一、准备
1.1创建一个实验用户,如hadoop(!!!!也可以采用已有的mysql用户,这样就不需要再创建了,给mysql用户做相应管理员权限赋权就可以了, 后续需要用到用户名hadoop的时候,使用mysql)
sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
sudo adduser hadoop sudo #为hadoop用户增加管理员权限
su - hadoop #切换当前用户为用户hadoop
sudo apt-get update #更新hadoop用户的apt,方便后面的安装
(19.3.22)
1.2安装SSH,设置SSH无密码登陆
sudo apt-get install openssh-server #安装SSH server
ssh localhost #登陆SSH,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
ssh-keygen -t rsa
连续敲击三次回车
其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。之后再输入:
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost #此时已不需密码即可登录localhost,并可见下图。
如果失败则可以搜索SSH免密码登录来寻求答案
二、安装jdk1.8
首先在oracle官网下载jdk1.8
http://www.oracle.com/technetwork/java/javase/downloads/index.html
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
接下来进行安装与环境变量配置,根据个人电脑系统选择对应版本,如 jdk-8u201-linux-x64.tar.gz
mkdir /usr/lib/jvm #创建jvm文件夹
sudo tar zxvf jdk-8u201-linux-x64.tar.gz -C /usr/lib/jvm #/ 解压到/usr/lib/jvm目录下
cd /usr/lib/jvm #进入该目录
mv jdk1.8.0_201 java #重命名为java
vi ~/.bashrc #给JDK配置环境变量
注:其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
另外推荐使用vim来编辑环境变量,即最后一句使用指令
vim ~/.bashrc
# 如果没有vim,可以使用:
sudo apt-get install vim
# 来进行下载。
在.bashrc文件添加如下指令:
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=${JAVA_HOME}/bin:$PATH
在文件修改完毕保存以后,在终端输入指令:
$ source ~/.bashrc #使新配置的环境变量生效
$ java -version #检测是否安装成功,查看java版本
如果出现如下图所示的内容,即为安装成功
三、安装hadoop-3.1.2
先下载hadoop-3.1.2.tar.gz,链接如下:
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
下面进行安装:
sudo tar -zxvf hadoop-3.1.2.tar.gz -C /usr/local #解压到/usr/local目录下
