名,密码默认是空。 登录后新建Database,并创建账户访问DB。
OceanBase里索引创建特征
OceanBase里创建索引稍微有点特殊,开发和运维需要留意一下。
- 如果是在create table里带上了索引(包括唯一索引,也就是唯一性约束),是立即生效的。
- OB 1.x 版本里在表存在的情况下新建的索引(包括唯一索引),命令立即返回,但是索引不是立即生效。需要等到OB集群发起大合并之后才会生效。其中唯一索引需要等待两次大合并。所以运维建索引后需要安排1-2次大合并操作。
- OB 2.x 版本里在表存在的情况下新建的索引(包括唯一索引),命令立即返回,索引也不是立即生效,但是索引开始后台异步创建,创建时间取决于数据量。
示例如下:
1. OB 1.x 版本的索引

2. OB 2.x版本的索引