cd /usr/local
sudo mv hadoop-3.1.2 hadoop #重命名为hadoop
sudo chown -R hadoop ./hadoop #修改文件权限,根据实际情况确定用户名
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
同样,执行source ~/.bashrc使设置生效,并查看hadoop是否安装成功
source ~/.bashrc
hadoop version
正确显示版本即成功。
伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。首先将jdk1.8的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件
cd /usr/local/hadoop/etc/hadoop/
sudo vim hadoop-env.sh
接下来修改core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
接下来修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(可参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化
cd /usr/local/hadoop/
./bin/hdfs namenode –format
启动namenode和datanode进程,并查看启动结果
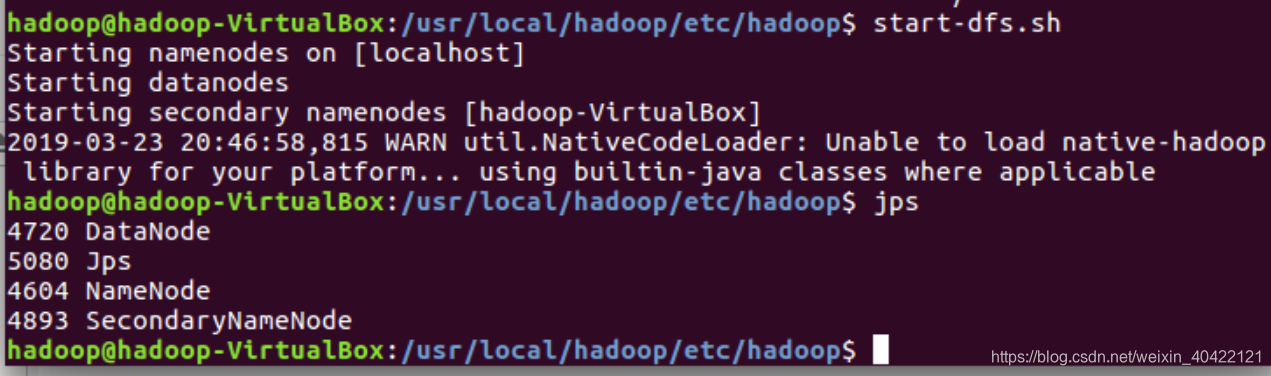
./sbin/start-dfs.sh
jps
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
此时也有可能出现要求输入localhost密码的情况 ,如果此时明明输入的是正确的密码却仍无法登入,其原因是由于如果不输入用户名的时候默认的是root用户,但是ssh服务默认没有开root用户的ssh权限
输入指令:
vim /etc/ssh/sshd_config
检查PermitRootLogin 后面是否为yes,如果不是,则将该行代码 中PermitRootLogin 后面的内容删除,改为yes,保存。之后输入下列代码重启SSH服务:
/etc/init.d/sshd restart
即可正常登入(免密码登录参考前文)
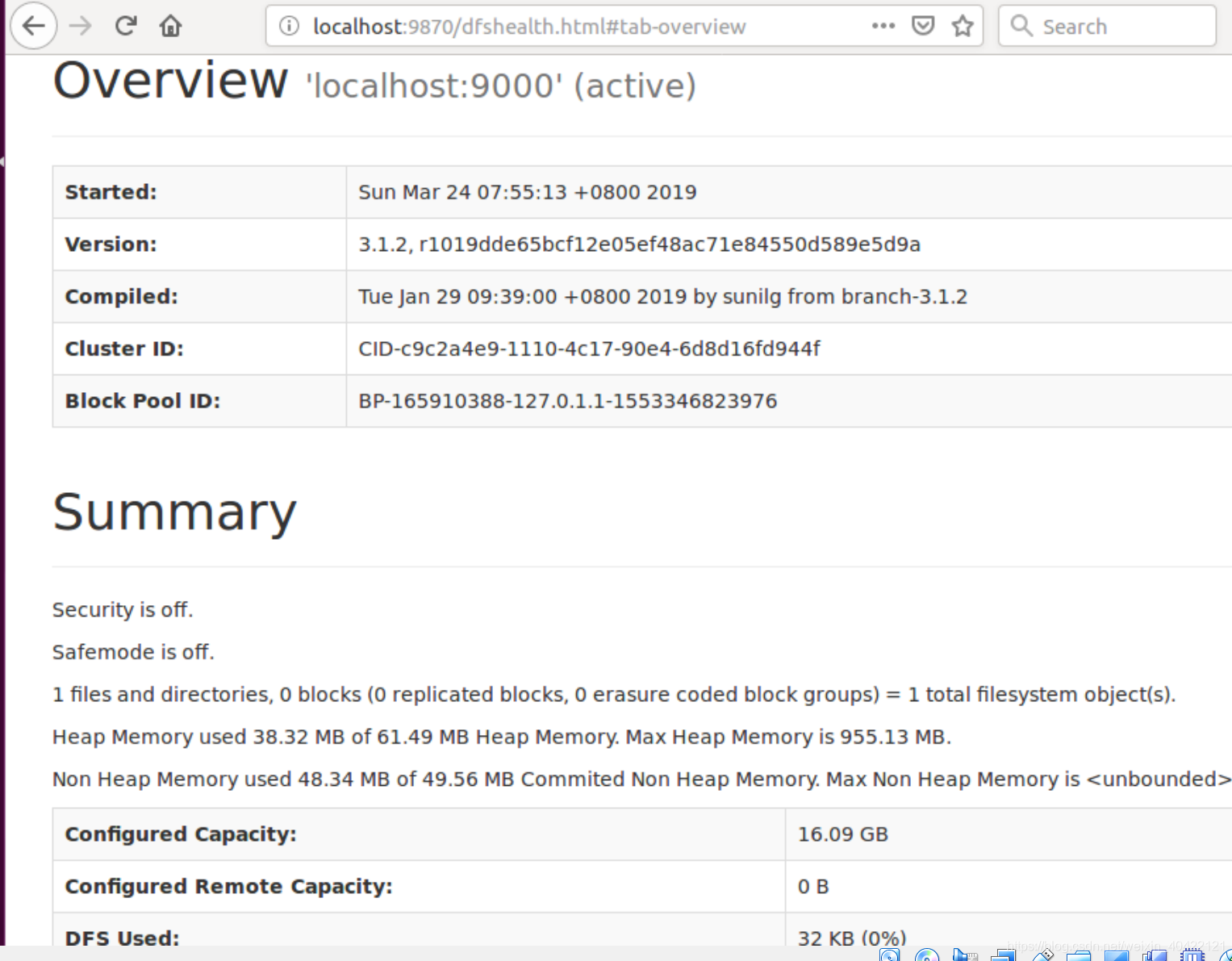
成功启动后,如果是在桌面版linux上安装的,也可以访问 Web 界面 http://localhost:9870(老版本为50070) 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。 (如果是在服务器版linux上安装的hadoop, 为了进行浏览器访问,需要配置一个桌面版的虚拟机来进行,输入用IP地址代替localhost)
注意1: 也可能WEB访问不成功, 可上网寻找解决办法。
注意2:DFS文件系统格式化时,会在namenode数据文件夹(即配置文件中dfs.namenode.name.dir在本地系统的路径)中保存一个current/VERSION文件,记录clusterID,标识了所格式化的 namenode的版本。如果频繁的格式化namenode,那么datanode中保存(即配置文件中dfs.data.dir在本地系统的路径)的current/VERSION文件只是你第一次格式化时保存的namenode的ID,因此就会造成datanode与namenode之间的 id 不一致。可能导致datanode无法启动。
可以运行一个例子,步骤如下:
创建执行MapReduce作业所需的 DFS 目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/<username> //<username> 问用户名,如hadoop
拷贝输入文件到分布式文件系统:
bin/hdfs dfs -put etc/hadoop input
可以运行一些例子:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'
查看输出的文件(files): 从分布式文件系统中拷贝文件到本地文件系统并查看:
bin/hdfs dfs -get output output
cat output/*
或者直接在分布式文件系统上查看:
bin/hdfs dfs -cat output/*
YARN 单机配置
通过设置几个参数并运行ResourceManager daemon and NodeManager daemon,你可以在YARN上以伪分布模式运行MapReduce job。
配置mapred-site.xml如下 :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动ResourceManager daemon 和 NodeManager daemon:
sbin/start-yarn.sh
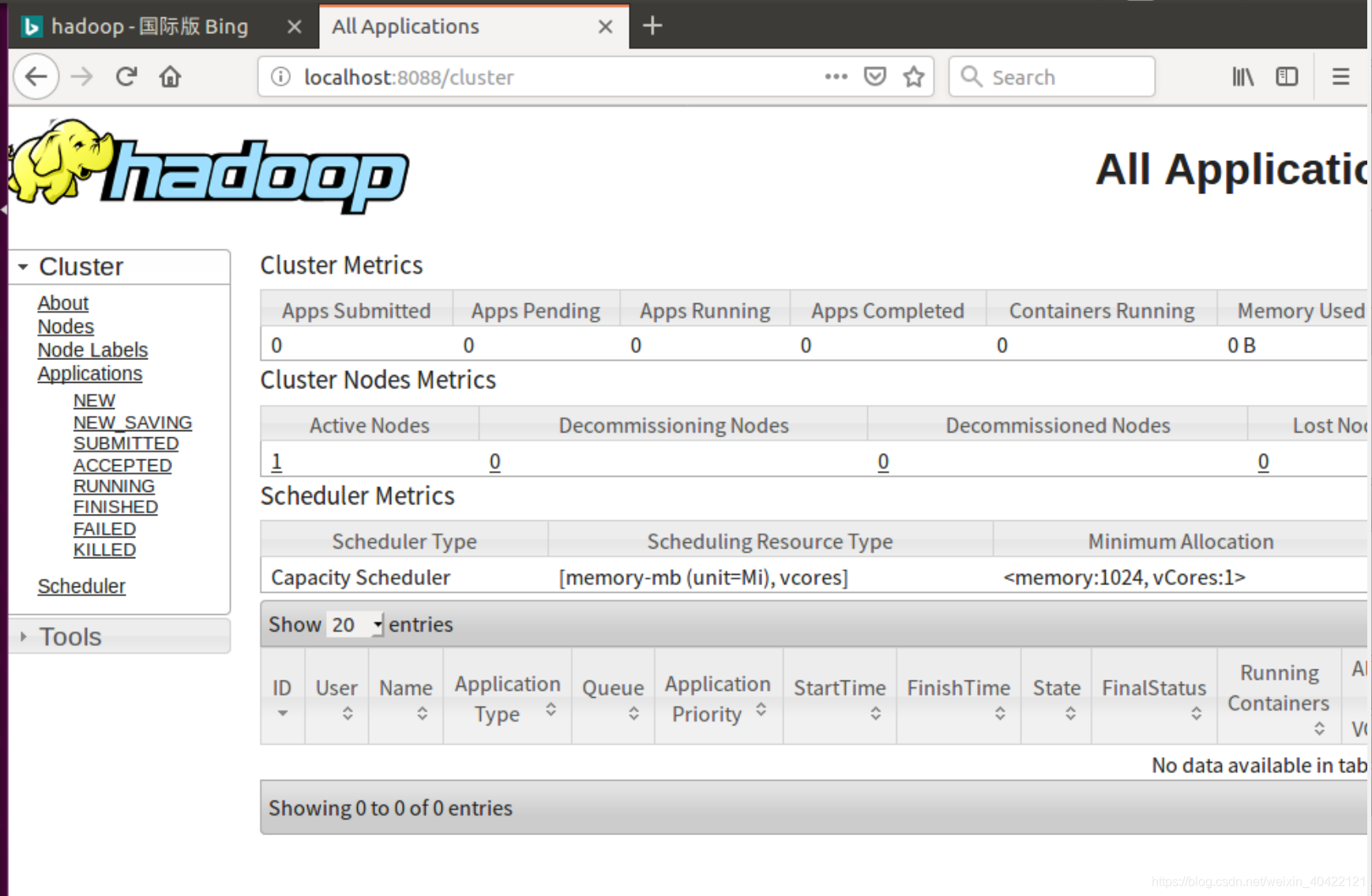
如果是在桌面版linux上安装的, 可以用浏览器打开资源管理器端口,默认为:
ResourceManager - http://localhost:8088/
(如果是在服务器版linux上安装的hadoop, 为了进行浏览器访问,需要配置一个桌面版的虚拟机来进行,输入用IP地址代替localhost)
可以通过下列命令停止hadoop和YARN
sbin/stop-dfs.sh
sbin/stop-yarn.sh
四 安装Hbase和简单使用
解压安装包hbase-1.2.11-bin.tar.gz至路径 /usr/local,命令如下:
sudo tar -zxvf hbase-1.2.11-bin.tar.gz -C /usr/local
将解压的文件名hbase-1.2.11改为hbase,以方便使用,命令如下:
sudo mv /usr/local/hbase-1.2.11 /usr/local/hbase
cd /usr/local
sudo chown -R hadoop ./hbase
#将hbase下的所有文件的所有者改为hadoop,hadoop是当前用户的用户名。
配置环境变量
给hbase配置环境变量,将下面代码添加到.bashrc文件:
export PATH=$PATH:/usr/local/hbase/bin
vim ~/.bashrc
执行source ~/.bashrc使设置生效,并查看hbase是否安装成功
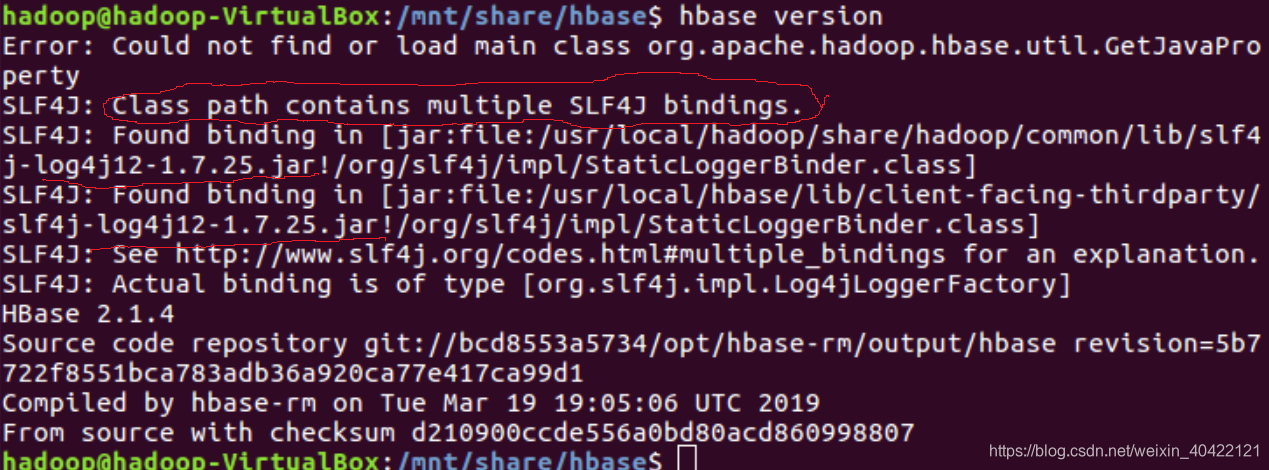
/usr/local/hbase/bin/hbase version
(如果发生jar包冲突,可以移除。2.1.4版本会发生下图错误,暂时不使用)
HBase配置
单机配置(可能需要配置JAVA_HOME环境变量, 由于本实验指南在HADOOP安装时已配置,故省略)
配置/usr/local/hbase/conf/hbase-site.xml如下
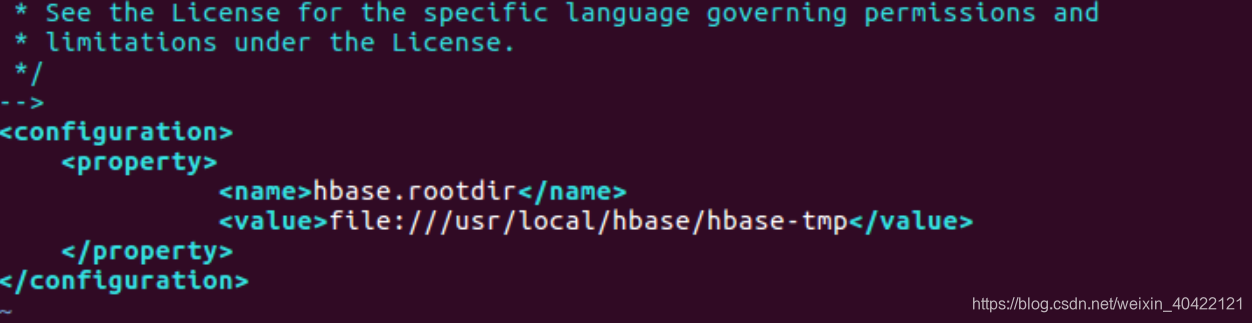
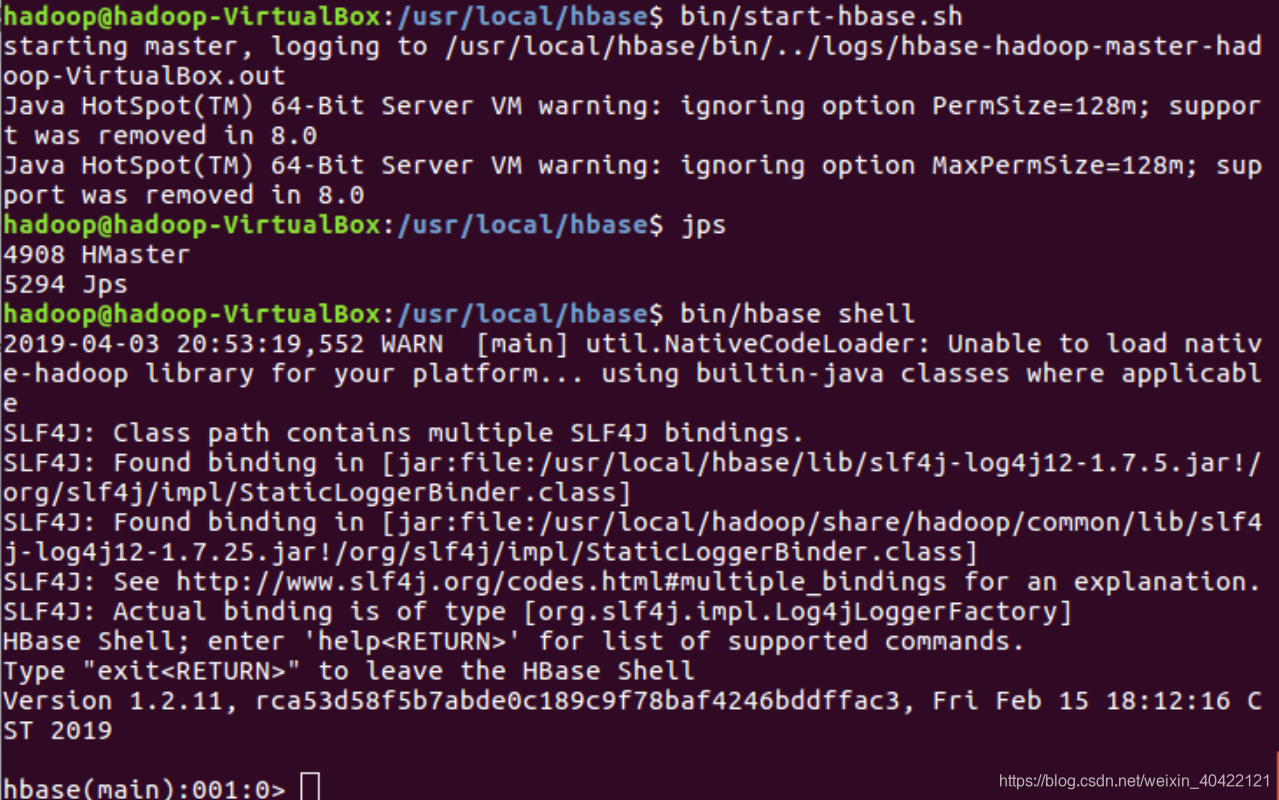
采用如下命令启动服务、查看进程和启动客户端
cd /usr/local/hbase
bin/start-hbase.sh
jps
bin/hbase shell
下面为配置伪分布模式的指南,配置分布模式方法请查阅官方文档
配置hbase-env.sh
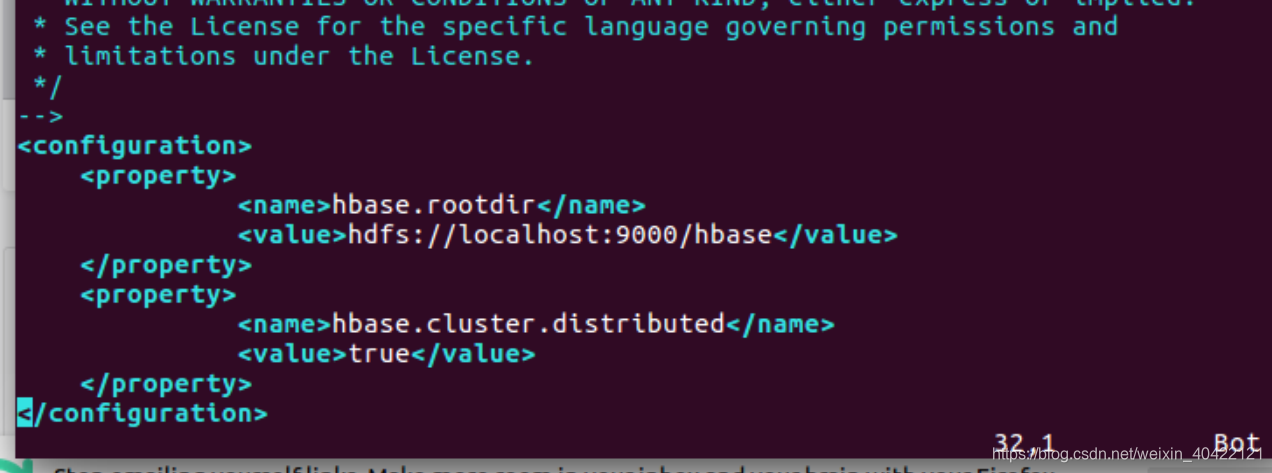
start-dfs.sh
cd /usr/local/hbase/bin
start-hbase-sh
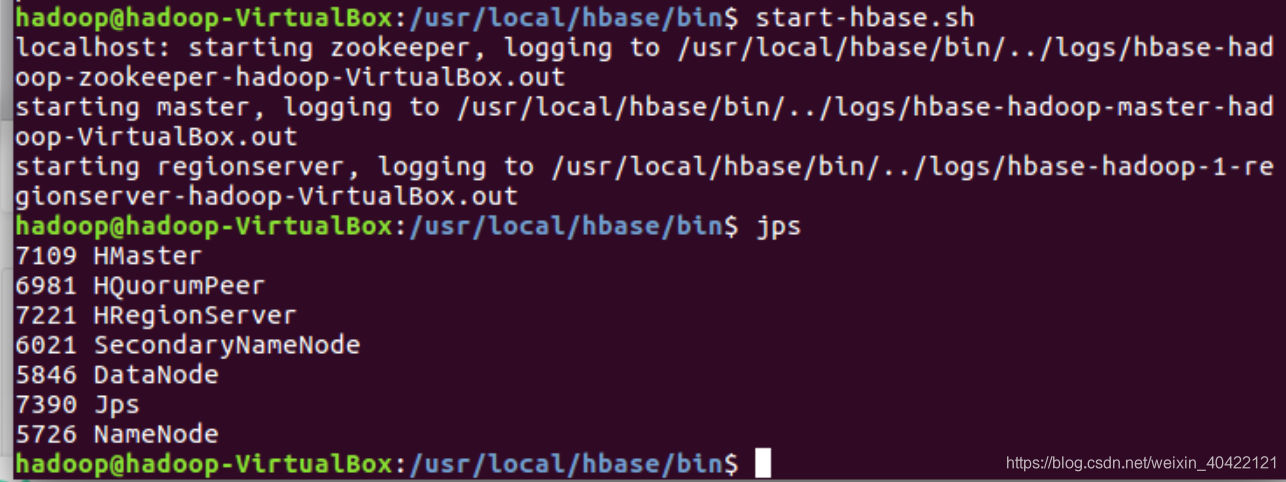
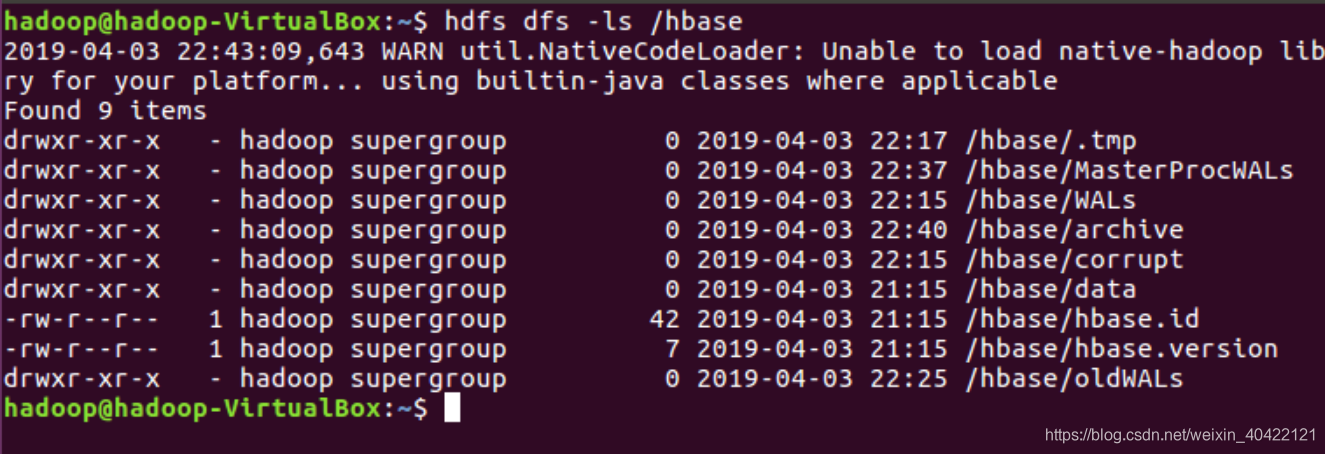
查看DFS中Hbase 目录,自动创建
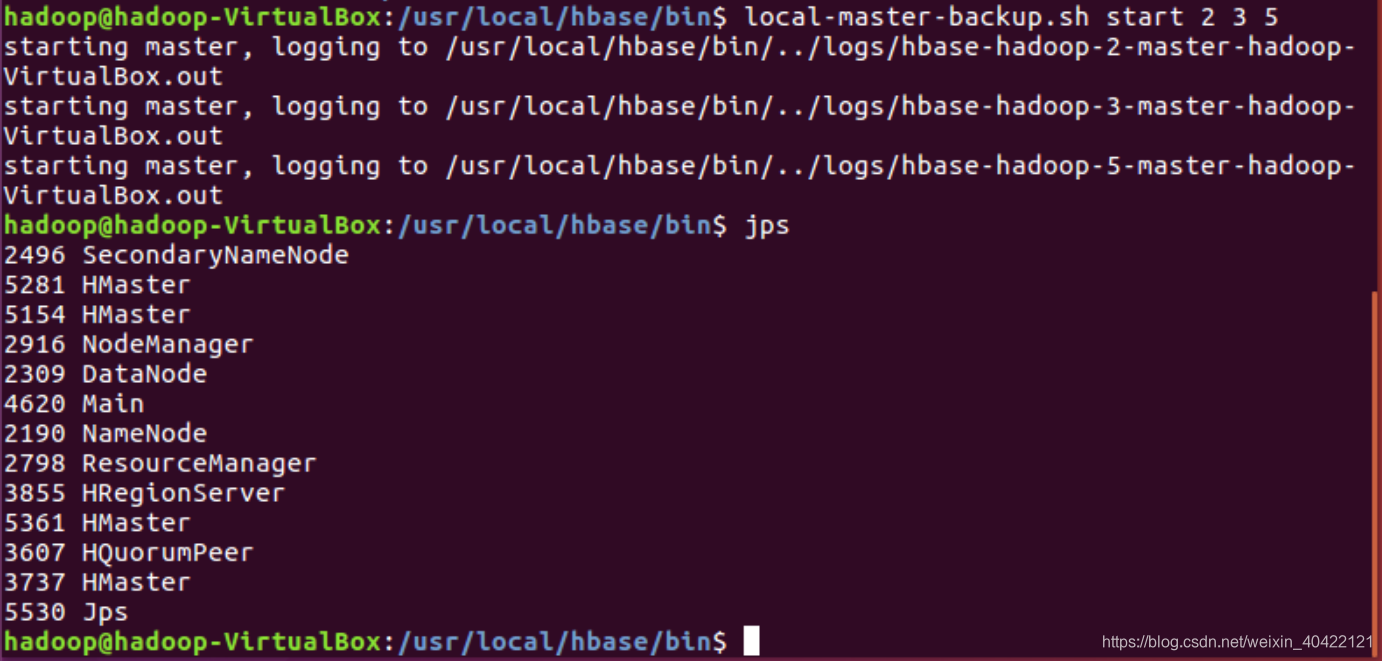
Start a backup HBase Master (HMaster) server.(仅仅为了测试和学习,生产环境不会在一台机器上启动备份master)
HMaster服务器控制 HBase集群. 你可以启动最多9个后备HMaster。
用 localmaster-backup.sh启动. 为每个后背HMaster加一个16000端口之上的偏移量。 启动后可以查看结果。
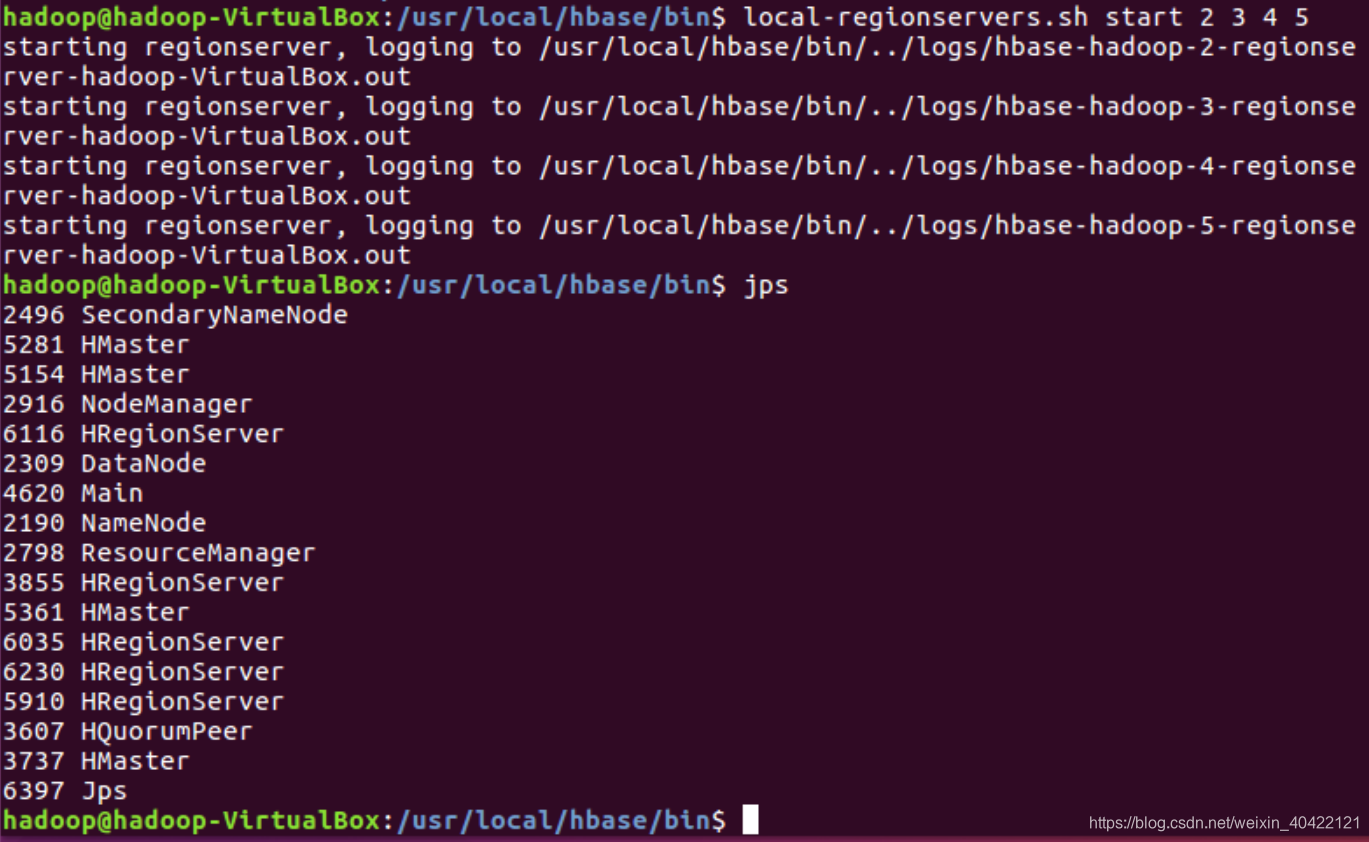
启动和停止附加区域服务器RegionServers,命令示例和结果如下图。
进入交互界面
hbase shell
进行一些基本数据库操作
创建表
使用create命令创建一个新表.你必须规定表名和列族名

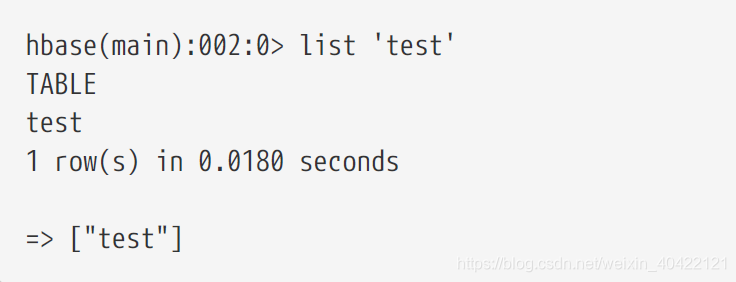
显示表信息
使用list 命令可以显示表信息
使用 describe 命令显示表的详细信息

向表中加入数据.
使用 put 命令

扫描表.
使用scan 命令扫描整个表取得数据 。

取一行数据,使用get指令.

修改表模式,使用alter命令,如修改存储版本数
hbase(main):007:0>disable ’test’
hbase(main):007:0>alter ’test’, NAME=>’cf’,VERSIONS=>5
hbase(main):007:0>enable ’test’
其他命令 disable table, drop table,enable table 等。
思考题:
1 请问伪分布和分布式的含义有何不同?就本实验,你是如何理解在一台计算机上做到“伪分布”的?
2 在1.2小节进行安装SSH并设置SSH无密码登陆,请问这个安装的目的是什么?
3 如果继续向Hbase的test表中put行键为”row1”,值为其它字符串的数据,put ‘test’ ,’row1’, ‘cf:a’, ‘value6’,会发生什么?如果采用语句get ‘test’, ‘row1’, {COLUMN=>’cf:a’, VERSIONS=>3} 进行查询,分析你得到的结果。put与关系数据库的插入有何不同?
附录1
Hadoop出现错误:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方案:
在文件hadoop-env.sh中增加:
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
